
2024 Data Orchestration Pricing Deep Dive
How pricing Airflow, Prefect, Dagster, Mage and Orchestra all compare


⭐️ Check out our Substack and our internal blog to see a better way to Orchestrate and manage data pipelines⭐️
Introduction
As Data Teams, pricing is unfortunately one of those conversations we need to have all too frequently.
If only every market for software was like the data cloud! Choosing between AWS, GCP and Azure is often an easy one — either determined solely by personal preference, or someone else’s.
This is less evident in Data, where a single vendor for all our needs is a distant reality (unless you want to spend £500k on Foundry); having many suppliers is a harsh reality of life.
Therefore, something that’s really important is understanding how to stitch together a “modular” data stack — or the degree of interoperability inherent in your stack.
The interesting thing about Data (being an oft-both streaming and batch-based discipline) is that orchestration is necessary.
Furthermore, observability/visibility/metadata is also important (the software analogy is having a centralised place for all your logs via e.g. Datadog). This means often an orchestration tool is a fundamental part of a data pipeline or Modern Data Stack — one oft-overlooked…
In this article, we’ll dive into Orchestration Tool pricing. We’ll discuss what it should look like, what it does look like for difference vendors, and see how Orchestra compares.
At the end of the article, you should have a good sense for the cost of adding end-to-end orchestration and observability to your data pipelines.
What should orchestration pricing look like?
Data Orchestration or Workflow Orchestration is a topic that’s often misunderstood.
Orchestrators can execute python code, but increasingly we prefer to execute that code somewhere else that’s more efficient, like a Virtual Machine or using Elastic Compute Capacity.
This is detrimental to pricing of cloud orchestration tools. It means pricing has to be usage-based (which is a mark-up on cloud costs we already manage). Furthermore, Kubernetes is used under-the-hood, which is costlier to maintain for vendors and passed on to end users needlessly.
Orchestration logic is very simple. Triggering and monitoring Tasks in cloud services are lightweight operations. Interestingly, the fetching of data from data pipelines is also a relatively cheap operation when done properly — the analogy here is that streaming data incrementally is cheaper than say, running a batch refreshes every day (Observability tools’ approach to gathering metadata).
This means the pricing of an Orchestration tool should probably be fixed. The variable component should be small, at least.
By adopting this pattern, data teams are also free to execute their python code where they want. For example, engineers may prefer to execute long-running, low-compute webscraping jobs on a small virtual machine, and more spiky workloads on a serverless framework.
This leads to two advantages
Engineers save money directly executing code instead of passing it to a vendor
Orchestration logic is separate from business logic, which makes managing and scaling Continuous Integration and Delivery easier
Orchestra pricing
At Orchestra, we try to ensure the amount our customers pay is highly correlated with the value they receive from our Product. This doesn’t translate directly to usage-based pricing for the reasons given above.
We find data teams contributing more to organisations typically have more, and more complicated, Data and AI Products. Therefore, depending on how many Pipelines and Tasks you have, Orchestra offers fixed pricing for a given number of Pipelines and Tasks.
There is also a free tier which is perfect for small Data-teams with a low-number of pipeliens.
This gives users certainty around how much they pay every year, and freedom to increase and grow without fear of incurring greater costs.
There are other benefits baked into our pricing which you might not be aware of.
[1] Run Python code most efficiently — 5% Compute saved
By using Orchestra, you can run custom-code where it runs most reliably and efficiently instead of all on one big cluster designed to do many things. This saves money, perhaps up to 5% of the relevant cloud compute.
[2] Erase managed Infrastructure and streamline CI/CD — 10–50% time saved
Platform engineers spend between 10–50% of their time maintaining the infrastructure required to run OSS workflow orchestration products. This is a cost of $15k — $75k per platform engineer at $150,000 per year (applies only to self-hosted implementation)
[3] Observability — hundreds of hours saved debugging
By keeping metadata and collecting additional metadata throughout the Orchestration Process, using Orchestra eliminates the need for an additional system that gives engineers visibility into the entire data stack
[4] Build faster and prioritise — move up to 25% faster
By using GUI-driven, Code-first declarative pipelines, the process of building a data pipeline is sped up by up to 25% based on anecdotal evidence.
In total, using Orchestra can save a Data Team of 4 with a Platform Engineer anywhere from a few thousand dollars to >$100k, while also increasing the efficiency and reliability of the development process.
We don’t offer a “start-up” plan at the moment, but if we did it would probably be self-service, anywhere from $1k — $20k p.a. Enterprise starts at about $20k p.a., but bear in mind you get a lot in addition to core orchestration.
Airflow / Prefect / Dagster / Mage (Open-source, self-managed)
In this scenario, Data Engineers write python code using Airflow / Prefect / Dagster or Mage and deploy this code onto a Kubernetes cluster or a serverless compute pool to run.
