


Data Lakes vs. Data Warehouses: the definitive guide for 2024 recapped
The fact this has become so swiftly out of date means it's definitely time for the 2025 edition


Data Lakes: then and now
We wrote the guide below at the start of 2024 and since then, things have changed a lot. The providers of compute for processing data have become the key pinch-point in the race for data domination. Data platforms like Databricks and Snowflake have become so indespinsable that every company, from an early-stage start-up to Fortune 500s leverage them in some form (many companies even have multiple).
There are four big themes that were not addressed in the 2024 review.
Consolidation
Continuing around this idea of “Pinch-points” - providers of data lake and warehouse software in the cloud are following in the footsteps of Oracle and branching out into other areas.
This is leading to consolidation in the data space.
It is now impossible to simply purchase a data warehouse. Modern providers of data warehouse technology will typically offer a suite of other tools such as ELT connectors, dashboarding services, the ability to run managed spark, basic orchestration, in-built data quality monitoring, alerting, and even, dare we say it - tools focussed around machine learning and AI.
This means that asking the question “Should we use a data warehouse or data lake” also entails the question “ What other services does X supplier provide?” Where in-built tools suffice, they can go along way.
The rise of Iceberg and open table formats
A data warehouse traditionally suffered from one major operational and architectural flaw.
While businesses ran their operations on non-OLAP data stores, the warehouse was an OLAP data store situated somewhere else. Not only does this mean that data is segregated, leading to data silos (and missed financial opportunities to join this data together and make the most of it) - it also forced ingress and egress.
Ingress and Egress, or the practice of moving data to your warehouse and from your warehouse is not only complicated, but costly. A major flaw for data warehouses.
The “lake” paradigm leverages object storage like S3, ADLS or GCS combined with more analytical-friendly file formats like .parquet to get around this. Operational databases and object storage have always been relatively well-integrated, object storage is format agnostic, and generally cheaper.
The rise of iceberg and open table formats has meant that the ideal of using object storage as the storage layer for analytical processing is closer to now than ever before. As a result, warehouses like Snowflake and BigQuery, and Fabric which is built on Delta Lake, now aim to offer a warehouse-like experience with your data staying where it was to begin - in your object store.
With both providers of “lakehouse” and traditional “warehouse” technology increasingly broadening support for analytical operations on data in object stores, again, the lines between using a data lake or proprietary warehouse are now blurring once again.
AI
It is telling that Snowflake has rebranded as the “Data and AI Cloud” and Databricks is now the “Data and AI Platform”. In Data there is no Data anymore; only Data and AI.
If data of all types is consolidated into a single place, this surely opens up huge possibilities for Machine Learning and AI. Imagine - all of your pdfs, emails, structured event data, marketing campaigns etc. are all sitting in clean, queryable form in a single place within your network - this is a data scientist (or prompt engineer)’s nirvana.
Databricks, who bring in billions every year running Machine Workloads written in pyspark for this exact purpose almost went down the unstructured data funnel, starting by specialising in workloads at the end of it and moving down into data warehousing.
As a result, the suite of tools available there for Machine Learning and AI is almost unparalleled. Snowflake are of course trying to catch-up, but the traditional stomping ground for these kinds of operations lives within the cloud providers.
The question therefore is not around Lake vs. warehouse, but whether the preferred AI tooling is compatible with data living either in a structured, object storage layer or if some egress of gold-layer data from a data warehouse is necessary / how good their AI operations are.
You have to feel that the future of AI lies not in the warehouse, but in object storage - but this is just a personal feeling you may or may not share.
Increasing focus on Data and AI Control Planes
Architecturally, ELT Tools work because you ideally have a single code-base that integrates with all your business SAAS tools that can move data.
In the same way, enterprise architects are broadening their view of orchestrators like Airflow as the only means to trigger and monitor jobs to control planes. A control plane includes a fully-featured orchestrator, but also provides the necessary services to deploy robust data pipelines at scale.
These include slick UI, business usability, metadata aggregation, comprehensive alerting systems, data lineage, and of course, data quality monitoring.
However the biggest and most necessary benefit is interoperability. Data Teams (rightly) want to use the “right tool for the right job”. No matter how good data warehouse and lake technology providers become, there will always be an additional tool - be it Power BI, a Kafka instance, or some other random process running somewhere else.
This interoperability necessitates a control plane - something that sits on top of everything (like Orchestra).
Furthermore, due to an enormous amount of funding poured in to the ecosystem, there are many point solutions operating at this level like data catalogs, quality tools, lineage tools, “Observability” tools - all basically doing the same thing. It does not make sense to have multiple pieces of heavyweight infrastructure that are all fundamentally extracting and surfacing the same metadata - it is better, cheaper, and more reliable to have one. You can see how Orchestra does this below
Aside from this fundamental shift in possibility of what can be done in object storage and an increasing number of peripheral services offered by the providers of warehouses and data lakes, 2024 was, I suppose a quiet year dominated by AI headlines.
Enterprise Data Architects with time to kill are looking at iceberg and other open table formats, but the mass exodus of data from warehouses is not an easy (or fun) thing to implement.
A key theme is the tradeoff in ingress/egress costs and ease of use. Many companies use Databricks for pre-processing, but still prefer to leverage Snowflake for activating data with its slick interface and strong SQL interoperability. As the need to activate that data together with other data in object storage grows, will the egress costs outweigh the benefits of the serving layer? Would it just make sense to do everything in a data warehouse and hope their unstructured data processing capabilities increase?
The jury is out but they’ve almost finished convening.
The final theme which is still very true today is the focus on skills - different platforms inevitably require different but increasingly homogenous sets of skills.
Can you maintain spark clusters via databricks and write pythonic spark code or do you prefer SQL? Will you really expect your organisation to scale to petabytes of data in the next 5 years or are you ok building an infrastructure that’s good enough for 99% of companies instead of 100%? Such are the nature of truly binding constraints.
If you’re interested in reading the guide from 2024, please crack on below. To stay in touch for the 2025 edition, please subscribe.
This whitepaper was originally posted here.
Introduction



