
Github Actions vs. Orchestration Tools | When to move on
Time to level up


Foreword
Some of the biggest pains we see facing data engineers and analytics engineers is that they spend too much time maintaining boilerplate infrastructure, and still have no visibility into pipeline failures.
It means you’re constantly fighting fires and don’t have time to focus on building. What’s worse is that the business doesn’t trust the data.
At Orchestra we’re building a Unified Control Plane for Data Ops. A Data Status page if you like, with some incredible features to give data teams their time back so they can focus on building. You can try it now, free, here.
Introduction
About a year ago I wrote a tongue-in-cheek article suggesting Github Actions was the ultimate orchestration tool.
About 10% of people sent me angry messages
“No you fucking idiot. Github Actions is not meant for that! You need to use a proper dedicated tool”
Clearly the sarcasm was not obvious enough.
The other 90% thought
“Oh yeah, not a bad idea at all”
Which kind of made me despair a little, but I kinda get it.
If you don’t need to throw in a big horrible orchestrator like Airflow in the beginning, why bother? Observability, Catalogs, Data Quality etc. they’re all extra bits of stuff that mean if you’re a fast-growing lean data team they’re very much ancilary to building good architecture.
Well after speaking to plenty of folks that have made this mistake, and have been burned by it, I am here to share a few stories you might enjoy.
Story 1: “They just don’t take the data function seriously”
I was speaking to an Analytics Lead at fintech in London the other day. They’ve scaled things really nicely, but something they said stuck with me.
“They just don’t take the data function seriously”.
Turns out they had some serious trust issues with the data. Stakeholders, that is. Indeed, with github actions as an orchestrator they scaled to 10, then 20 different pipelines. They ran dbt core in it. Need to get some data from an API using Python? Fuck it run it in a github actions runner.
Unsurprisingly stuff broke. All the time. And this Analytics Lead was having a really hard time not only fixing stuff but also convincing stakeholders the data was trustworthy in the first place.
We solved this problem for a VC (you can see the case study here).
there were a few key points
Time wasted spinning up infrastructure
Git Runners need to be tweaked and configured for different roles, which was time-consuming and painful
Time wasted writing custom adapters and actions
Every time you want to run a new thing in Github actions, like running dbt core, you need to basically write a custom adapter or actions, which when written in github syntax is painful
Here’s an example from Open AI that probably doesn’t work that shows how you trigger something in Snowflake from Github ACtions. looks fun.
name: Run Snowflake Task and Poll
on:
workflow_dispatch:
inputs:
timeout_seconds:
description: "Overall timeout for polling (seconds)"
required: false
default: "3600"
poll_interval_seconds:
description: "Polling interval (seconds)"
required: false
default: "15"
jobs:
run-task:
runs-on: ubuntu-latest
env:
SNOWFLAKE_ACCOUNT: ${{ secrets.SNOWFLAKE_ACCOUNT }}
SNOWFLAKE_USER: ${{ secrets.SNOWFLAKE_USER }}
SNOWFLAKE_ROLE: ${{ secrets.SNOWFLAKE_ROLE }}
SNOWFLAKE_WAREHOUSE: ${{ secrets.SNOWFLAKE_WAREHOUSE }}
SNOWFLAKE_DATABASE: ${{ secrets.SNOWFLAKE_DATABASE }}
SNOWFLAKE_SCHEMA: ${{ secrets.SNOWFLAKE_SCHEMA }}
SNOWFLAKE_TASK: ${{ secrets.SNOWFLAKE_TASK }}
# Provide exactly one auth method:
SNOWFLAKE_PASSWORD: ${{ secrets.SNOWFLAKE_PASSWORD }} # optional
SNOWFLAKE_PRIVATE_KEY: ${{ secrets.SNOWFLAKE_PRIVATE_KEY }} # optional (PEM)
SNOWFLAKE_PRIVATE_KEY_PASSPHRASE: ${{ secrets.SNOWFLAKE_PRIVATE_KEY_PASSPHRASE }} # optional
steps:
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install Snowflake connector
run: |
python -m pip install --upgrade pip
python -m pip install snowflake-connector-python cryptography
- name: Trigger task and poll for completion
env:
TIMEOUT_SECONDS: ${{ inputs.timeout_seconds }}
POLL_INTERVAL_SECONDS: ${{ inputs.poll_interval_seconds }}
run: |
python - << 'PYCODE'
import os, sys, time, datetime
import snowflake.connector
# --- Helpers ---
def q_ident(s: str) -> str:
# Safely quote identifiers: "db"."schema"."name"
return '"' + s.replace('"', '""') + '"'
def now_utc():
return datetime.datetime.now(datetime.timezone.utc)
# --- Config ---
account = os.environ["SNOWFLAKE_ACCOUNT"]
user = os.environ["SNOWFLAKE_USER"]
role = os.environ["SNOWFLAKE_ROLE"]
wh = os.environ["SNOWFLAKE_WAREHOUSE"]
db = os.environ["SNOWFLAKE_DATABASE"]
sch = os.environ["SNOWFLAKE_SCHEMA"]
task_name = os.environ["SNOWFLAKE_TASK"]
timeout_s = int(os.environ.get("TIMEOUT_SECONDS", "3600"))
interval = int(os.environ.get("POLL_INTERVAL_SECONDS", "15"))
password = os.environ.get("SNOWFLAKE_PASSWORD")
pk_pem = os.environ.get("SNOWFLAKE_PRIVATE_KEY")
pk_pass = os.environ.get("SNOWFLAKE_PRIVATE_KEY_PASSPHRASE")
# --- Build connection kwargs ---
conn_kwargs = dict(
account=account,
user=user,
role=role,
warehouse=wh,
database=db,
schema=sch,
client_session_keep_alive=False,
)
if pk_pem:
# Key-pair auth
from cryptography.hazmat.primitives import serialization
from cryptography.hazmat.backends import default_backend
key = serialization.load_pem_private_key(
pk_pem.encode("utf-8"),
password=(pk_pass.encode("utf-8") if pk_pass else None),
backend=default_backend(),
)
private_key_bytes = key.private_bytes(
encoding=serialization.Encoding.DER,
format=serialization.PrivateFormat.PKCS8,
encryption_algorithm=serialization.NoEncryption(),
)
conn_kwargs["private_key"] = private_key_bytes
elif password:
# Password auth
conn_kwargs["password"] = password
else:
print("ERROR: Provide either SNOWFLAKE_PASSWORD or SNOWFLAKE_PRIVATE_KEY", file=sys.stderr)
sys.exit(2)
# --- Connect ---
print("Connecting to Snowflake...")
ctx = snowflake.connector.connect(**conn_kwargs)
cs = ctx.cursor()
try:
# Capture a start marker (UTC)
cs.execute("SELECT CURRENT_TIMESTAMP()::TIMESTAMP_TZ")
start_marker = cs.fetchone()[0]
print(f"Start marker (UTC): {start_marker}")
# Execute the task once (independent of schedule/suspension)
qualified = f'{q_ident(db)}.{q_ident(sch)}.{q_ident(task_name)}'
exec_sql = f"EXECUTE TASK {qualified}"
print(f"Executing: {exec_sql}")
cs.execute(exec_sql)