Data Engineers make use of open-source components like dbt-core, perhaps data load tool (“dlt”) or pyairbyte. The Kubernetes cluster requires maintenance from someone with platform engineering expertise and Continuous Integration for workflow orchestration tool repositories is enforced (and painful).
The cloud cost of running this on Kubernetes or sometimes even ECS is low — as low as it can be, since you’re going straight to source (AWS). Perhaps between $2,000 to $10,000 a year for most workloads where you ingest between a few hundred thousand to tens of millions of rows per day (mix of structured and semi-structured).
However, the technical skill required to deploy this is high. It means a platform engineer will need to:
Structure the repository
Enforce Continuous Integration and Delivery on the repository
Set up a staging and production environment
Write code or utilise packages to build Tasks to new integrations
Set up customisable alerting systems
Best practices are enforced…
Assume the time spent doing this ranges from 10%-30% (on an ongoing basis) to 50% when getting set-up. Then for a single platform engineer, this could be a $75k one-off set-up investment plus $15k — $45k on an ongoing basis assuming a $150k salary.
Cloud costs are $2k — $10k in this basic example.
Compute cost is low, but time spent building and maintaining is high.
Managed Airflow pricing: MWAA, Cloud Composer and Astronomer
Managed Airflow is very similar to the above, but you’re paying someone else for the Airflow cluster. This isn’t the same as paying them for the AWS cluster and using it yourself, but because the pricing for MWAA is completely different to other AWS Services, it’s quite hard to do a like-for-like comparison.
Anecdotally, the equivalent mark-up in compute is anywhere from 10–30% based on customer interviews.
There are a couple of feature differences too.
Easier CI
Instead of setting up CI on an Airflow Repository yourself, you get easier deployment. MWAA’s homepage literally lists the main benefit as “Easy Airflow Deployment”:

You can see examples of that for Astronomer, MWAA and Cloud Composer all in these links. However, you’re not fully out of the woods — Continuous Integration can still be challenging.
For example, with Astronomer’s deployment process, you have to run CI on your entire repo (not just for one specific DAG). With lots of DAGs, CI can become tricky and slow.
From an access perspective, keeping all your code in a single repository can be disadvantageous where segregating the resources different teams have access to is desirable (e.g. Data engineers vs. Analysts)
Managed Cluster Maintenance
Under a managed service, the idea is to simply own the repository and after merging a pull request, the managed service handles the rest.
This means you don’t spend any time maintaining the cluster, with some caveats.
One caveat is that Cloud Composer and MWAA also still require a decent amount of custom configuration. Instead of managing your own cluster, you’re still managing a “managed” cluster.
MWAA and Composer both require configurations (just take a look at these MWAA Pricing examples and you’ll see why):
MWAA Pricing examples (source)
If you are operating a medium Managed Workflows environment with Apache Airflow version 2.0.2 in the US East (N. Virginia) region where your variable demand requires 10 workers simultaneously for 2 hours a day, you require a total of 3 schedulers to manage your workflow definitions, and retain 40 GB of data (approximately 200 daily workflows, each with 20 tasks, stored for 6 months), you would pay the following for the month:
Environment charge
Instance usage (in hours) = 31 days x 24 hrs/day = 744 hours
x $0.74 (price per hour for a medium environment in the US East (N. Virginia) region)
= $ 550.56
Worker charge
Instance usage (in hours) = 31 days x 2 hrs/day x 9 additional instances (10 less 1 included with environment) = 558 hours
x $0.11 (price per hour for a medium worker in the US East (N. Virginia) region)
= $61.38
Scheduler charge
Instance usage (in hours) = 31 days x 24 hrs/day x 1 additional instances (3 less 2 included with environment) = 744 hours
x $0.11 (price per hour for a medium scheduler in the US East (N. Virginia) region)
= $81.84
Meta database charge
40 GB or storage x $0.10 GB-month = $4.00
Total charge = $697.78
If you are operating a small Managed Workflows environment with Apache Airflow version 1.10.12 in the US East (N. Virginia) region where each day your system spikes to 50 concurrent workers for an hour, with typical data retention, you would pay the following for the month:
Environment charge
Instance usage (in hours) = 31 days x 24 hrs/day = 744 hours
x $0.49 (price per hour for a small environment in the US East (N. Virginia) region)
= $364.56
Worker charge
Instance usage (in hours) = 31 days x 1 hrs/day x 49 additional instances (50 less 1 included with environment) = 1519 hours
x $0.055 (price per hour for a small worker in the US East (N. Virginia) region)
= $83.55
Meta database charge
10 GB or storage x $0.10 GB-month = $1.00
Total charge = $449.11
Another is that these services force you to run additional services and have a minimum cluster size. For example, Cloud Composer requires you to have an Airflow DAG running that simply checks the status of the system that runs every 5 minutes. Like-for-like, the same computation on a self-managed Airflow cluster is therefore higher under managed Airflow.