Definitions
Before proceeding it will be helpful to define the difference between a data lake, data lakehouse and data warehouse. Data lakes and data warehouses are often presented as opposing ends of the analytical spectrum, however a data lake is really a much broader, solution-agnostic term for storage [1]:
A data lake is a centralized storage location that allows you to store all your structured and unstructured data at any scale.
By contrast, a data warehouse as defined by Wikipedia [2] is:
A data warehouse, also known as an enterprise data warehouse, is a system used for reporting and data analysis and is considered a core component of business intelligence. Data warehouses are central repositories of integrated data from one or more disparate sources
From which it is obvious that a data warehouse is more than just storage for data; it’s an entire analytical system. The analog of a data warehouse for a data lake, is therefore a data “lakehouse” [3]:
A data lakehouse is a data platform which merges the best aspects of data warehouses and data lakes into one data management solution
With this in mind, we’re now in a position to assess Data Lake Architecture as a whole rather than limiting ourselves to comparisons between “Data Lakehouses” such as Databricks, or Data warehouses such as BigQuery or Snowflake.


How this affects tooling
File formats, objects and storage options affect the way data engineers use platforms
The underlying components of an object store like S3 are complicated, and these components mainly exist to serve up files (which are series of 1’s and 0's). The file format or file type is the logic required to convert these bits into something interpretable.
This provides a helpful way for us to understand what a tool like Snowflake (or for that matter, any data warehouse) actually is. Snowflake was originally built on S3 and has its own proprietary file format which allows data to be read, queried, and amended easily.
This is architecturally really quite similar to say, Databricks on S3. The difference is that Databricks uses open-source file formats in S3 — however wait! Databricks does have it’s own file format called Delta. Or to be precise, an abstraction on top of parquet files. This too, is open-source (like parquet) and adds a transaction log / catalog to enable ACID transactions.
It’s this file format which Databricks uses to effectively and efficiently query data; to give users a “warehouse-like” experience; where you can easily aggregate 100m rows in a few seconds like you can in Snowflake.
With Snowflake and other CDWs, on the compute side, you pay for (1) data movement from your object store to Snowflake (if you have a data lake). You pay (2) to convert to their file format. You pay (3) to query i.e. to read and write data. You pay twice for storage in this scenario (see the [1] in the boxes below).
Compare and contrast: Snowflake vs. Databricks compute operations

Under a data lake architecture like Databricks, you pay twice for storage as well because although you don’t need another object store, you still need to store the .delta files somewhere. You don’t pay for data movement really as everything’s in your data lake, but you do also pay for file conversion and for querying (2 and 3).
An important point is that these comparisons in cost aren’t like for like. There have been lots of comparisons between the two platforms to see which is cheaper. However just because you incur a query cost in a lakehouse architecture and a warehouse one doesn’t mean it’s the same everywhere as the file format is different — and we know different file formats impact the speed of execution of certain types of query.
Storage costs are also not necessarily like-for-like (it depends on the data you’re storing — parquet stores nested json data much more efficiently than most other file formats, for example).
There are multiple comparisons between Databricks and Snowflake circulating, which report wildly different results

