
Everything must be code in the age of AI
AI radically changes how you can spend your time. Writing code is not one of them

At Orchestra we have recently undergone a paradigm shift. This paradigm shift is penetrating every industry - not just data and analytics, but software engineering, marketing, finance

Simply put, AI makes you spend less time writing code and more time reviewing it.
This has immediate knock-on effects to productivity.
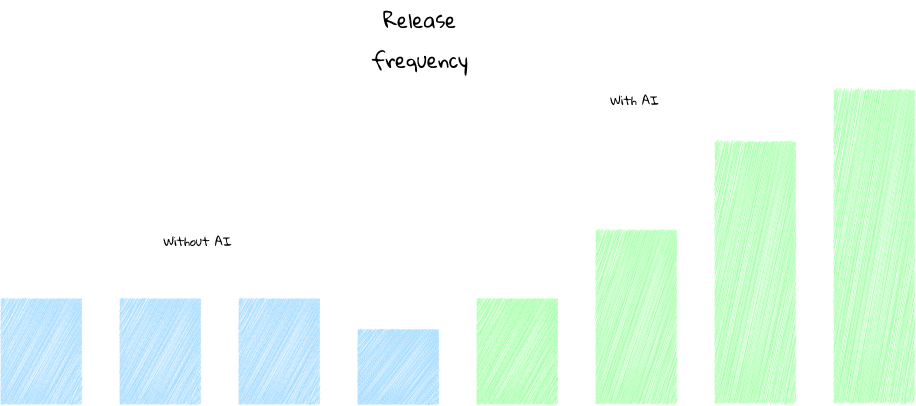
With AI writing code and humans reviewing it, the rate at which we release has increased drasticlly.
The “as-code” problem
Orchestra is a unified control plane for AI and Data Workflows. A core feature is orchestration and monitoring. If orchestration goes down, engineers are left in the dark - teams use Orchestra to eradicate that risk.
All our stuff, from code to content, needs to be extremely high quality. Therefore, it must go through review.
But this means that things without a code expression suddenly become difficult to scale under this paradigm.
If your docs are not controlled in code, how can you automate them? Sure, AI Helps, but AI is no so good at generating Code, or rather, LLMs are so good at generating text that not taking advantage of this paradigm is a mistake.
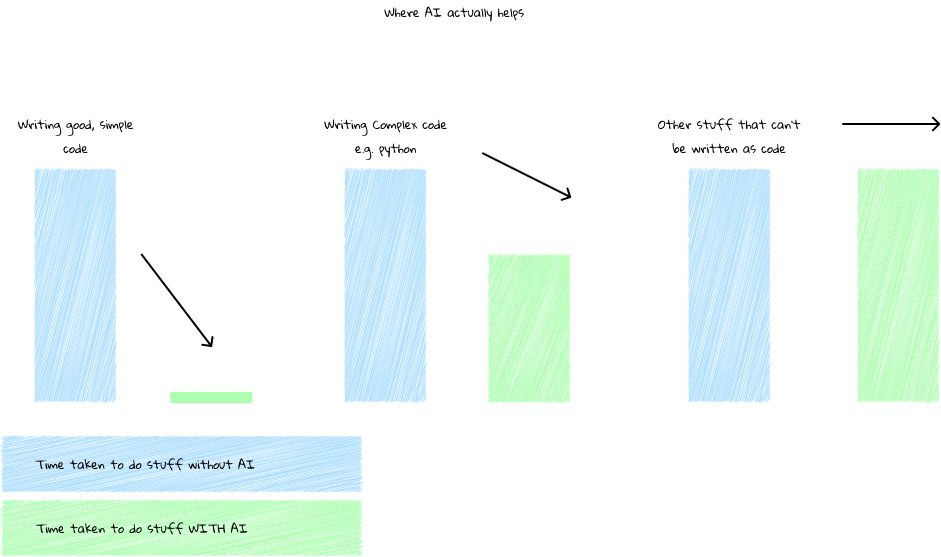
In the diagram above, you can see how writing code takes less time with AI.
However, the type of code you are writing also makes a difference.
Consider you are looking to implement an orchestrator like Airflow or Dagster, or perhaps you are an existing company with a large custom in-house build.
For example, Dojo a UK Fintech Company leverage Airflow and actually built their own version of dbt mesh within Airflow a few years ago. THey have a large data team, around 50+ and recently spent a few months migrating from Airflow 2.0 to 3.0.
