
ELT with Fabric, Azure and Databricks: Patterns for 2025 and beyond
What people are doing with Microsoft Fabric and Databricks; and what they will do

Substack Note
This article is available as a whitepaper on getorchestra.io .
Since writing this, there have been some very, very interesting developments. But first, a couple of thing you should know:
Databricks are gunning for the entire data and AI market. They want to build EVERYTHING
Microsoft want to destroy databricks, having failed to acquire them multiple times, they are investing heavily into Fabric which is built on delta lake.
Now, here are two very interesting observations:
Firstly, when you go for the all-in-one platform play you had better be sure you’ve got enough to keep people interested.
Databricks pioneered the lakehouse, or shall we say, the open lakehouse - so dubbed as the data is queryable from any location.
This means that when (not if) cheaper and more efficient sources of compute emerge that are viable alternatives to Databricks’ spark, workloads will shift away from Databricks, likely not en masse, but significantly.
Examples would be Ray, Duck DB, Apache Data Fusion.
This could be the downfall of Databricks, who are investing a huge amount into the peripheral features like unity catalog, workflows, lakeflow, AI/BI etc.
These really only work well if 90% of your stuff is within the Databricks ecosystem. What happens when these workloads get distributed? What happens when you start using AWS Glue as a catalog instead? Will Databricks host Gravitino?
For the platform play to truly work, complexity needs to get smaller, so databricks’ stuff gets relatively better. But that’s not what is happenning. Complexity is increasing. Especially with AI.
A failure to address this and focus on the core business would mean a lot of this innovation is for nothing. It is evidenced today already by the vast number of people that use Databricks with other third party, best-in-class tools; orchestrators like Orchestra or *legacy* airflow and Catalogs like Atlan.
Second point — Fabric basically want you to do the same thing, and I believe they will fare better.
Why? Again, two reasons.
Many people doing lots of data work on Fabric are already heavily bought in to Azure services. This means they can easily be ported to Fabric vs. other platforms as Fabric is just the same stuff in a wrapper.
Some companies “just to Microsoft”. So the platform play is much easier because the CTOs of these companies are already basically having a sleepover at Bill Gates’ House (metaphorically)
So yes, please enjoy the architecture patterns below we see people using. We are sure they will be out of date soon.
Typical Data and AI Architectures on Azure in 2025
The landscape of data management has evolved rapidly over the past 5 years. In the world of Microsoft, three common resource pools have emerged as the market leaders or market standards for Data Engineering; Databricks, the generalpurpose Azure Cloud and increasingly, Microsoft Fabric. Although MIcrosoft introduced Azure Synapse in 2019, this was initially aimed to offer a unified analytics service but faced challenges in meeting flexibility and performance expectations, especially as more advanced platforms emerged. Microsoft has since responded by launching Microsoft Fabric — an AI-focused, cloud-native solution leveraging Apache Iceberg to enable scalable data analytics and streamline big data workflows, intended to compete directly with Databricks.
The Databricks Revolution and Apache Iceberg
Databricks has quickly become a powerhouse in the data ecosystem, catering to enterprises seeking open-source, scalable solutions that support ML and data lakehouse architectures. Apache Iceberg, a high-performance open-source table format for large analytic datasets, has been instrumental in this rise. Both Databricks and Microsoft Fabric leverage Iceberg to meet the demands of complex data operations, giving organizations the ability to unify their data for real-time, efficient processing at scale. ELT Patterns that endure will be compatible with the Databricks lakehouse-style architecture and cater to open table formats like iceberg.
AI as a Strategic Imperative According to Industry Leaders
AI has captured the spotlight over 2023–2024, with Sundar Pichai and Satya Nadella competing to mention “Data and AI” the most amount of times in the space of thirty seconds, underscoring its transformative potential. Jokes aside, Nadella pointed out that 80% of CEOs now consider AI integral to analytics strategies, while Pichai highlighted AI’s capability to turn data into actionable insights at unprecedented scales (source: *Gartner 2023 CEO Survey*). Ensuring Data on Databricks / Fabric is actionable for AI will be imperative.
