


A generational data divide?
one of the many reasons the data market is irrational

Noticed something interesting in data recently
We all know the data market is massively irrational - companies will pay consultants millions but never buy software. Some people build at all costs, some people spend way too much and buy everything, and massively over engineer
Generally organisations seem quite bad at making the most of data initiatives, there is just like a lot of wildly irrational stuff that goes on
There is one thing I’ve seen consistently. The only people building anything are the ones that are < 35 or that are stuck with it.
I am probably guilty of this myself. I am under 35 and enjoy building these things so much I set-up a company to do it!
I’ve been speaking to a chap I actually almost hired as a DE trying to get him to use Orchestra. Back when this conversation started maybe like 3 years ago we basically had no product so he went with Prefect.
Anyway fast-forward 3 years (and this is a direct quote from him) “We probably sank about £150k between two people in our time into making Prefect usable. I am definitely going to try something more specialised [Orchestra] in my next role”.
Like - everyone also just hates Airflow apart from their PMC members. Everyone’s sick of it, everyone’s over it.
This is consistent with the “Rise of the Data Engineer” a few years ago. Everyone is trying to become data engineers and they do that by building stuff. Now, people are changing jobs and realising what enterprise data architects have known for the last 20 years.
The writing is on the wall for many companies that have built cool tech but are fundamentally not delivering on Data, let alone AI. Having an easy but powerful way to build and monitor Data and AI Workflows is criminally underrated by the inexperienced.
The best Data Engineers and Analysts are not the proverbial Ostrich with it’s head stuck down a hole, obsessing over the tiniest details about engineering but those that can see above the parapet and understand why exactly they are in the job in the first place.

