


Data Leadership #3 Understanding Open Source
Not all open source is created equal


This article first appeared on Medium in a slightly different guise. It has been edited.
Introduction
As a Data Leader, it’s important to understand open-source software and it’s limitations. On the positive side, it’s often touted as more secure, more robust, and most importantly: free. On the other it’s a flaky cobweb of ancient dependencies you fundamentally have no control over. This means that when making architectural choices, understanding the nuances of open-source software is important: not all open source is created equally. Particularly in data, there are many “open-core” projects; pieces of software developed by private, venture-backed institutions who open-source a part of their project but not all of it.
With this in mind, I believe it’s sensible to evaluate open-source projects and closed-source software as operating on the same spectrum, with open-core (what most people falsely label open source) lying somewhere in the middle. Do not believe anyone who suggests a particular risk like quality or vendor lock-in disappears entirely under a given solution. They exist everywhere, and in this article we’ll explain how.
A brief detour to economics
In Economics, if someone gets value from using something, you sell it to them. Open source software is free, and used by many people, so it therefore makes no sense; whoever’s building the software is irrational. They should be selling this for money.
However, we aren’t all homo economicus , sometimes, people do things for free, for the greater good. That’s how I understood open-source software. Rationality aside, it’s also a smart way to maximise the output of many people doing small deeds for the benefit of the community (as they get compounded through banding together in an open-source project). Open-source software, is therefore a true public good. It’s non-rivalrous, which means:
Supply is not affected by people’s consumption
So if I download Linux, it doesn’t affect your ability to download Linux.
Public goods non excludable too:
It is not possible to prevent a specific person or group of people from consuming the good
i.e. nothing is stopping me downloading Linux therefore it’s non-excludable.
This is important, because it isn’t just open-source software that’s non rivalrous and non-excludable. Insofar as something can be downloaded from the internet, it’s all software. Indeed, anything that’s downloadable. If something of sufficient quality can be developed in an open-source way (we probably wouldn’t want to open source code to send spaceships to the moon, for example) and sufficient incentives exist to creators (we wouldn’t want to open-source music since it doesn’t provide the right incentives for musicians), there is no argument that can be made against Open Source software development as it results in Public Goods which are beneficial to society.
That’s Open Source. It’s developers like you and me contributing to stuff for the greater good. We do it for free. We do it because we recognise making stuff available for free that has fundamental characteristics of non-excludability and non-rivalry is good for society.
Open-core isn’t that.
Open-core is pitched as:
The open-core model is a business model for the monetization of commercially produced open-source software (Wikipedia)
Seems a bit odd doesn’t it. If something’s open-sourced, it’s a public good so it’s both non-rivalrous and (especially) non-excludable. If I can’t be prevented from using it, how will I pay for it?
Catch — in open-core it’s not all non-excludable. The hint is in the name; some features are open sourced, some are not. The core features are closed source, and require payment to purchase. This operates in the same way as regular software, in respect of excludability.
So there is a clip; there is a clip on the benefit to society from software because most of it isn’t free. “most” of the software requires you to pay.
Some quick econ
This is how people benefit in a normal market where people charge a price for goods:

This is a basic demand and supply diagram. At low prices of a good, there is lots of demand for it as it’s cheaper, so demand curves slope down. At high prices of a good, lots of suppliers want to produce and sell it, so supply curves go up. The market equilibrium is where these two curves meet.
This helps us understand the “benefit to society” or “surplus” from the market existing. Suppose there is one supplier willing to provide one unit of some good for P1S. Similarly, there is one person willing to buy it for P1D. The trade happens at P*, and over time more suppliers and consumers enter the market and we reach (P*, Q*).
At this point, everyone who buys the good basically is willing to pay at least P* for it so the consumer surplus (i.e. benefit to the person buying the stuff) is the top triangle, the bottom triangle is the same but for producers. The area of these triangles is proportion to the benefit of society from this market existing in a Perfect Competition scenario.
This is what Open-source looks like:

At any quantity, the price is the same (close to 0). This means there is only consumer surplus, no supplier surplus or benefit to suppliers (which makes intuitive sense). This is great. We also see the total size of the consumer surplus is much greater than the combined triangles in the perfect competition example. This reflects there being more people participating in the market than there would otherwise be (people who would buy at P*/2 for example wouldn’t in the first example, but will in this case).
This is a fairly standard justification for why people like Public Goods and therefore open-sourced software.
Surely Open-core is better than nothing
Well, yes and no.
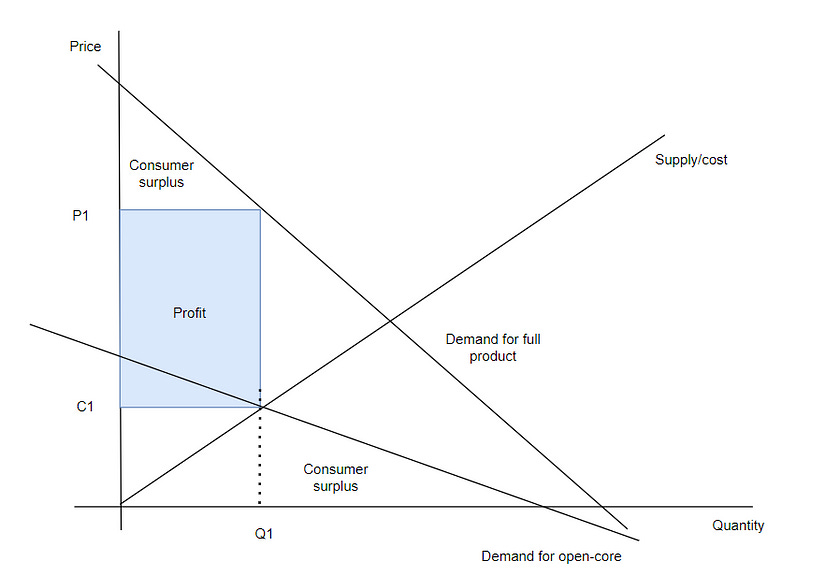
Here we see that there are effectively two products with different demand curves. A demand curve D* has greater demand than another D** if at a given price P the quantity under D* is greater than D**. We see the demand for the full product is greater than the demand for just open-core, which reflects how much more fully-featured the full product is vs. the open-sourced core part of it.
The supplier / oss company sets the profit maximising price. We see that the profit is the big blue square which is (P1-C1)*Q1. The consumer surplus on the paid product is very small; only those with the greatest willingness to pay purchase it. The Consumer surplus for the open-core is also quite small. That’s because there’s not much demand for it. This is much worse in welfare terms than pure open-source. It’s also worse than perfect competition because there’s a big deadweight loss; the triangle to the right of the blue profit rectangle.
However, this isn’t how the market starts. Indeed, this is how many open-core projects start. They start with the demand curves as practically the same, i.e. like a true open-source project with lots of surplus. Over time, they move to the diagram above, thus narrowing surplus and forcing people out. They develop the open-source core, and over time add paid features. This allows the creation of two demand curves, two markets, and introduces excludability and rivalry to the full product, which in turn allows them to generate revenue but simultaneously reduces the benefit we get from the open-core (relatively speaking) because it’s too complicated to run ourselves. This happens over the course of 2–4 years.