Or perhaps you are a Monzo, once the hottest challenger neobank in the UK. Monzo boasts an analytics team of around 100 people, as well as their own custom version of dbt written in Go.
These code bases are complex. Generating code and releases, I would bet, is a tricky process that requires a lot of human intervention. Documentation also requires constant updates, which AI is likely to get wrong because of all the “business-specific” quirks.
How can you access the true productivity gains of AI when all the code, documentation and content needs to be extremely complex?
It is much better to have something simple. Data Architects but jesus, fucking CEOs should be trying to make their businesses as SIMPLE AS POSSIBLE since otherwise, the SQUEEZE you require to get AI to make JUICE is enormous.
There are so many examples of this
Imagine you are United Healthcare Group, the 5th largest company in the world. You want an AI to understand the knowledge base of UHG. The knowledge base is sparsely distributed, massive, and exists often in the heads of people. Enterprises with massive scale and history face the largest hurdles in implementing effective AI. It will be MUCH EASIER for companies or divisions in companies that are younger
Imagine you are a Databricks customer who works with a consultancy. In the last 2 years, you have paid the consultancy somewhere between $200k and $500k. They have someone that sits with you onsite, who has built something “custom” they “Promise is super scalable”. Perhaps it is a metadata-driven framework combining the best of Azure Data Factory and Databricks so that you redundantly have two orchestrators, or maybe they have implemented a custom dagster implementation with thousands of lines of python only they understand deployed on infrastructure with tons of quirks.
If the goal is to have AI write this code, how exactly will this work? Is it documented? Is the process of writing code automatable? What if Joe goes on holiday? Will the PRs still get reviewed?
The Complexity problem
Data People suffer from the complexity problem.
People like to overcomplicate things.
This makes them hard to maintain, difficult to scale, expensive, and slow.
With AI, stakes are actually extremely high. Whether you are using AI so you are faster, so you can screen M&A targets faster and execute DD faster and acquire companies faster, or you’re more B2C, and you simply need to respond to support faster - these things make a difference.
This is why at Orchestra I made one big fundamental mistake early on.
I assumed people wouldn’t want alerts as code.
Instead, you confiured alerts in a side panel:
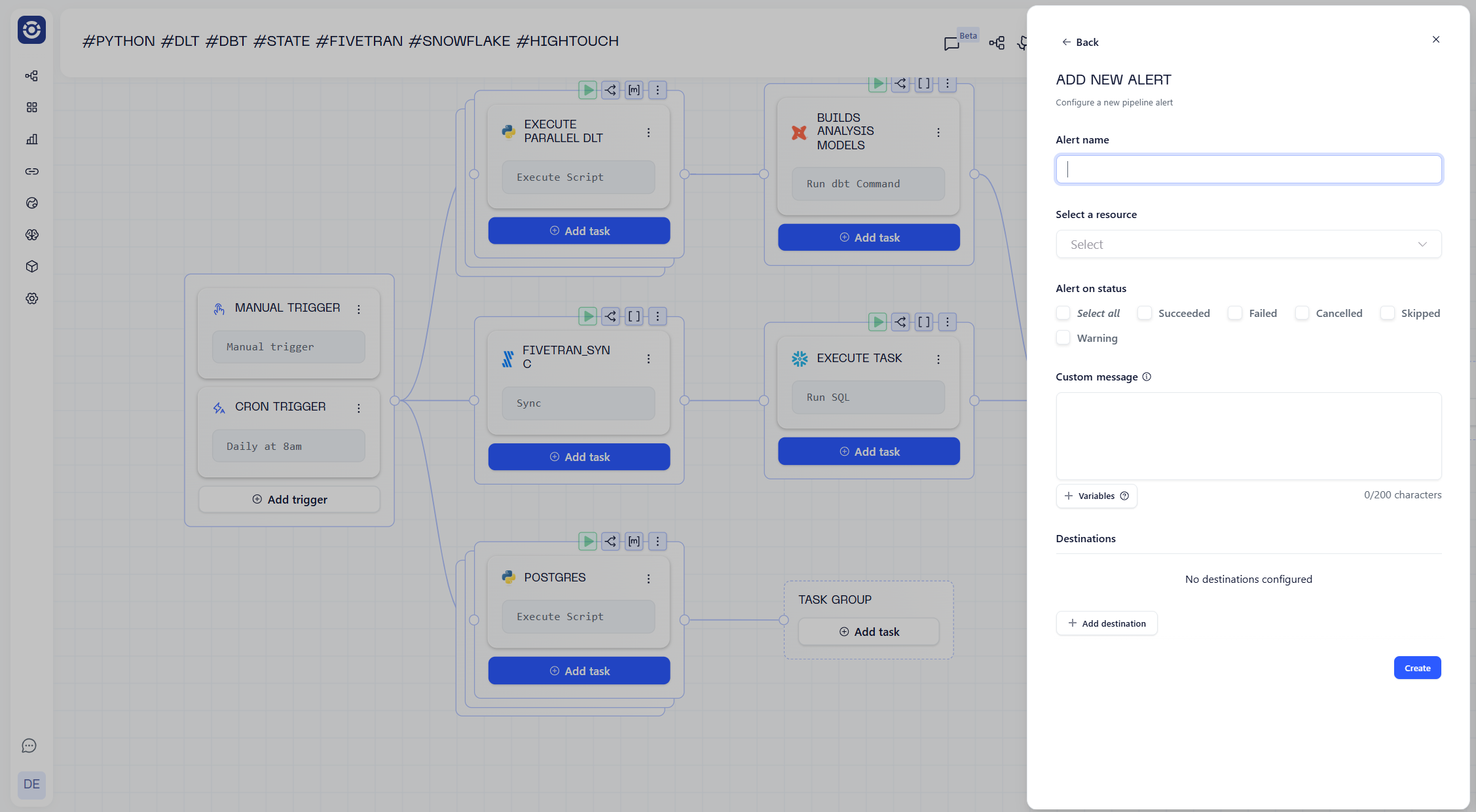
This created issues at large enterprise deployments, where users wanted to deploy pipelines entirely via code, it added friction as someone then needed to come into the UI and add the alert.
Annoying!
Now, this pipeline looks like this.
version: v1
