


dbt tutorial: getting set-up with dbt-fabric in the Fabric Data Warehouse
Understand how to get started with dbt in Azure

Foreword
Did you know Microsoft allegedly tried to buy Databricks multiple times?
Every time, their expectations were misaligned. They asked for too little money. Databricks said there was not enough growth baked into the valuation.
This happened multiple times up into the billions - now they’re worth $40bn and it’s too late.
Why is this relevant? Well, because insofar as Azure was designed as something Data ENgineers could spend money on, they didn’t.
No - GCP and AWS offered the ability to do a full roll-your-own solution for data engineers. Trying to do this on Microsoft would have been a nightmare.
Meanwhile, every enterprise CDO we speak to informs us that Microsoft is preparing a huge army of software engineers to build this specialised data weapon dubbed “Fabric”.
It is, of course, released in 2023 amidst much fanfare, and is revealed to simply be a cobbling together of existing tools like ADF, Synapse etc.
Fast forward a year, and things are looking different.
dbt Labs are investing heavily into their Microsoft relationship, perhaps sensing the blood of Snowflake and Databricks will not be enough to sustain them.
The consultants of Azure and Databricks speak about Fabric differently - murmurings of “OneLake” and a “New Synapse” built for iceberg and lakehouse architectures are beginning to emerge.
IN Tandem, at Orchestra we also see immense upside in the adoption of iceberg and the unification of storage locations. Orchestra supports dbt-core, and we also support dbt-fabric.
And check it out - Fabric is gaining traction. It was extremely easy to set-up. It is familiar, especially for people familiar to SQL Server.
So what is the point?
The point is - for Data Leaders who inherit enterprise data estates on Microsoft and Azure, you cannot ignore Fabric. You have the credits, and it is just there . That “Databricks migration” that is 25% through but 80% through cost-wise you inherited might not be as necessary as you thought - sure, for Spark Workloads it’s perfect. But you might not necessarily need to build your analytical warehouse there.
Data Leaders should focus on interoperability and choosing the right tool for the job. With Fabric’s support for dbt-core and the increasingly good look of the platform, for some things, it could just be Fabric!
Just don’t use Azure Synapse :)
Some of the biggest pains we see facing data engineers and analytics engineers is that they spend too much time maintaining boilerplate infrastructure, and still have no visibility into pipeline failures.
It means you’re constantly fighting fires and don’t have time to focus on building. What’s worse is that the business doesn’t trust the data.
At Orchestra we’re building a Unified Control Plane for Data Ops. A Data Status page if you like, with some incredible features to give data teams their time back so they can focus on building. You can try it now, free, here.
A First Look at Microsoft Fabric - Introduction
Setting up dbt in Microsoft or Azure has been something to stay away from for a very long time. Azure Synapse was not a great product. Many executives and data leaders rightly were shunned by how tragic it was compared to modern warehousing solutions like Snowflake, and increasingly, lakehouses on object storage.
This is changing, partly in fact due to the lakehouse, ADLS Gen-2, and iceberg. To paraphrase a friend of mine, when I asked him what warehouse is under-the-hood in Microsoft Fabric:
do you want the easy answer or the right answer?
It’s an evolution of SQL Data Warehouse/Synapse, but it’s totally re-engineered with a brand new polaris engine that’s optimised to work with delta table formats. To the naked eye, it could quite easily just be cloud based SQL Server. You can use T-SQL, write stored procs, even use Visual Studio Database projects to manage them. So from a dev experience, it’s very much targetting your old school SQL Server persona, but the plumbing under the hood is very different (and of course it wouldn’t be Microsoft if it didn’t come with a bunch of limitations/caveats that mean some thins don’t quite work the way you expect them)
This piqued my interest enough to think we should now support dbt-fabric in Orchestra:
dbt Cloud™ alternative | Orchestra + dbt Core™
Running dbt Core™ in your orchestrator has never been easier. Set-up rapidly, stop paying for an IDE you don't need…www.getorchestra.io
Anyway, there are some interesting gotchas associated with Azure Synapse vs. Azure Fabric, so let’s jump in.
What’s the difference between Azure Synapse and Azure Fabric?
Answer: Synapse is Microsoft’s legacy, soon to be defunct, data warehouse. It is abandaned / merged into whatever is under the hood, which we could call azure-fabric , fabric data warehouse , fabric-synapse honestly at this point I don’t really know what the name is.
This is why I like the quote above since it actually makes sense.