# EXECUTE TASK itself returns immediately; the task run will be scheduled.
# Poll task history
deadline = now_utc() + datetime.timedelta(seconds=timeout_s)
last_seen_state = None
last_seen_qid = None
poll_sql = """
SELECT state, completed_time, scheduled_time, query_id
FROM TABLE(INFORMATION_SCHEMA.TASK_HISTORY())
WHERE database_name = %s
AND schema_name = %s
AND name = %s
AND scheduled_time >= %s
ORDER BY scheduled_time DESC
LIMIT 1
"""
while now_utc() < deadline:
cs.execute(poll_sql, (db, sch, task_name, start_marker))
row = cs.fetchone()
if row:
state, completed_time, scheduled_time, query_id = row
if state != last_seen_state:
print(f"[{scheduled_time}] state={state} query_id={query_id}")
last_seen_state = state
last_seen_qid = query_id
if state in ("SUCCEEDED", "FAILED", "CANCELED"):
print(f"Final state: {state}")
if state == "SUCCEEDED":
sys.exit(0)
# Fetch error details if available
if last_seen_qid:
try:
cs.execute("SELECT status, error_code, error_message FROM TABLE(INFORMATION_SCHEMA.QUERY_HISTORY_BY_QUERY_ID(%s))", (last_seen_qid,))
qrow = cs.fetchone()
if qrow:
status, errc, errmsg = qrow
print(f"Query status: {status}")
if errc or errmsg:
print(f"Error code: {errc}\nError message: {errmsg}")
except Exception as e:
print(f"Warning: could not fetch QUERY_HISTORY details: {e}", file=sys.stderr)
sys.exit(1)
# Not finished yet; wait a bit
time.sleep(interval)
print(f"Timeout after {timeout_s} seconds without terminal state.", file=sys.stderr)
if last_seen_qid:
print(f"Last observed QUERY_ID: {last_seen_qid}")
sys.exit(124) # timeout exit code
finally:
try:
cs.close()
except Exception:
pass
try:
ctx.close()
except Exception:
pass
PYCODETime wasted debugging
Github Actions doesn’t retain any metadata, so debugging stuff is super painful and you need to look into multiple different places
Wasted Cost
Github Actions doesn’t have great retry from failure mechanisms for sub-processes, especially things like dbt, so it meant every time something failed (which was a lot) everything got materialised again, leading to wasted $$ cost
Lack of trust (topline impact) and lack of visibility
Constantly failing pipelines and no central place to see if “data is fresh” meant stakeholders did not trust this Lead’s data. That trust is hard, and they said there were a bunch of awesome, high value data intiaitives like lead scoring the business just ended up getting on with and finding another way to do instead of using the data team
Story 2: “Jack and Jill went up the hill, built something horrendous, and went on holiday”
It all sounds rosy when you hire a kick-ass data engineer who promises they have a “sick idea” for how they can get a really nice customisable system.
They spend a few months building things and then everything works. But as soon as they go on holiday there’s an error and you open pandora’s box trying to debug this stuff

Github Actions is NOT built for releasing data. It is built for releasing code, for review by software engineers. Forcing data constructs onto github Actions at scale is impossible, because it means there are no guidelines and modules for things like alerting, metadata aggregation, what to do on failure, dashboards, logging etc. all end up being written in the actions themselves, which makes debugging tricky.
More time wasted debugging
Difficult to debug a system built by what inevitably becomes only few people
Lack of scalability
No way to make git actions extensible for common modules like alerting, metadata aggregation, ownership etc. Human organisational pattern necessitates only a couple of people working and knowing the system, limiting the scale of the data team.
Massive risk / trust
When someone goes on holiday there is inevitably an amount of risk brought into the process which can lead to broken data and damaged trust
5 Considerations before you build an Orchestration and Monitoring framework
Story 3: “These numbers don’t look right”
A common train of thought is as follows:
We don’t have many pipelines or people using the data, so I’ll just do some stuff manually for now
It doesn’t matter if stuff fails a little bit, people only use the dashboards a bit
After there is more demand forour services, we’ll think about scaling then
After seeing hundreds if not thousands of data team implementations, this is an error. I know this — I made it myself.
It’s only a problem if someone notices? Why Data Teams need to recalibrate
There is a chicken and egg problem here. You think it suffices to have a basic set-up and that actually damages yourself. You need to have ambition. you need to make things tight knit. Otherwise, how do you expect people — people that are less technical and probably much less smart than you — to trust you?
Fundamentally, you want them to use data. They don’t today. Which means they have to trust and like you. If your data pipelines run in Github Actions, they will likely be flaky, and it will cause distrust.
My point is, you have to build to above the level you’re going to be in the short term. Don’t over-engineer and build netflix from day 1, I’m not saying that. But don’t just start by doing everything manually in excel on the grounds people aren’t using data that much.