AI Readiness and Cloud Adoption
Data readiness for AI has become critical, with 75% of data leaders rating AI-readiness as essential for long-term competitiveness (source: *McKinsey 2024 AI Readiness Survey*). Over 60% of organizations are now actively modernizing their data infrastructure to support cloud-native and AI-enhanced analytics. As platforms like Microsoft Fabric and Databricks continue to evolve, they are attracting enterprises that recognize the need for scalable, AI-compatible architectures — the key is support for open table formats and lakehouse architecture; at the heart of Fabric and Databricks
From Legacy to Modern ELT Solutions
As cloud migration accelerates, organizations are shifting away from traditional infrastructures to adopt dynamic, cloudnative ELT solutions that support data lakehouse architectures and advanced ML. This whitepaper explores the benefits of migrating to platforms like Microsoft Fabric and Databricks, showcasing how they are built to deliver agile, AI-driven analytics and ensure organizations stay at the forefront of data innovation. We will, in particular focus on the move from Azure and ADF-based Architectures / Databricks-legacy spark-only architecture, to combined unified lakehouses on both Databricks and MS Fabric.
Pre-2024: Traditional Azure Stack with ADF and SQL Server
A traditional set-up for a data stack on Azure would have leveraged SQL Server, SSIS and SSRS

As the cloud has proliferated, and with it, Microsoft Azure, many of these workloads have moved to cloud:

General Limitations
^ No Common standard for storage: Understanding where to store data in Azure for data use-cases was not straightforward — big data shops leveraged ADLS Gen-2, Object storage, and ran Spark themselves or on HDInsight. Smaller data, analytical use-cases were directed towards Azure Synapse, which was underwhelming and poorly supported. Azure Cosmos DB and other data stores like Azure-hosted postgres were sometimes adopted
^ Slow-to-develop BI: Although Power BI now is widely recognised as the standard for BI, this was not always the case which forced users out of the Azure ecosystem to tools like Looker, Tableau etc
^ Orchestration: companies leveraged Azure Data Factory for orchestration and ELT. This has forced large enterprises on Azure to hire large offshore teams to scale environments built atop AD
^ Lack of Data-specific tools: ideas like quality testing, transformation frameworks, enforcing data contracts, iceberg etc. were not first-class citizens in the Azure ecosystem. This meant an increasing “do-it-yourself” approach and a lack of support for open-source data-specific projects like dbt; synapse was always considered an enormous “laggard”
^ Data Quality: business users who wish to be informed of data quality alerts in real-time cannot easily write tests or get visibility into pipeline failures that are caused by data quality issues, causing them to persist and impede analytics and AI initiatives — Teams as well was not a popular choice for a system of alerting / communication for Data Operations
^ Data Ops — despite owning both Github and Azure DevOps, integrations between both platforms and Azure services created huge problems for data teams. The lack of portability of things like terraform code for CI/CD between GCP/AWS and Azure Clouds has meant that even though Microsoft should have a strategic advantage by owning two Git platforms, CI/CD for data engineers is still challenging.
Three common Azure and Databricks Patterns for 2025+
Databricks and Fabric have now plugged the gap. Power BI and Microsoft Teams have also significantly improved. This means building effective data stacks on Azure is looking more and more attractive.
Pattern 1: Big Data using Spark
Requirements: Data is large and has low latency requirements. Real-time Machine Learning (training and deployment of models) may be required. Data can be unstructured (e.g. image data).
Persona: the persona that can be leveraged to build these data pipelines is highly technical, experienced in big data processing using legacy technologies like Hadoop, and strongly akin to a software engineer
Use-case: operational. For example, the company is an energy company who needs to ingest sensor data en-masse, in realtime to provide accurate billing estimates to end consumers. Machine Learning may also be deployed for example if the company needs to provide real-time forecasts.

Ingestion: Data is large and moved to ADLS Gen-2 (Object storage) using a combination of Azure infrastructure (like VMs, Azure Event Hub), ADF, and Databricks. Streaming is probably used (e.g. Kafka).