When should you go with managed Airflow?
You’re paying a mark-up on your compute in return for your time.
This means if you’re time poor (small team) and low-compute (Not much data) this could be a good choice.
However there are also minimum spends due to minimum cluster sizes of per year. Many Orchestration tools offer free cloud-based services which are a better fit.
For example, the smallest MWAA instance is about 50 cents an hour. This needs to be on all the time, so $12 a day roughly. That’s already almost $5k a year.
If you’re compute-heavy, managed Airflow is a poor choice. Suppose you spend $300,000 on your Airflow Kubernetes cluster. You’ll pay AWS about anywhere from 10–30% mark-up on this compute— you could hire a platform engineer to do the same thing.
If you’re an organisation that’s highly federated with lots of different Airflow clusters that need to be managed by multiple people, hiring a single platform engineer may not apply. Therefore you may choose managed Airflow.
This point is interesting, because depending on the organisation, the trade-off between platform engineering time and computational resources is not the same for everyone. We’ve seen single person data teams using MWAA all the way up to JPMorgan using Astronomer. You need to decide based on your personal situation, but the key question is: does it make sense for us to manage this ourselves?
Pricing
Pricing is actually too complicated to discuss in this article. I always thought it was straightforward compute-time, but there are differences across MWAA, Composer and Astronomer and they’re all extremely complicated.
One thing is for certain — if you have lots of stuff to orchestrate or you simply want to know your bill in advance, this service might not be the best fit.
Read more about MWAA here
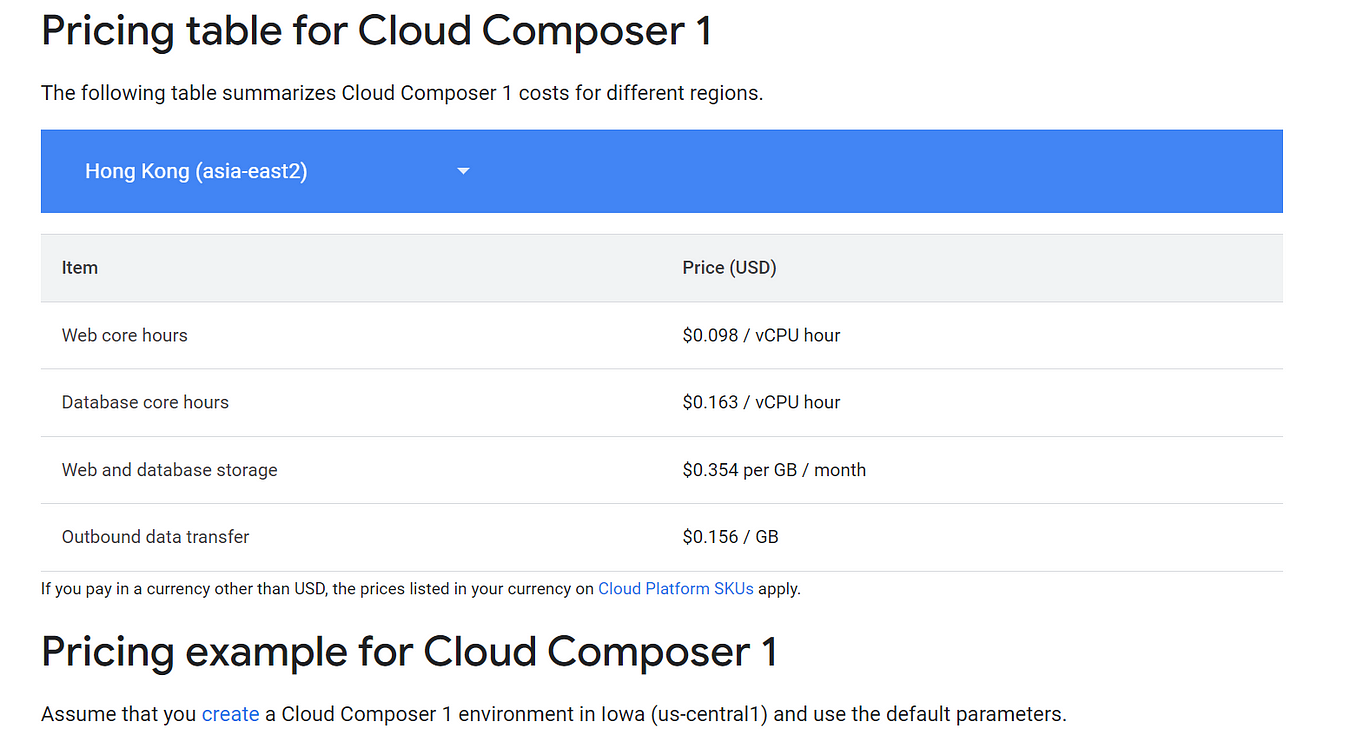
Read more about Composer here
Prefect Cloud pricing
Prefect has an interesting Cloud Pricing model which is user-based. This is because you still need to host your own “Prefect runners” which are running the code in your infrastructure. Therefore the model isn’t pure SAAS — it’s (in their own words) “hybrid”.