name: '#python #dlt #dbt #state #fivetran #snowflake #hightouch'
pipeline:
8252937c-272e-440b-bb57-cf5a8df54c11:
tasks:
d3491626-3905-411e-b920-3cc5aee745b9:
integration: DBT_CORE
integration_job: DBT_CORE_EXECUTE
parameters:
commands: dbt build;
package_manager: PIP
python_version: '3.12'
use_state_orchestration: true
branch: ${{ inputs.dbt_branch }}
project_dir: dbt_projects/snowflake
shallow_clone_dirs: dbt_projects/snowflake
warehouse_identifier: JH88529.UK-SOUTH.AZURE
depends_on: []
name: builds analysis models
connection: dbt_snowflake_blueprints_prod_07025
depends_on:
- 3459fb19-f081-43ca-8997-f7f2d54d331d
name: ''
3459fb19-f081-43ca-8997-f7f2d54d331d:
tasks:
c581252f-2975-4af6-8caf-a42e30527088:
integration: PYTHON
integration_job: PYTHON_EXECUTE_SCRIPT
parameters:
package_manager: PIP
python_version: '3.12'
build_command: pip install -r requirements.txt
environment_variables: '{
"SHEET_NAME": "${{ MATRIX.gsheets[''SHEET_NAME''] }}",
"TABLE_NAME":"${{ MATRIX.gsheets[''TABLE_NAME''] }}"
}'
set_outputs: true
source: GIT
command: python -m run_dlt_pipelines
project_dir: dlt
shallow_clone_dirs: dlt
depends_on: []
name: Execute parallel dlt
connection: python__production__blueprints__19239
treat_failure_as_warning: true
depends_on: []
name: ''
matrix:
inputs:
gsheets:
- SHEET_NAME: 1H0UnZ1vJ6WSsZgiVkg96zq52p7qaXkhvodlO1Mzoj6s
TABLE_NAME: dbt_leads
- SHEET_NAME: 1TMNhQFZbmaBsa1vIehQzh3vdyfc05damwJ_PIKDF14A
TABLE_NAME: social_leads
- SHEET_NAME: 1tImqLq_zLNthL7DDUkTUjU0xHoV_PhdM1zpuJ
TABLE_NAME: unstructured_feedback
e6858647-0e86-4530-9eb2-78d080941022:
tasks:
08bc69c0-4db0-41cd-8127-9f43fde46cb1:
integration: SNOWFLAKE
integration_job: SNOWFLAKE_RUN_QUERY
parameters:
statement: Execute task kick_off_task;
depends_on: []
name: Execute Task
depends_on:
- 29aade18-ad5a-4eeb-8aca-18c25a34d549
name: ''
29aade18-ad5a-4eeb-8aca-18c25a34d549:
tasks:
b3da68b5-fb01-4617-b1a2-de3fb65ef0c8:
integration: FIVETRAN
integration_job: FIVETRAN_SYNC_ALL
parameters:
connector_id: memoranda_ing
depends_on: []
name: fivetran_sync
depends_on: []
name: ''
1e47368b-68d2-4123-9e85-ac5e29318fa2:
tasks:
fd4be19d-e0a2-49b8-8b88-c7b07024feca:
integration: HIGHTOUCH
integration_job: HIGHTOUCH_SYNC
parameters:
sync_id: '234567'
depends_on: []
name: Hightouch sync
depends_on:
- 8252937c-272e-440b-bb57-cf5a8df54c11
- e6858647-0e86-4530-9eb2-78d080941022
name: ''
schedule:
- name: Daily at 8am
cron: 0 8 ? * * *
timezone: Europe/London
webhook:
enabled: false
inputs:
dbt_command:
type: string
default: build
dbt_branch:
type: string
default: main
alerts:
- name: Failures
statuses:
- FAILED
destinations:
- integration: SLACK
destination: alert-testingThis end-to-end pipeline is c.100 lines long. It handles triggering, monitoring, alerting, gathering metadata and data assets, error handling, lineage, and of course, orchestration.
Alerts are easy. So easy, an AI could do it:
alerts:
- name: Failures
statuses:
- FAILED
destinations:
- integration: SLACK