5 Signs it’s time to start monitoring your data pipelines
Everyone says you should do it, but you don’t.
After all, what value is there in running and maintaining a glorified cron scheduler, anyway?
Turns out, there’s a lot of value in it. It’s why 100% of Fortune 500 companies all have some form of cron scheduler that gets maintained, be it ctrl-m, SSIS, or Airflow.
Here are 5 signs it’s time to get serious with your Data and AI Workflows
You’ve had a big system-wide outage recently that took ages to debug
A classic.
“My numbers don’t look right!!”
The Data Team, on the hook, again.
But it wasn’t their fault.
No actually what happened was the data pipelines ran fine. But two other things happened. There was a delay in some of the data from a third party provider — they had a system outage.
In tandem, the infra team decided to delete some resources in AWS which meant the jobs simply didn’t run.
Everything downstream was fine.
This is a classic problem that gets solved by having an overarching control plane that orchestrates the different part of the pipelines. Think about it
You don’t need to worry about if the jobs happened, as long as you know the orchestrator is healthy
You can run data quality checks to let you know if data is missing
You can alert people in real-time, and avoid manual triage and annoying requests into the data team that disrupt and cause you to context switch
You can gracefully recover from pipelines by adding delays and perhaps a sensor to your pipeline, so it can run even if data is delayed
The alternative?
Constant Firefighting
Loss of Trust
Central team have too many requests
If you run a central team and you’re more than 10 people, it may be time to decentralise a bit. You should do this by enabling a Hub and Spoke model.
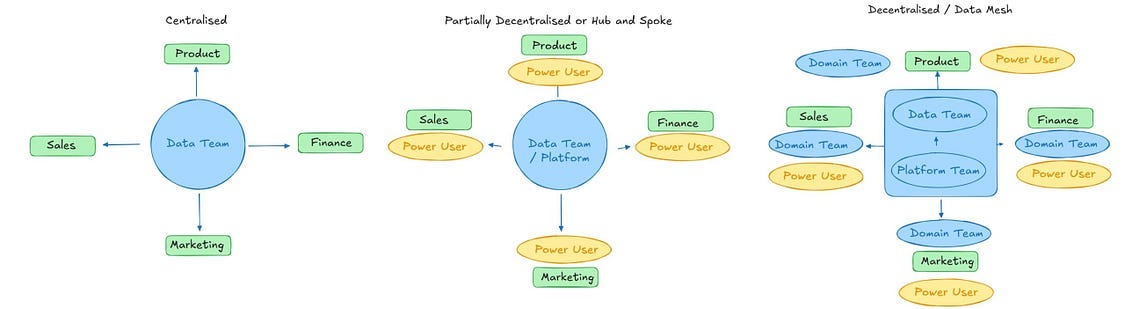
This means democratising your workflows. It means it’s time to get folks to start building their own pipelines so you can focus on building the core infrastructure.
People can’t do that unless they have an easy way to schedule and monitor jobs. Enter the Orchestrator.
Without this:
Constant requests to the central team for small, annoying changes
Technical dependency on the data team (“Can you just run these numbers in Snowflake for me please”)
Limits on scaling Data and AI
You're spending loads of time knitting together point solutions
Using a single tool for every part of the workflow is a gorgeous pattern. It makes architecture simple and limits the need for integration.
But what happens when your ingestion tool doesn’t support a connector? What happens if you need to write some python? Or do some streaming?
Suddenly you’re integrating different things, and it’s getting a bit messy. Some Lambdas here, a Fivetran job there, dbt artifacts saved to storage accounts in god knows where!
A modern orchestrator should have these integrations out the box, so you can focus on driving the business forward with good, clean, data.
Your boss wants you to do AI
There is no AI without data.
Everyone wants to do AI, but we data folks know that data pipelines are the bedrock.
80% of leaders want the Data Team to implement AI. Pretty tough given the backlog — can I have some more headcount please?
It’s actually even more tricky because our new Data Engineer is going to need to speak to Becky in Finance who’s got a complicated end of month budget-to-contract she wants reconciling, and it’ll take them a few weeks to work out what’s going on there, let alone onboard to our complex web of interdependent pieces of cloud infrastructure.
Better make that two more headcount!
The foundation of AI workflows is Data workflows. And there is no hope of making those robust without an easy way to build, run, and monitor workflows.
We data folks are smart — we know that “AI Workflows” (whatever that means) are basically 90% data work we’re doing anyway.
A modern, intuitive orchestrator is something Becky can use herself, without having to get the platform to implement it themselves. This is almost a “Shift Right” approach — putting the means to drive automation with AI in the hands of those who need it.
And a way to avoid having to learn all this random ugly logic.
Huge model sprawl and duplication
Perhaps you’re a bit further down the road to decentralisation and analysts are already running lots of nice dbt code in a cloud-native dbt scheduler.
However, it’s all gone a bit awry. A quick search in the KPIs table for revenue yields too many metrics; revenue , revenue_for_forecast , r4wk_revenue and so on.
This happens because a crucial step is missing — analysts who need to do something don’t know what’s going on.
Lacking an easy way to see what Pipelines and what Data Products are already in-play, they decide it’s easier to just start from scratch and get the job done.
Another thing that would have been helpful is end-to-end lineage. This would at least give an idea of where the relevant tables containing revenue should be (for example, something that’s dependent on the customers table. Surely we have revenue by customer?).
A modern orchestration platform populates this information automatically, so there’s no need to spend a lot of time integrating standalone catalogs or data lineage solutions.
Empowering analysts to schedule jobs the same way as the platform team is a wonderful thing.
Analysts upskill, they take ownership, and they write better, less duplicative code because they actually know what is going on.
But the best part is the platform team or power users suddenly take on this pastoral role.
As the last line of defence against wanton PRs, it’s easy for there to be visibility and guardrails against PRs that simply duplicate code.
Yes — it is a bit more of a burden to review PRs. But isn’t this the right way to enable self-service analytics?
Conclusion: necessity
I wrote a while back about why Business Teams need to recalibrate.
It’s only a problem if someone notices? Why Data Teams need to recalibrate
You miss 100% of the shots you don’t take
It’s not good enough to get stuff right 99% of the time, if the 1% of the time pipelines break is when people need the Data.
This is probably why most people don’t trust AI right now. If they don’t trust the Data, how will they trust AI?
Ignoring orchestration is like building a house without foundations. Workflows and monitoring are the very bedrock of Data and AI systems. There are many investments that aren’t worth it from day 1, but orchestration is definitely not one of them.
Learn more about Orchestra
Orchestra is the only platform that is designed to help companies scale Data and AI workflows from the Data Team and beyond. To learn more, check-out the resources below.
📚 Docs
📊 Demo