Remember — it is YOUR responsibility to create change in the organisation. It’s not going to come to you.
Bonus: build something cool
Fundamentally you’re not winning any prizes for running stuff in Github Actions.
Sure, you might save your employer a few quid but you’re also learning to do stuff in a really hacky way. It’s a bit like getting really good at putting together IKEA furniture. You might be able to quickly furnish your home but fundamentally if you’re interested in furniture making and don’t want your place to look like a wework, you’d probably be rather spending your time elsewhere.
Orchestration is fucking cool. You can run data pipelines but you can also run agents, automate metadata collection, automatically identify the root causes of errors and alert people who own the data, eliminating the super painful manual triage and the nagging “Hey can you check this number for me?” requests.
Orchestrators also have a fuck-ton of metadata that allow you to use AI to build and orchestrate pipelines.
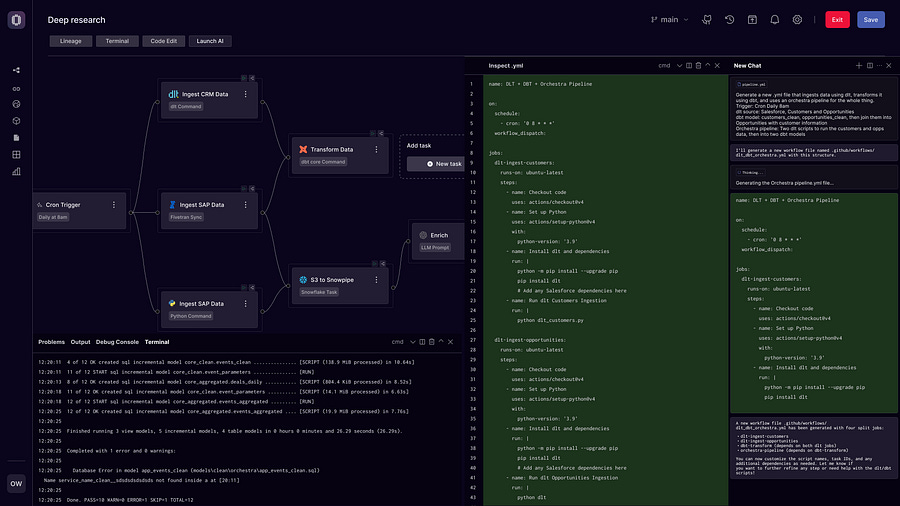
this is the future. Now instead of hiring 3 data engineers to build a dashboard they can build 10 dashboards and a 100 AI automation workflows that menaingfully contirbute to the business.
You’re not going to do this running Github Actions.
The real cost isn’t in the time you’re wasting — it’s in all the awesome stuff you would be doing if you weren’t having to coerce Github Actions into being a data pipelining tool.
Conclusion
As you can tell, I have pretty strong opinions about this so take this with a grain of salt.
Fundamentally, I totally get why people start orchestrating things with github actions. It’s more convenient, easier to learn, and faster to set-up than something like Airflow.
But now with tools like Orchestra, you get something which is
Rapid to set-up
Easier to maintain
Built for Data and AI workflows and therefore SCALABILITY
Powered BY AI
Pretty cheap
Has built-in Governance
Plus, if you must insist on using Github runners, why not trigger them from orchestra.
I’ve been speaking to data teams about this for the last 4 years and I’ve met many folks who started out in the industry that are now leading data teams. It is pretty telling that almost ALL of them regret sticking with Github Actions for too long, and over-engineering solutions.
So — do yourself a favour and start the infrastructure off on the right foot! Remember, if there’s one thing your employer doesn’t care about, it’s saving a few quid running things on Github Actions.
You can use Orchestra for free here.
Find out more about Orchestra
Orchestra is a unified control plane for Data and AI Operations.
We help Data Teams spend less time maintaining infrastructure, make them proactive instead of reactive, and ultimately win trust in data and AI from the Business
We do this by consolidating Orchestration with monitoring, data quality testing, and data discovery. You don’t need an observability, lineage, catalog etc. with Orchestra.
Check out