Storage: Data is stored in .parquet or .parquet+iceberg format. This means ADLS Gen-2 can be used as a single source of truth and no additional data warehouse is required
Transformation: data is transformed using spark structured streaming and Databricks AutoLoader. Where needed, Spark is run on client Azure infrastructure (vs. in Databricks) using something like HDInsight.
Data Activation: data is activated by ML models in Databricks, dashboards in Power BI or App Services hosted in Azure
Alerting and communication: a combination of Teams, Slack and e-mail are used to keep stakeholders updated in real-time
Control Plane: legacy systems will use self-hosted Airflow as a control plane; Modern Systems use a managed platform like Orchestra. Orchestra handles pipeline building, running, data quality monitoring, data pipeline visibility and metadata.
Pattern 2: BI Use-cases on Fabric
Requirements: Data is small to large but has no low latency requirements. Batch-based, basic Data Science Models may be helpful. Data can be unstructured (e.g. image data), but would be structured before being put into a warehouse.
Persona: the persona that can be leveraged to build these data pipelines is similar to a DBA Or Analyst comfortable building out SQL Servers and stored procedures. They are analytical and capable of speaking to the business.
Use-case: Business Intelligence. For example, the company is large Financial Services Institution seeking to implement a Data Mesh so multiple people in different departments can self-serve answers to basic questions about the business such as how many loans were made in a given time period, or the relationship between customers types and gross written premia.
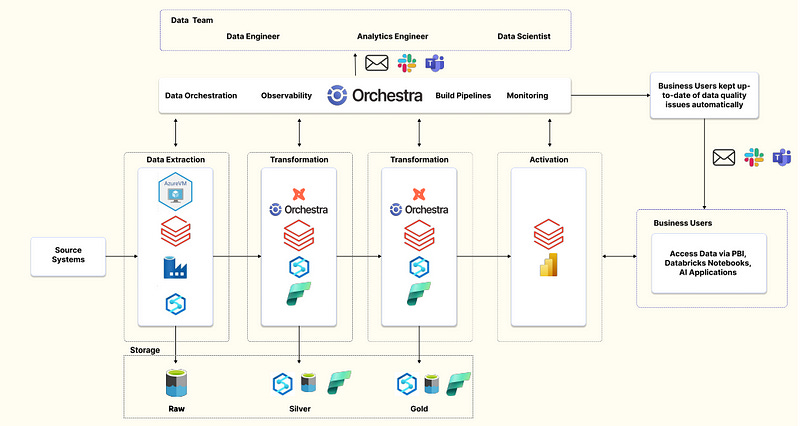
Ingestion: Data is moved to ADLS Gen-2 (Object storage) using a combination of Azure infrastructure (like VMs, Azure Event Hub), ADF, and Databricks. Streaming is probably used (e.g. Kafka).
Storage: Data is stored in .parquet or .parquet+iceberg format. This means ADLS Gen-2 can be used as a single source of truth and no additional data warehouse is required. Fabric is used as a SQL-like interface to data stored in ADLS Gen-2, which could be stored in any open table format.
Transformation: data is transformed leveraging Azure Synapse Pipelines or dbt-core using an orchestration tool like Orchestra. These tools allow SQL Developers to write SQL and automatically declare dependencies, saving valuable time. Orchestra pushes these queries down to Fabric, which executes these on the data stored in ADLS Gen-2.
Data Activation: data is activated by ML models in Databricks, dashboards in Power BI or App Services hosted in Azure
Alerting and communication: a combination of Teams, Slack and e-mail are used to keep stakeholders updated in real-time
Control Plane: legacy systems will use self-hosted Airflow as a control plane; Modern Systems use a managed platform like Orchestra. Orchestra handles pipeline building, running, data quality monitoring, data pipeline visibility and metadata.
