
dbt™️ Incremental Models Cookbook ; Merge vs. Insert Overwrite (BQ)
When to use dbt™️ Incremental Models in BigQuery

Foreword
Fun fact for data leaders — there is actually a trade off to be made between making things incremental and not.
It is simply easier to just load all the data all the time. Of course, at some point this will become too slow, and too expensive.
But until then, why not have some fun????
Some of the biggest pains we see facing data engineers and analytics engineers is that they spend too much time maintaining boilerplate infrastructure, and still have no visibility into pipeline failures.
It means you’re constantly fighting fires and don’t have time to focus on building. What’s worse is that the business doesn’t trust the data.
At Orchestra we’re building a Unified Control Plane for Data Ops. A Data Status page if you like, with some incredible features to give data teams their time back so they can focus on building. You can try it now, free, here.
Introduction — why use incremental models?
As Data Engineers and Analytics Engineers we often want to define data models that depend on each other.
Building a model “from scratch” is a bit like loading all of the data every time you want to do something.
This has issues. Imagine you want to aggregate total sales from an orders table. Should you count every row in the orders table every hour just to get that final number?
The answer is no — and how we achieve that in data build tool (dbt for short) is generally achieved by an incremental model.
In this article we will dive into two types of incremental model; merge and insert_overwrite specifically for BigQuery.
Video Tutorial: dbt Tutorial: dbt incremental models in bigquery; MERGE vs. INSERT_OVERWRITE
How to make a dbt™️model incremental
Generally you would go from
{{ config(materialized='view') }}
select
dateadd(DAY,CS_SOLD_DATE_SK - 2415020, '1920-01-01') sold_date,
dateadd(DAY,CS_SHIP_DATE_SK - 2415020, '1920-01-01') ship_date,
CS_BILL_CUSTOMER_SK bill_cutomer_sk_id,
CS_SHIP_CUSTOMER_SK ship_customer_sk_id,
CS_ITEM_SK item_sk_id,
CS_ORDER_NUMBER order_number,
CS_QUANTITY quantity,
CS_WHOLESALE_COST cost,
sha2_binary(CS_ORDER_NUMBER) _pk
from {{source('bigquery', 'catalog_sales')}}
LIMIT 1000to something like:
{{
config(
materialized='incremental',
unique_key='_pk'
)
}}
with base as (
select
dateadd(DAY, CS_SOLD_DATE_SK - 2415020, '1920-01-01') as sold_date,
dateadd(DAY, CS_SHIP_DATE_SK - 2415020, '1920-01-01') as ship_date,
CS_BILL_CUSTOMER_SK as bill_customer_sk_id,
CS_SHIP_CUSTOMER_SK as ship_customer_sk_id,
CS_ITEM_SK as item_sk_id,
CS_ORDER_NUMBER as order_number,
CS_QUANTITY as quantity,
CS_WHOLESALE_COST as cost,
sha2_binary(CS_ORDER_NUMBER) as _pk
from {{source('bigquery', 'catalog_sales')}}
)
select * from base
{% if is_incremental() %}
where sold_date > (select max(sold_date) from {{ this }})
{% endif %}You must ensure there is a primary key.
dbt Cloud™ alternative | Orchestra + dbt Core™
dbt Incremental Model; merge incremental strategy
The merge strategy has a few components
Defines a table of data that is “new”. This is what is compiled by dbt (head to the target folder to see)
Defines the target data
Defines a match condition
Where the match condition is met, by row, data will be updated
Where the match condition is not met and rows exist in the source but not the target, insert that data

