


A simple, effective way to minimise cognitive overload in Data Engineering
Who knew Role-Based access Control could look so good


Foreword
Some of the biggest pains we see facing data engineers and analytics engineers is that they just have too much to do.
However, they struggle to cede control due to the high-degree of technical competency required to not screw stuff up - you don’t want to given the Airflow reins to Jim in marketing - that would be a massive dumpster fire.
So what can we do? How can you shift left? How can you help people do self-serve?
One way is to give people tools with guardrails set-up. Historically, the process of gathering metadata and end-to-end orchestration has been the sort of “last hurdle” for non-technical person; the area they could never hope to understand, even with an exceptional knowledge of python.
At Orchestra, we are now trying to give data teams the power to help others with end-to-end orchestration and monitoring. Role-based access control is very powerful here. You can control levels of access (e.g. Admin vs. Maintainer) across different resources (e.g. Pipelines, Data Products and Integrations). This means that as long as someone knows SQL, you can essentially give them an entire data platform in the knowledge they won’t A) Fuck anything up and B) you won’t have gaps in your monitoring.
Sounds cool, doesn’t it? Try it here or read more below to see how we’re thinking about Role-Based Access Control in the context of Self-Serve and “Shift Left”.
Try Orchestra free, here.
Introduction
Data Engineering Teams frequently get overwhelmed. Unsurprisingly, the pressures of building a data platform, troubleshooting errors, advocating internally and using data to drive growth can be a lot for people to take on.
One of the most promising ideas that’s emerged as a solution to this problem is the idea of “Shift Left”. It is essentially the idea of making those that produce data take on more responsibility for its quality, however you can take this further.
For example, we recently worked with one Data Team to give them visibility over multiple dbt repositories. Rather than maintain a monolithic dbt repo, they moved basic dbt model code to the producers of data, thereby significantly reducing the amount of modelling they needed to do.
Before
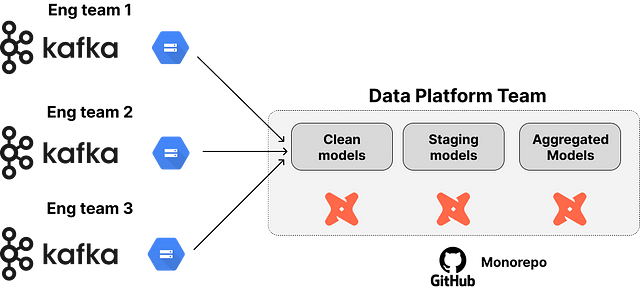
After

Critical to this pattern was ensuring governance and access control, while not compromising on the visibility the central data platform team had.
How could they ensure that orchestration, lineage, and visibility was retained across multiple environments and multiple teams? How could they ensure teams weren’t overloaded with unnecessary data and alerts? How could they “Shift Right” and help business stakeholders take control of the same thing?
Data Death Cycle: The Silo Trap
How to avoid common self-service pitfalls
This is what we’ll explore in this article
The answer to our problems — building platforms not pipelines
The other side of the coin to shifting left is shifting right.
The Silo Trap is real. It is very very painful to have the data platform team bottlenecking business stakeholders like marketing, finance etc. who have the business knowledge but not the technical knowledge to self-serve.
These users are even more scary. Can you imagine giving Dale in marketing access to your Airflow instance? Can you imagine how impressed and terrified Dale would be by the monolithic dag structure?
No no..Dale needs a lot less than this.
But the point is — we need to empower people to take on the level of ownership that’s right for them. This is where Orchestra comes in.
Centralised Control
Orchestra is a declarative code-based, GUI-driven Orchestration and Monitoring Platform. It is the backbone of a data platform. It handles the aggregation of metadata, end-to-end orchestration, and gives teams visibility into their data pipelines.
Instead of saying to a team “Hey we will manage Airflow — you just control the code” or worse, “Hey you should use Airflow for this. Make sure you remember to use these libraries we made for and install datahub, good luck”, they can be given an environment in Orchestra to do as they please.
The best part is that Orchestra has granular role-based access control. This means that different teams get access to what they need, and without even thinking data platform teams get complete visibiilty, guardrails, and control from day 1.
Reducing cognitive Overload with Role-based access control
Let’s take a look at the state of play. Imagine you’re building a data platform and you’re trying to empower people to build their own data pipelines, who may not be as technical as you.
First thing you’re going to do is say “commit code in this way, I’ll look after running everything for you”. Problem is, when you take away this core piece of ownership, is that when shit hits the fan this is what your stakeholder sees:

Congratulations. You’re now officially a bottleneck and have made the same mistake as 1000s of data engineers before you.
Let’s see what else this could be like.
Creating Groups, Roles and Users in Orchestra
I have a demo account I use. I do a lot of demos for Orchestra. This could be a lot for someone to get a hold of!:
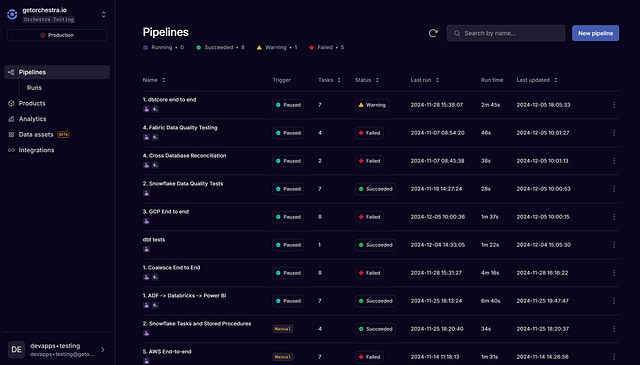
Fortunately, we can create a group area for them.

By default, Orchestra gives you groups that essentially have similar sets of permissions for all objects. For example, an Account Viewer can view pretty much everything. A Maintainer can edit pretty much everything.
However we want to leverage this feature to make things a bit more manageable.
So what we’re going to do is imagine that there’s a set of users that only want to use Orchestra for demoing pipelines on Azure. This is similar to a Data Platform Team giving a [marketing] or [finance] team access to specific things in Orchestra.
Firstly, create a group and add someone to it. We’re going to add some granular permissions:

That’s better! Much more manageable. We can do a similar thing for integrations:

And Integrations:
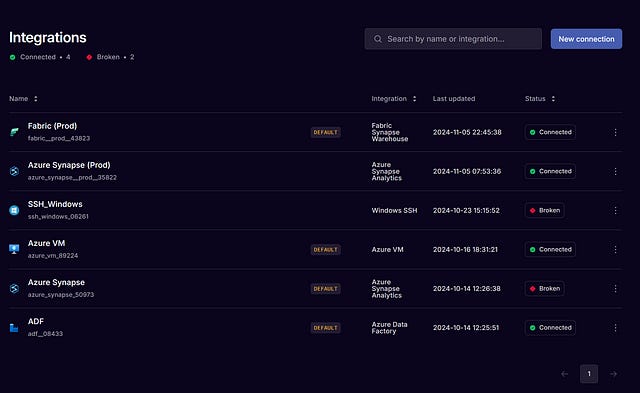
And suddenly things are much more manageable. Not only this, but as a data platform manager I’ve been able to effectively hand off the management of some of these pipelines to an individual, without giving them access to the entire data control plane / airflow UI.
The other benefit is ease of use — anybody can leverage Orchestra. There is no need to have another technical team member here (although a technical team member could be here) which enables you to shift left or self-serve/ shift right.
Conclusion — shift everywhere
I’ve written before that the barrier to building an effective and scalable data platform is lower than ever before.
Platform Engineer Not Required: why the greatest barrier to Analytics is non-technical
Building a Great Data Team requires a clear Vision — rockstars can be your enemy
The last great hurdle of data platform engineers everywhere is figuring out how to automate as much of the ancilliary services around data pipelines; things like gathering metadata, scheduling alerts, error-handling, centralisation of metadata, and so on.
With this in hand, not only can organisations shift left, thereby minimising the ingestion work Data Platform Teams need to do, but they can also continue to enable self-serve or shift right to allow business users, with operational context, to self-serve data pipelines themselves within guardails.
For organisations that either do not have access to these platform engineers, do not have the vast budgets to hire them, do not want to wait 6 months to hire them, or simply do not wish to spend money, wait, and then risk a botched implementation, then software solutions like Orchestra exist.
Otherwise, we’ll again be hoping for more automation, more shifting, and less cognitive overload in 2025 🎆
Learn more about Orchestra
The best way to see how Orchestra helps data teams spend less time dealing with issues and more time building is to check out our demo.
Or — watch one of our latest videos below.
Orchestra is a unified control plane for Data and AI Operations.
We help Data Teams spend less time maintaining infrastructure, make them proactive instead of reactive, and ultimately win trust in data and AI from the Business
We do this by consolidating Orchestration with monitoring, data quality testing, and data discovery. You don’t need an observability, lineage, catalog etc. with Orchestra.
Check out