The cloud offering is therefore much more marginal compared to self-hosting Prefect core, because you still need to maintain the runners (which are the trickier bits to scale).
The case is stronger if you’re an enterprise, because enterprise features such as RBAC, Support and multiple Workspaces are only available in the enterprise tier.
Based on this webpage at the time of writing, Prefect Cloud has a Free Tier (where you still need to maintain your own Prefect runners.
You can pay an additional $450 a month or c.$5k a year for additional features such as Service Accounts and RBAC.
You can pay “Enterprise Pricing” which I imagine is anything from $10k above for SSO, Support, Custom API Limits, and so on.

However, note you still likely will require a reasonable platform investment. A personal note — I have heard great things about folks using Prefect who work in environments where they have a lot of processes that need to be triggered that aren’t in the cloud but do have access to an internet connection — think on-premise or IoT devices. In this instances, these highly technical teams normally self-host Prefect Server and deploy Prefect runners on owned infrastructure, which works very well.
Dagster Cloud pricing
Dagster Cloud is a fully-managed SAAS offering a credit-based model.
Essentially, every time you run a “materialisation” or an “operation” you consume a credit. In English — what this means is every time you run a task or basically render a new node in your lineage graph, you consume a credit.
You can also ask Dagster to specify what infrastructure to run a task on. In this case, if you ask Dagster to execute in a serverless environment, you’ll incur usage based pricing at $0.0005 per Serverless minute. I’m not sure what a serverless minute entails, but the AWS lambda cost checks out at twice the serverless minute cost (see here), so there must be some other stuff going on here.
Solo and Starter Plans come out at $120 and $1200 a year respectively, coming with 7,500 and 30,000 credits per month respectively.
That’s 250 and 1,000 operations per day.
So for example, if you had an 80 model dbt project with 160 tests, you could run this on a daily cadence in Dagster for $120 a year.
Additional credits are charged at 4 cents and 3 cents a Task each. That is quite a lot. If you wanted to run an extra 100 dbt models, it’ll cost you at least $4.
You also pay Dagster for the time take to execute your code, directly. So there is a pure usage-based component. That’s related to run-time. The longer your code is running, the more you’re paying Dagster for. To the point I made earlier around the usage-based component being small for orchestration, the more you use the less this becomes true under a “ratchet” plan like this.

Also note — anything with more than a few users requires a “Pro” plan.
Mage Cloud pricing
As of writing in March-24, Mage does not support a managed cloud offering.
Summary
In summary, we’ve looked at self-hosted OSS Workflow orchestration, managed Airflow, Prefect, Dagster and Mage.
We’ve seen that whether or not self-hosting makes sense to you is really not a uniform or linear decision. If having a platform team maintain a cluster at scale is economical vs. your compute, you should definitely be self-hosting.
If not, then managed options are a great way to go. Managed Airflow with high compute is expensive, but options like Dagster also have usage-based pricing models that essentially mark-up your compute. Prefect is an interesting option that sits in the middle (between this and self-hosted) due to the “hybrid” approach.
Orchestra has a fixed pricing model, where the amount is loosely correlated to how many Pipelines/Products and Tasks you want to run (and how frequently). This is because under a modular architecture, the compute proportion of what we do is extremely low (you are already paying heavy compute elsewhere).
In Part 2 of Orchestration pricing, we’ll dive into a few different scenarios that compare the options like-for-like. It’s inherently difficult to compare platforms since the use-cases driving the need for orchestration and observability are so different across data teams. We’ll compare on a cost-basis (comparing what $10k, $20k and $100k will get you).
Disclaimer
Factually, this article is unbiased but the article itself is written with some degree of bias — After all, Orchestra can replace or augment lots of the features offered by existing workflow orchestration products.
Indeed, Airflow has been around since 2014 and has never had more users. However, as data engineers and architects our mission at Orchestra is to make data teams’ lives easier, more enjoyable.
We want to free up time for driving adoption of data for decision-making and now, accelerating usage of generative AI products. We want to eradicate the need for a platform engineering team to do lots of heavy-lifting.
That’s why many of our larger users leverage existing integrations to workflow orchestration tools such as Prefect or Airflow. These integrations allow teams to make use of the awesome observability and visibility features in the platform while retaining parts of the stack for what they’re good at.
We hope you enjoyed this article and if there’s anything missing please feel free to let us know in the comments and we can amend/update the article as required.