Architecture summary
In this section, we saw how there are subtle differences between definitions of a data lake, data warehouse and data lakehouse. All architectures include some kind of object storage, and what differs is the types of objects that are stored and how they are accessed and manipulated in order to deliver analytical capabilities to end-users. In the next section, we’ll see how one can adopt a “top-down” approach to analysing the merits of a data lakehouse — rather than focus on fundamentals and how these should determine what architectures to pursue, one can also focus on the needs of the system, and what types of tools adequately fit those needs.
When you really need a lakehouse architecture
The three factors
There are three factors that affect whether or not you need a lakehouse architecture. These are similar to those affecting whether or not you use batch or streaming: Throughput, Latency and Complexity.
Throughput
Throughput is defined as the total volume of data required to be processed in a given time. For workloads where high throughput is required, serious computing power is required to crunch through data. Expensive operations may include:
Flattening nested jsons
Joining together multiple tables
Running complicated transformations or aggregations
Performing feature engineering and machine learning tasks such as training models
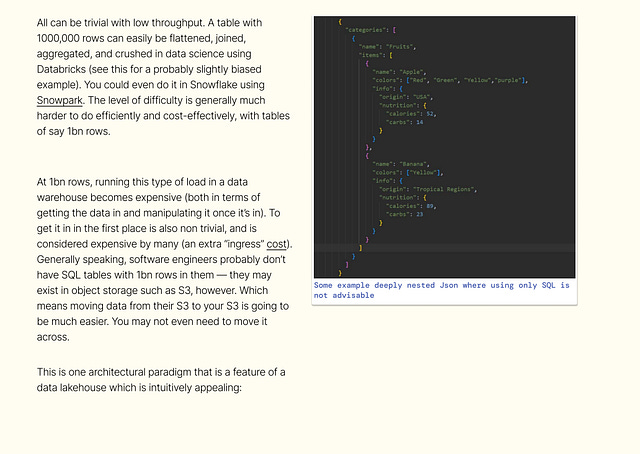
If data teams and software teams can both be served by the same data store, data lakes can avoid unnecessary duplication of the storage of data
Most if not all data practitioners would agree that avoiding duplication is good architecture. However, it may not always even be possible — a software team may require a data store that’s easy to append rows to (like a list of orders). For thousands of orders per second, this data store may need to be so good at letting rows get appended it can’t really be queried that easily (e.g. Amazon’s Dynamo DB). In this case, it’s better to replicate the data somewhere else that serves the needs of the data team (querying, amongst other operations) best.
We can nonetheless conclude that throughput matters. Not just for executing workloads efficiently, but also for moving data. While CDWs like Snowflake are actually pretty good at handling volume, data engineers incur cost for ingress (moving data in) but also egress (moving data out).
Latency
The limit of SQL workloads are generally greater compared to operations using spark, ignoring things like cluster warmup times. By way of example, running dbt on a CDW at less than 5 minutes is both ill-advised and expensive. SQL is, however, the lingua franca of data warehouses, which presents an inherent problem for data teams. How can we run SQL-like analytics at low latency (sub second, or even sub 100 millisecond) ?
There is nothing intrinsic about data lakes that make them preferable to warehouses in this regard. After all, both use the same underlying object stores and file formats. Historically, data lakes facilitated computation in situ which was an advantage ove CDWs, however now most CDWs support the creation and manipulation of external tables — tables that live in your own data lake, which means this advantage has been erased. We can therefore look at two common implementations of low-latency or streaming data use-cases, and use these as the starting point for our analysis:
Ingesting data from sensors to provide real-time reporting
A streaming engine like RedPanda or Striim is used. These engines handle basic transformation. Minimal processing is required once data passes through the streaming engine (maybe a couple of simple left joins). The streaming engine also has memory, and acts as a temporary database that allow joins across data points that arrive at different teams. Slowly-changing tables like customer tables can also be made available to the streaming engine. Data teams prefer to do this in a lake environment due to the (often large) amount of data they’re playing with.
2. Real-time transformation needs driven by complex analytical or ML Workloads
Data is ingested in real-time from multiple sources which means using a stream processing engine to handle transformation is not possible. Spark workloads need to be run, treating data sources as streams, to perform feature engineering and feed data into models in real-time. This is easily done using something like Databricks or by running spark in EMR