Pattern 3: BI Use-cases on Databricks
Pattern 3 is essentially exactly the same thing as Pattern 2, with similar use-cases and requirements. However, the compute engine, that is, the computers that are pushing down data to files in Object Storage lies with Databricks instead of Microsoft Fabric.
In Essence, the developer experience and end result are exactly the same. SQL developers write SQL that is pushed down to Databricks/Fabric, which in turn execute these statements by interacting with data stored in an open table format / parquet in ADLS Gen-2. There are two key differences vs. Pattern 2:
Billing: Databricks requires you to handle the provision of compute resources in Azure (Via Azure Databricks) and the DBUs you purchase from Databricks. Fabric is a single Azure-based billing system
Additional Features: limitations exist around what can and can’t be done with SQL (or languages like Scala or Spark) in both Databricks and Fabric. Although Databricks option introduces more organisational complexity (additional provider), it is by and large accepted to be a much more mature platform than Microsoft Fabric, including features like Unity Catalogue, very strong support for Spark + ML use-cases, as well as a well-developed SQL Warehouse. You should ensure you have Databricks experience or a very good implementation partner, if you are to venture into Databricks as an enterprise without experience.
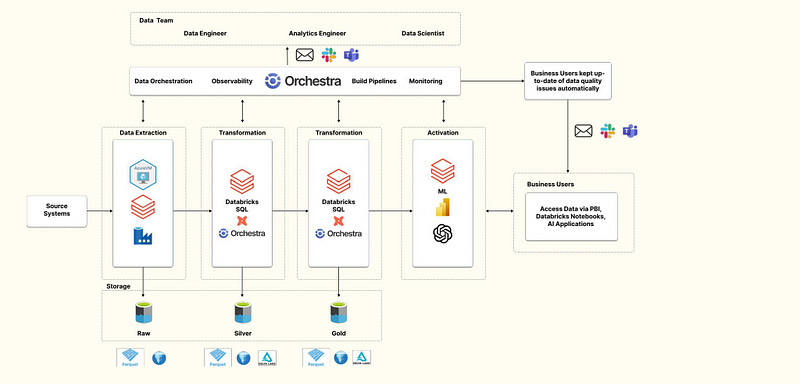
Differences to Pattern 2
Table Format: Databricks Acquired Tabular, and with it the co-creators of Iceberg. As such, they intend to make Delta Lake, Databricks’ own table format be the fast-follower to iceberg, should iceberg be the most popular choice. This means Databricks should give users better functionality around open table formats and associated functionality
Transformation engine and warehouse: rather than leverage a compute layer that is managed by Microsoft (Fabric), in this architecture you leverage Databricks SQL (not T-SQL) and the Databricks Warehouse. Databricks recently (Nov-24) released a fully-serverless option, aiming to match the seamless user experience warehouse developers can find in Fabric / Snowflake. This represents a significant departure from the world of “manage your own compute resources” which has lead to spiralling DBU costs for many enterprises in the past
Orchestration: Orchestra has a number of Databricks-specific features like dbt-databricks or exposure of all steps in a Databricks Workflow, which make maintaining data quality and retaining governance in Databricks a breeze.
Conclusion
In conclusion, adapting to modern ELT patterns on Microsoft’s platform requires a strategic approach that aligns platform choice, timing, prioritization, and architectural flexibility. By implementing solutions with a Unified Control Plane from the outset, organizations can build robust, transparent Data Products that drive real value without being bogged down by migration complexities.
Whether using Big Data with Spark, BI on Fabric, or BI on Databricks, each pattern demands careful planning around team structures, the business’s appetite for self-service, and the key use cases at hand. By prioritizing governance and a cohesive framework, Data Teams can focus on solving critical issues — like data quality, pipeline reliability, and orchestration challenges — setting a strong foundation for a successful transformation.
With the right structures in place, the migration becomes more about integrating components effectively than reengineering from scratch, ensuring smoother transitions and sustained value over time.
If you’d like to learn more about Orchestra, please head to our website or follow us on Linkedin. For migration resources, we recommend reaching out or learning more about our partners at https://getorchestra.io/partners.