Chat GPT yields:
Azure Synapse and Microsoft Fabric are both comprehensive data solutions offered by Microsoft, but they have different focuses, architectures, and scopes. Here’s a breakdown of the key differences between the two:
1. Purpose and Scope
Azure Synapse Analytics: Primarily designed as an analytics service that unifies big data and data warehousing. Synapse provides tools for data integration, data warehousing, big data analytics, and machine learning, all within a single analytics platform. It focuses on enabling large-scale data processing and analytics, including SQL-based data warehousing and Spark-based big data processing.
Microsoft Fabric: Microsoft Fabric is an end-to-end, unified data platform encompassing multiple data services (like Data Factory, Synapse Data Engineering, Synapse Data Science, Synapse Data Warehousing, Synapse Real-Time Analytics, and Power BI). It’s designed to offer a fully integrated data ecosystem, covering everything from data ingestion and transformation to real-time analytics and visualization. Fabric is built on top of the OneLake data lake, a central storage solution, allowing seamless data sharing and collaboration across the organization.
2. Core Components and Integration
Azure Synapse Analytics: Combines components such as Synapse SQL (for data warehousing and on-demand queries), Spark (for big data processing), Synapse Pipelines (for ETL workflows), and Synapse Studio (an integrated development environment). Synapse Analytics focuses heavily on analytics and integrates well with other Azure services, such as Azure Machine Learning and Azure Data Lake.
Microsoft Fabric: Integrates a broader range of services beyond those found in Synapse. It includes:
Data Factory for data ingestion and integration.
Synapse Data Engineering (based on Apache Spark) and Data Science (machine learning).
Data Warehousing (for structured data storage).
Real-Time Analytics for analyzing streaming data.
Power BI for seamless data visualization.
Fabric also provides a unified development environment, Fabric Studio, for accessing all these tools and services under one umbrella.
3. Data Storage and Management
Azure Synapse: Uses Azure Data Lake Storage (ADLS) as the primary data storage solution. Data can be queried directly from ADLS or ingested into Synapse SQL pools for structured storage. Synapse also supports “on-demand” querying of data without moving it into SQL pools.
Microsoft Fabric: Utilizes OneLake as the core storage layer, which acts as a multi-cloud data lake optimized for Fabric. OneLake provides a single, unified storage layer for the entire data estate, allowing all Fabric workloads to interact with the same data seamlessly. This storage model encourages collaboration and data reuse across the organization.
4. Collaboration and Accessibility
Azure Synapse: Synapse offers some level of collaborative capabilities, but they’re more technical and focused on data engineers and analysts. Synapse Studio is built for users familiar with data development and analytics.
Microsoft Fabric: Fabric takes collaboration further by integrating Power BI, which makes it accessible to business users, analysts, and data scientists. It’s built to allow data sharing across an organization, from raw data to dashboards, enhancing accessibility for non-technical users and creating a more collaborative data culture.
5. Real-Time Analytics and Machine Learning
Azure Synapse: Offers real-time analytics capabilities through Azure Stream Analytics and Synapse Spark but is limited in terms of native machine learning features. It does, however, integrate with Azure Machine Learning for advanced ML workflows.
Microsoft Fabric: Fabric has built-in capabilities for real-time analytics and machine learning, offering Synapse Real-Time Analytics and Synapse Data Science. This enables real-time insights and machine learning modeling within a single environment without needing additional services.
6. Cost and Licensing
Azure Synapse: Uses a pay-as-you-go pricing model for its various components, where you pay separately for Synapse SQL pools, Spark pools, and data integration pipelines.
Microsoft Fabric: Fabric offers a unified billing model, with billing based on capacity rather than individual services. This model allows organizations to better manage costs across data integration, analytics, and visualization in one package.
7. User Base and Ideal Use Cases
Azure Synapse: Best suited for data engineers, data analysts, and data scientists who require a robust platform for big data and analytics processing, especially if their needs focus on large-scale data warehousing and Spark-based processing.
Microsoft Fabric: Designed for broader organizational use, Fabric serves data engineers, data scientists, business analysts, and business users. It’s ideal for organizations looking for a unified platform for everything from data ingestion and transformation to real-time analytics and visualization.
Which is actually quite helpful.