Use if: you have complicated matching conditions where simply looking at partitions of data (e.g. by date) is not enough.
This is a bit slower and much more expensive in BigQuery than insert overwrite.
Video Tutorial: Easiest way to run dbt Core! How to run dbt Core in Production with Orchestra
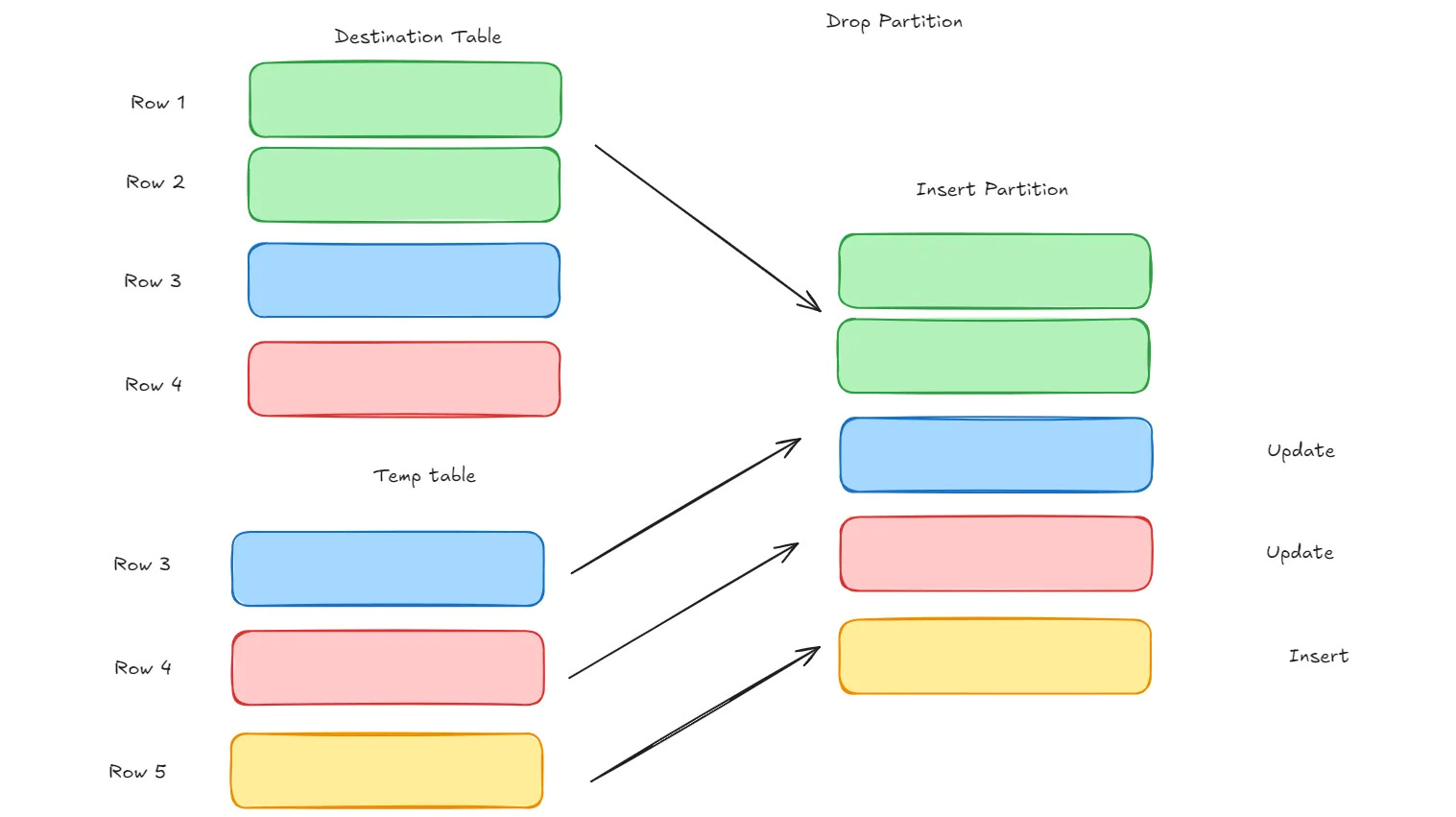
dbt Incremental Model; insert_overwrite incremental strategy
dbt Incremental Model: insert_overwrite Strategy
The insert_overwrite strategy is a cost-effective and popular approach for incremental models in BigQuery.
Each run generates a table of “new” data based on the latest changes.
Instead of updating specific rows, it replaces entire partitions (or clusters) of the target table where new data exists.
dbt compiles this model by creating a new set of partitions and then overwriting the existing partitions in the target table with these new results.
This method ensures that only the necessary partitions are refreshed, reducing the overall cost and runtime.

Use when: you have partitioned data which comes in fairly regularly
Conclusion — use dbt incrementals!
When I tested these out the benefit of insert_overwrite vs. merge in terms of bytes processsed (the BQ costing metric) was pretty substantial, over 90%, so I would always try to use insert_overwrite where possible.
A natural next step is to understand cost per query using something like dbt. Fortunately you can use Orchestra for this.
In the next article, we’ll look at dbt’s latest incremental strategy: Microbatch.
Happy Modelling !
HL
Find out more about Orchestra
Orchestra is a unified control plane for Data and AI Operations.
We help Data Teams spend less time maintaining infrastructure, make them proactive instead of reactive, and ultimately win trust in data and AI from the Business
We do this by consolidating Orchestration with monitoring, data quality testing, and data discovery. You don’t need an observability, lineage, catalog etc. with Orchestra.
Check out