destination: alert-testingEverything is well-documented, in our docs. Which in turn, is linked to AI.
We believe AI will make it easier to create, maintain, fix and optimise pipelines so we are ensuring everything is set-up for that.
Tools like Orchestra solve the complexity problem by balancing Governance and Control with Freedom.
Frameworks like Airflow, dagster, Prefect and to a lesser extent, dbt exacerbate this problem by allowing people to do anything. AI makes it worse, as instead of humans, you have LLMs writing slop code faster than you can review it.
Conclusion
The paradigm shift is just beginning. The productivity gains of getting AI to write code are enormous, and they are even higher when the code is good and simple.
Complex processes are the enemy of AI, as AI requires significantly more context to succeed when processes are complex. For large companies, many of this may be unavoidable, which means reaping the productivity gains from AI is likely to be costlier and slower.
For companies or teams implementing things anew, the situation is reversed, and should be easy and AI-Native from the beginning.
Avoiding key-man risk and a dependency on consultancies building in-house systems that are difficult to manage is imperative. Instead try to find advisory and training consultancies, that can support you and provide temporary capacity where necessary, rather than a consultancy that makes money by leasing labour (“Body Shops”).
If you want to read more about alerts as code, keep reading
If you’re ready to see how Orchestra enables this paradigm shift, try Orchestra here.
Migrating to Alerts-as-Code in Orchestra
Move pipeline alerts from the UI into YAML for version control, code review, and less click-ops at scale.
Alerts-as-code lets you define alerts directly in pipeline YAML, which makes it easier to apply alerting rules to pipelines consistently. This change is particularly effective for users creating new git-backed pipelines programatically.
Benefits of alerts-as-code
Less manual work — No more configuring each pipeline’s alerts one by one in the UI.
Version control — Changes go through pull requests and Git history.
Consistency — Reuse patterns across pipelines via shared YAML.
How to migrateOpen each pipeline and click Save. If there’s nothing to save, your alerts are already in YAML or the pipeline has none.Git-backed pipelines with protected default branches won’t let you save the change, so you may need to create a separate branch with alert changes, and merge it in.
Deprecation of old alerting systemFrom 30th April 2026, Orchestra will only support alerts that are managed in pipeline YAML. Alerts that aren’t migrated by then may stop working reliably.
SupportIf you need to discuss your migration, or how to get the most out of alerts-as-code, contact us.
Love it! It's a massive shift in the industry from no-code to all code. And the wild thing is that it actually allows us to write this code without writing code at all.