Achieving anything like this with even 15 second latency in a data warehouse is currently challenging and very nonstandard. A telling illustration of this comes from the dbt Coalesce 2022 conference — when we asked Tristan Handy how fast dbt could go the answer was immediately “as fast as the data warehouse”.
This isn’t what the question was asking — we wanted to know if there was a scenario where your dbt transformations, as defined in SQL, could effectively always be running, always transforming, always ‘incrementalising’ in an efficient way i.e. running transformations “at the speed of streams”. The project parse time for dbt jobs is a huge barrier to this. It’s challenging to run dbt every minute, let alone every second. It’s therefore unrealistic to think of using a warehouse for low latency workloads when evaluating technology in its current state.
Complexity
Generally speaking the more complex workloads are, the more likely python or spark will be required rather than SQL (although engines such as Trino, ClickHouse and Dremio do offer SQL-like interfaces). Playing with deeply nested jsons is a good example — even though this can be done in CDWs like BigQuery or Snowflake it’s not great practice to be manipulating jsons in SQL or storing them as values in columns. If the data warehouse is the source of truth and has table formats optimised for basic SQL operations. It is generally thought of as “hacky” to rely on SQL to do complex data cleaning of this nature.
Anything complicated to do with Machine Learning (“ML”) is also generally easier to do with a data lake because you aren’t restricted by file formats. Data lakes are just raw data, which is the perfect playground for ML.
The final point worth noting is the fact data lakes support any file format. This can be illustrated using the data operation of a recycling company. The company trains their models on image data as it classifies pieces of waste as plastic bottles, cans, etc. so it can recycle them efficiently. This entails having an object store with the images that can be accessed and converted into data science-friendly format. This is obviously not possible in a data warehouse because data is stored in a specific format optimised for tabular data, however Snowflake is increasingly supporting other file formats, such as documents via their document-to-text ML functionality.
Final Considerations
Throughput, Latency, and Complexity are all very real constraints and requirements data operations have to deal with. Due to the greater level of customisability inherent in data lake architectures such as the ability to store any file format, to perform processing jobs using different engines such as spark, data lakehouse architectures appear more closely aligned when these requirements are more demanding.
Furthermore, as noted by Snowflake themselves, Data Warehouses entail “ingress” and “egress” costs. For large volumes of data, these can become prohibitively expensive, however are only a consideration if such data already exists in a purpose-built-for-data data lake. If architecture is being evaluated from a blank slate entirely, then there may be ingress and egress costs associated with maintaining a purpose-built-for-data data lake if it doesn’t exist already.
One area for further discussion is the ability to use streaming technologies which are close to Zero ELT in their ethos. Streaming engines such as Striim or RedPanda effectively act as temporary data stores and are capable of doing basic transformations such as joining together tables and performing basic aggregates. Due to the more ephemeral nature of storage and the natural lean towards incremental processing, running such basic transformations on a large scale is said to be cheaper or just as cost-effective as moving data to a CDW and transforming it there.
Another area that has not been covered is CDW tooling investment. CDWs are investing heavily in architectures that allow you to “bring your own storage” and functionality required to build applications and run Machine Learning projects. There are strong driving forces that are causing lakehouses and CDWs to converge in functionality.
Finally, Machine Learning workloads are generally more suited to data lakehouse architectures at the moment due to the ability to run more customisable and flexible code within them. Integrations with Model Registry services such as MLFlow and Feature Stores are also an important consideration here that require further discussion.
As noted, CDWs are significantly investing in their capabilities to perform similar types of analysis — for example, running ML operations in BigQuery is possible, and SnowPark by Snowflake also gives analytics engineers the ability to run python code as if they were data scientists.
The guiding principle therefore should be “use the right tool for the job”. Smaller data stores may not incur ingress/egress costs or ML operational problems at a scale worth worrying about. By contrast, low latency high throughput use-cases may entail a different architecture altogether. It’s also worth noting that there is also a world where companies use both a data lakehouse architecture and a CDW for reporting use-cases. Anything goes, as long as the problems are solved reliably and efficiently.
References
link - AWS What is a Data Lake
link - WIkipedia Data Warehouse
link - IBM Data Lakes
The Snowflake Paper on the Elastic Data Warehouse (the previous link is gone, but do check out the paper)
Find out more about Orchestra
Orchestra is a unified control plane for Data and AI Operations.
We help Data Teams spend less time maintaining infrastructure, make them proactive instead of reactive, and ultimately win trust in data and AI from the Business
We do this by consolidating Orchestration with monitoring, data quality testing, and data discovery. You don’t need an observability, lineage, catalog etc. with Orchestra.
Check out