Steps to get up-and running with dbt-fabric
venv a new environment; activate.bat inside of it
Install ODBC driver (choose 18 — link)
Install Azure CLI (optional, it’s for Auth)
Go into Fabric; set-up a warehouse:

Now for Auth — this is the hardest bit. The easiest is to head to settings (top RHS) → admin Portal -> developer settings:
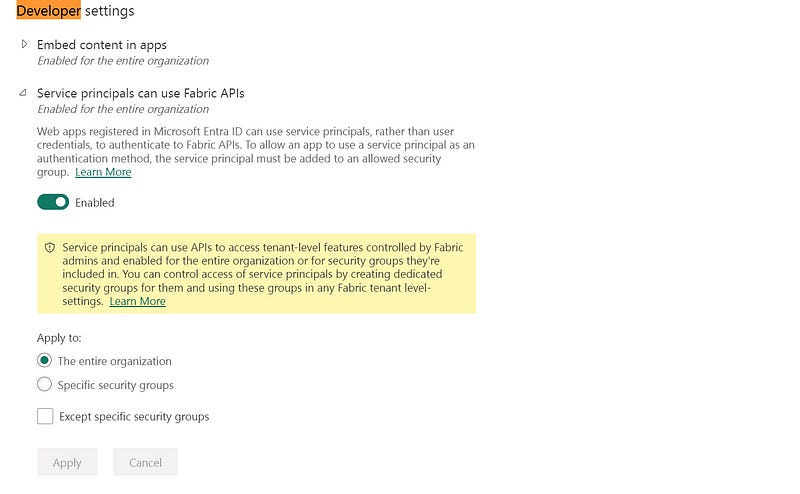
You should now be able to the relevant RBAC stuff in Azure so
Create a security group that has access to Fabric
Create a Service Principal and an Enterprise Application that are part of it
Note the Client ID, Client Secret and Tenant ID
Now you are looking pretty good.
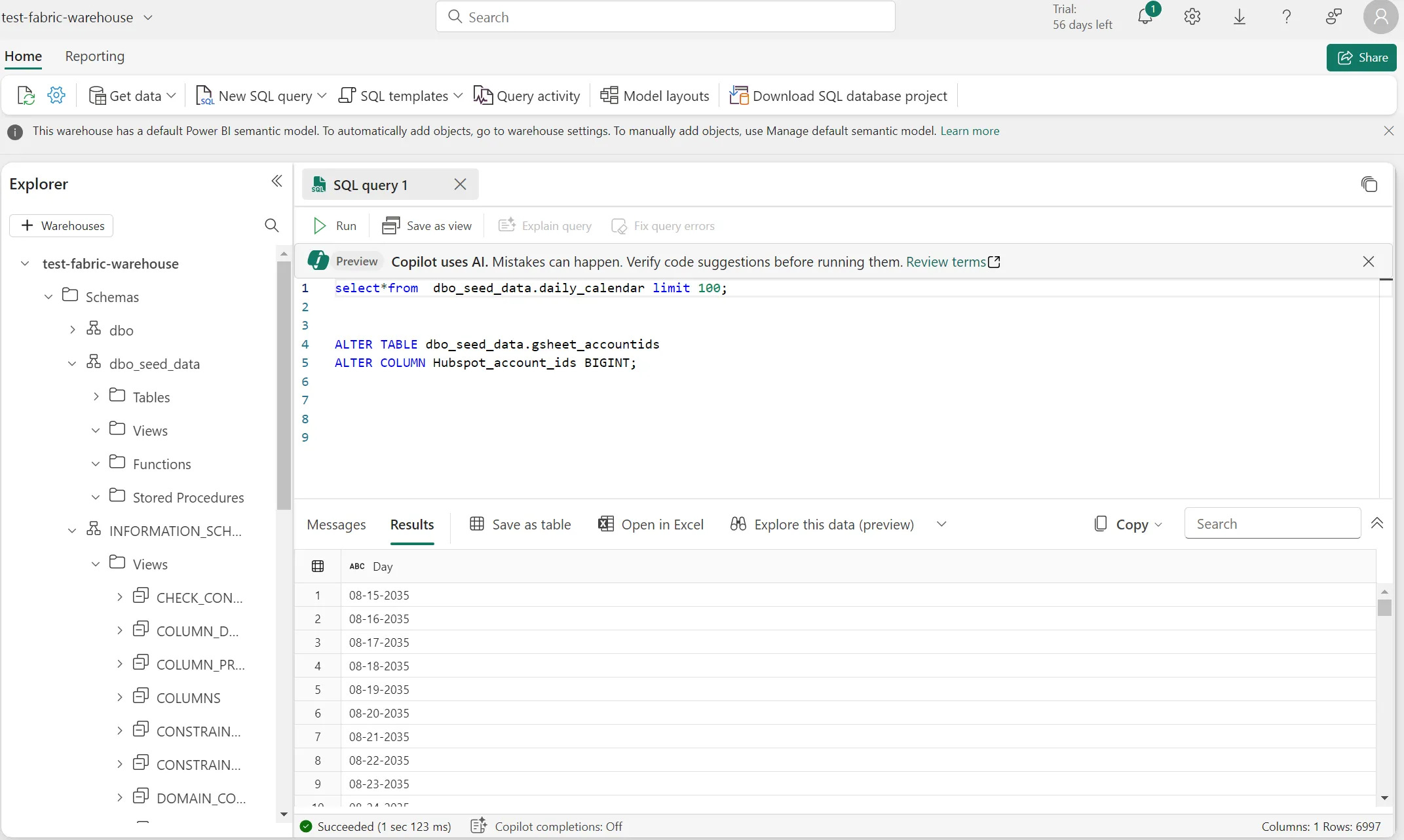
SQL Connection String for Fabric / Server or host name for dbt Fabric
It would be incredibly helpful if, in the dbt docs, they would actually tell you where to find these different variables for the profiles.yml file…sigh. The hardest one for dbt-fabric is the server name, this is found here:

Also:
The database name is top left of the hierarchy in Fabric; dbo would be the schema
Don’t forget to give service principals access to the workspace
dbt profiles.yml for azure fabric
So I did actually get dbt debug to work first time with azure fabric which I am very proud of. I’ve set up dbt-bigquery and snowflake dozens of times and I normally screw something up.