Open-core is therefore just: lead generation.
It’s literally a way to get users by giving them something for free and then charging them for it later.
It’s marketing. It’s a way to get users and free trials and make people build on your product in the stickiest way possible, so when inevitable feature restrictions or price introductions happen, no-one has anywhere to go.
This is why I get very upset when funding “Open source” is heralded as a great thing for the Data community. It’s because once there is that money, there is that profit motive, there is no way something is “open source” as I understand it. The project is fated to be on a trajectory towards profit maximisation and therefore away from the ideals of a public good, no longer worthy of the once great “Open Source” moniker — the welfare that accrues to the market is probably worse than perfect competition and it’s skewed to benefit suppliers not us, Data Teams / Consumers. If you use an open-source tool seriously and there’s venture money behind it, you will be disappointed at some point. There will be feature restrictions. You will be charged. Your expectations will be dashed. And yes, they have a CRM. And yes, you are in it.
Why is this important now?
This is important now for a few reasons:
It’s misleading marketing
I believe open-source projects have a great rep and rightly so. Funds investing into open-source should be a huge red flag for developers who rely on open source tooling. I don’t think awareness of this is that high. The biggest advantage of using open-source I often here is “there is no vendor lock-in”. Well look at how much money the project has — if there’s some, there’s vendor lock-in possibility.
2. It’s happening a lot now
It’s simply bad economics to give something away for free if you can get someone to pay for it. That’s why funds and private equity alike have focussed on stuff that isn’t open-sourced traditionally. What’s interesting is open-source software allows some projects to gain hyper quick adoption they wouldn’t have otherwise got, which in turn represents a hyper large monetisation opportunity down the road. Not a bad trade-off for 0 return in the first three years if after the initial open-source period you have 1m people in your CRM. This is a new phenomenon — lots of the great open-source projects over the last 15 years were not funded by VC money. This has changed. It means more people will be charged. It means more people need to know they will be charged.
3. Lines are blurring; not all open-source is created the same way
It should be clear that the benefits of an open-source project are not limited to the rivalry or excludability of the good. Indeed, it relates to the incentives there are to contribute to projects. If there are only paid devs, then it’s less likely the project has a community focussed feel — it will be focussed on whoever the target customer is of the backer. If the project is “open-source” but not part of a foundation, then there is basically no credibility. It’s feasible the project could become not open-source. Choose who you trust wisely.
4. I care about Data (as I work in Data) and in Data it’s rife
Here are some examples of open-source projects in and around data / dev tooling that are funded in no inconsiderable way:
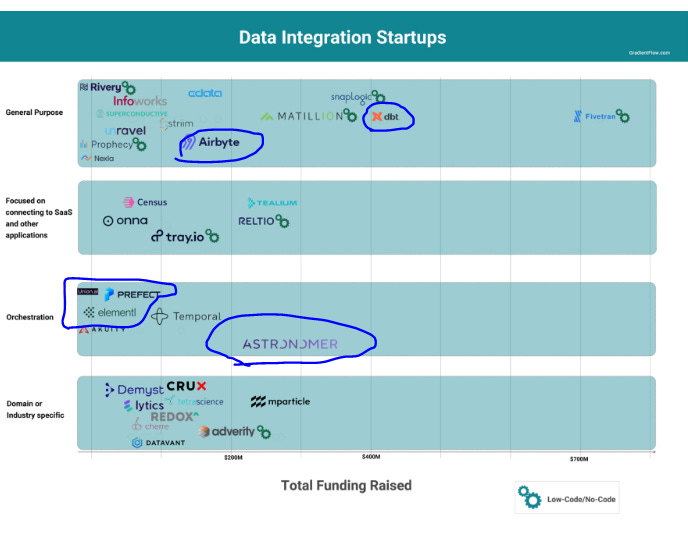
dbt — recently announced big pricing changes to the paid offering
Hashicorp — recently renounced OSS license.
Astronomer* — because Airflow came out of Apache, the project is still pretty pure in the open-source sense. Indeed, people still use Airflow effectively without paying for Astronomer, who didn’t develop the tool but sort of “jumped onto the bandwagon”. Astronomer made a new market for a tool built on Airflow and there was therefore never any risk they could “renounce an OSS license” so from that perspective, they’re probably net good.
Prefect — raised $32m
Dagster — Elementl behind it raise $33m (seriously? just to do $1m more than Prefect?)
Pydantic — $1m from Sequoia Arc, listen to this fantastic Podcast, you’ll see changes are coming. It’s very difficult to imagine Pydantic ever being chargable (like, everyone already has the code) but there’s potentially a Databricks-style play (read below) here. Personally, I have no idea what that looks like and am a bit skeptical (type-checking exists in lots of programming languages other than Python — there are no private companies built ontop of those, because they’re just like, features?). Happy to be proved wrong, happy to wait.
Vercel — Raised a shit ton of money but Vercel is still free, good example of building open-core without reneging on free offering or making pricing bad
Airbyte — $150m raised. You really need to check out Airbyte cloud, it’s much better than hosted airbyte.
Meltano — $8.2m
Databricks — worth a mention just because of how smart they were; by developing an alternative to Hadoop and plugging into Big Data, they rapidly accelerated the adoption of Big Data and Data Science in large enterprises. In parallel, they develop Databricks, which is a platform to run all those pyspark related operations. So technically it’s very different to other open-core companies. It’s not like “I developed Airflow, and you pay me to deploy it”, it’s more like “Hey look here are some rudimentary car designs and some working cars you can have for free. P.S. I sell seatbelts, SatNav, I can re-upholster your chairs etc”. This is genius, the proof is in the pudding. This is the perfect example of doing good open-source work, and also building a wildly successful business at the same time.
Conclusion
Something I heard a lot when I was trying to find early backers for Orchestra was how data engineers were often hesitant to go with closed-source software providers because of vendor lock-in.
This frustrated me a bit, because I knew that the vast majority of open-source software projects in the Data space aren’t like Linux or the Apache foundation, they’re driven by a profit motive via open-core. Even Airflow is not guilt-free since the repo is driven by a for-profit company (Astronomer — they make almost all the commits) which means the direction of the Airflow repo is headed towards whatever is most conducive to Astronomer’s financial interests. Hardly what most people think of when Open-source springs to mind.
Open-source software is terrific. It’s a public good. Closed software is also terrific, and it’s also a better way for people to earn a living who can’t afford to be committing to repos for free every day, which is most of us. Open-core often masquerades as the former, yet the diagrams with lots of lines and triangles demonstrate it’s actually much closer to the latter in welfare terms — which is what matters. Therefore next time, please think twice about open-source projects; they are not “better” in virtue of being open source and can lead to “vendor lock-in”. The vendor will get you. You are their customer. Not all OSS is created equal.
Hello 👋 I’m Hugo Lu, a Data Engineer who’s also worked in Finance and now CEO@ Orchestra. Orchestra is a data release pipeline tool hat helps Data Teams release data into production reliably and efficiently. I write about what good looks like in Data.