dbt_fabric:
target: dev
outputs:
dev:
type: fabric
driver: 'ODBC Driver 18 for SQL Server' # (The ODBC Driver installed on your system)
server: something.datawarehouse.fabric.microsoft.com
port: 1433
database: test-fabric-warehouse
schema: dbo
authentication: ServicePrincipal
tenant_id: some_guid
client_id: some_guid
client_secret: some_valueThis is by far the easiest way to connect locally unless you are comfortable with the Azure CLI which we downloaded earlier. I won’t cover how to auth here.

Tips and Tricks for dbt Fabric in Azure Fabric
you’re basically writing T-SQL so remember the types (BIGINT, VARCHAR(256) etc.
this integration is relatively new and some dbt behaviour is still not super nice. For example, seeds can’t work out that
234567is obviously aBIGINTnot anINT, so be sure to specify your seed schemas manually in your dbt_project.ymlSpeed; Fabric is slow! So don’t get too frustrated if you come from a BQ/Snowflake land
Example dbt seed configuration for dbt-fabric
seeds:
orchestra_dbt_fabric: #project_name
enabled: true
schema: seed_data
# This configures seeds/gsheet_accountids.csv
gsheet_accountids:
# Override column types
+column_types: #the + sign is imperative
account_ids: BIGINT
account_GUID: VARCHAR(MAX)
Name: VARCHAR(MAX)Incremental; will be expensive. Fabric only support delete+insert or append (reference). TIP: use Orchestra WITH dbt-core to get the best of both (manually scheduling queries, stored procs and dbt jobs).
EDIT: looks like merge is supported too.
Video: Easiest way to run dbt Core! How to run dbt Core in Production with Orchestra
Conclusion
Remarkably easy set-up for Azure so well done.
The only question is — where will you run dbt-core on Azure? You know what I’ll say! But there are other options; people have run it in ADF (it is filthy) or a Virtual Machine (nice, but poor visibility).
For enterprises it’s obvious that dbt-core has to be running in an orchestration or unified control plane.
Fabric is still very early but the promise of being able to easily query data in ADLS Gen-2 AND have a SQL-like experience many of us SQL Server users are familiar with is big. Even a fraction of the utility of a platform like Snowflake will be an enormous improvement for DBAs and Data Engineers alike who have been leveraging SQL Server, MySQL and Postgres for analytical use-cases for the last ten years.
So come-on Fabric! We’re rooting for you! Please be better than Synapse! 🌞
References
1- Connectivity to data warehousing - Microsoft Fabric
Follow steps to connect SSMS to data warehousing in your Microsoft Fabric workspace.
2- Asking for a Server Name.. Help Clarify Please
community.fabric.microsoft.com
3- Install the Azure CLI for Windows
4- Microsoft Fabric Synapse Data Warehouse setup | dbt Developer Hub
Read this guide to learn about the Microsoft Fabric Synapse Data Warehouse setup in dbt.
5- Microsoft Entra authentication in Synapse Data Warehouse - Microsoft Fabric
Find out more about Orchestra
Orchestra is a unified control plane for Data and AI Operations.
We help Data Teams spend less time maintaining infrastructure, make them proactive instead of reactive, and ultimately win trust in data and AI from the Business
We do this by consolidating Orchestration with monitoring, data quality testing, and data discovery. You don’t need an observability, lineage, catalog etc. with Orchestra.
Check out