


High Quality data is a pre-requisite for Generative AI, but not how you think it is
Seems counter intuitive but hear me out


There is this quite tiresome polemic going on that high quality data is required for success with Gen-AI. This is used to sell things like Data Contracts, ex-post Data Observability tools, and standalone Data Quality tools that help people write tests en-masse thereby incurring huge costs in data warehouses.
Something interesting I touched on here was how there are some distinct patterns that are emerging when it comes to Data, AI and ML.
One such pattern is the pattern of an “AI Engineer”.
An AI Engineer is not someone that used to be a data engineer. Rather, AI Engineers tend to be software engineers who are tasked with leveraging Artifical Intelligence in an application.
They are, generally, using this to facilitate operational use-cases; customer or client-facing features, external to a company, operating under a strict SLA where accuracy, monitoring, and the like are imperative for success (unlike many internal business data processes).
For these AI engineers, Data is accessed where it resides relative to a software application. They’re not going into BigQuery, Snowflake or Databricks to build their applications; they’re going into a SQL Server, an Object Store like S3 or perhaps an RDS Postgres instance somewhere.
And the point I am getting to, is that Data Contracts (at least in the sense of what we speak about in the data community), data quality testing tools, observability tools and so-on are marketed and geared towards DATA ENGINEERS. Yet those folks actually building the AI right now just aren’t in that camp.
AN AI engineer who writes an application to fine-tune an LLM based on some data sitting in an RDS Instance has no use for a third party piece of SAAS that runs a shit load of select statements on your Snowflake Warehouse and surfaces these in a UI.
OK - so what about AI in Data?
Good point - so that’s “Pattern 1: AI Engineering”.
The second “pattern” or thing people do commonly is Data Engineering and Analytics for Business Intelligence.
This is the domain of data warehouses, dbt, and whatnot.
However - think about the struggles we all face to sufficiently educate the companies we work for to even be able to digest a BI Dashboard or perhaps an automated data with some interesting information in it.
Will we really find ourselves, as data engineers and analytics engineers and BI specialists sitting on the end of feature requests for AI-powered Applications when the business cannot even decide upon a definition of a metric like revenue? Are we even there yet?
It is a bit like trying to get someone to eat an oyster who won’t eat white fish.
So the point here, is that in the second “Pattern”, where the rhetoric around data quality does have some intuitive merit, it’s still sort of irrelevant unless you’re one of the 1% of organisations that has a really well-functioning data team (in which case, you probably built out data quality monitors into your pipelines a long time ago).
In any event - if you did want to see how to stitch up something like AWS SageMaker to dbt or Snowflake with an end-to-end pipeline, you can check out the article below.
Happy Camping!
Hugo
How to Connect ML Models in AWS Sagemaker to Snowflake and dbt
Machine Learning and Gen AI in the Modern Data Stack
Introduction
AWS Sagemaker is AWS’ Machine Learning Suite. With the advent of AI, AWS have intelligently added LLM capabilities to Sagemaker.
Sagemaker supports a wide range of LLMs including Dolly, Falcon, Llama2, and Mistral-7B. However, it doesn’t yet support Claude, which needs to be accessed through AWS Bedrock.
For Analytics practitioners, working out how to access LLMs and other Machine Learning models from data warehouses such as Snowflake and connect end-to-end jobs with data modelling frameworks like dbt is imperative for activating Generative AI in the Analytics Layer. In this article, we’ll show you how.
A basic Data Pipeline
A basic data pipeline for LLM fine-tuning would involve moving data to Snowflake or S3, transforming it using dbt or Coalesce, and running data quality tests. This is depicted below:

These clean data sets can be used for fine-tuning LLMs.
Use Snowflake as a data source to train ML models with Amazon SageMaker
I lift heavily from the AWS Solutions Architecture blog here. In this example, we’ll use a regular ML model as an example and we can see how this compares to an LLM Fine-tuning job.
The overall Architecture is depicted below:
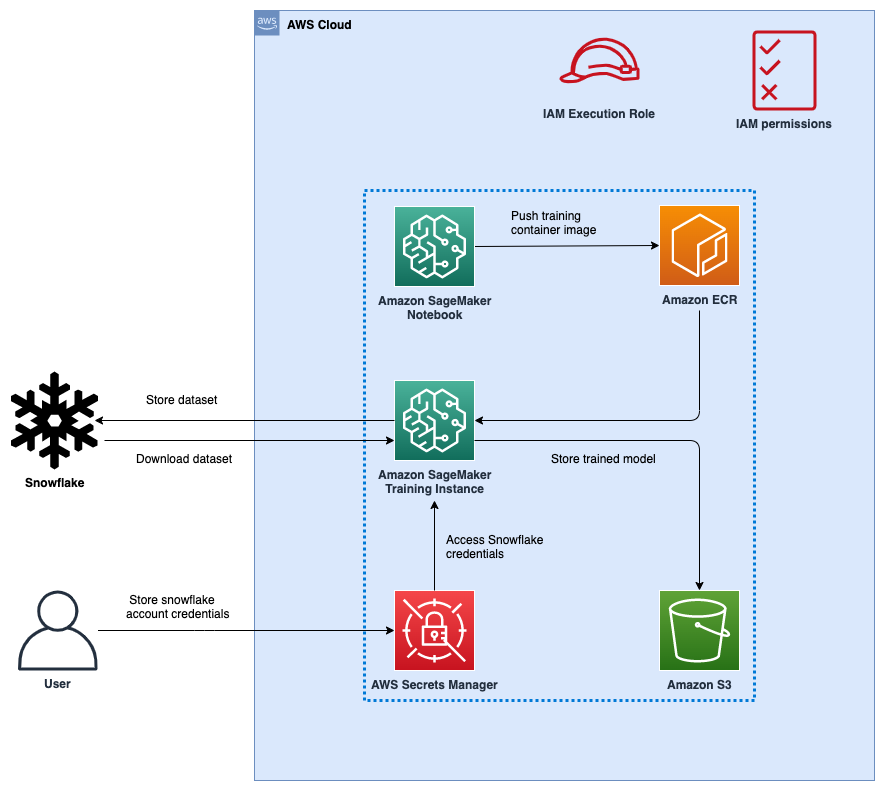
Step 1: set-up the AWS SageMaker Notebook
The SageMaker Notebook is a git-controlled python repository that is the code that has both the data fetching and training logic. An example of the code you would use is below:
import pandas as pd
import snowflake.connector
def data_pull(ctx: snowflake.connector.SnowflakeConnection, table: str, hosts: int) -> pd.DataFrame:
# Query Snowflake table for number of table records
sql_cnt = f"select count(*) from {table};"
df_cnt = pd.read_sql(sql_cnt, ctx)
# Retrieve the total number of table records from dataframe
for index, row in df_cnt.iterrows():
num_of_records = row.astype(int)
list_num_of_rec = num_of_records.tolist()
tot_num_records = list_num_of_rec[0]
record_percent = str(round(100/hosts))
print(f"going to download a random {record_percent}% sample of the data")
# Query Snowflake HOUSING table
sql = f"select * from {table} sample ({record_percent});"
print(f"sql={sql}")
# Get the dataset into Pandas
df = pd.read_sql(sql, ctx)
print(f"read data into a dataframe of shape {df.shape}")
# Prepare the data for ML
df.dropna(inplace=True)
print(f"final shape of dataframe to be used for training {df.shape}")
return dfHere we define a data_pull method that connects to Snowflake and fetches the data as a data frame. This is a random sample of the data, as that is what must be leveraged for fine-tuning or model-training in general.
Step 2: set-up credentials and Data Prep
There are some additional steps in the code that can be found in the AWS Sagemaker Github code repo. These would include:
Fetching the Snowflake Secrets from AWS Secrets Manager
Defining the Data Preparation steps after data has been fetched from Snowflake
Determining things like Hyperparameters
Step 3: set-up the AWS SageMaker Fit step
The final step, which is of interest to us, is the command where the notebook trains the model:
import boto3
import sagemaker
from sagemaker import image_uris
from sagemaker import get_execution_role
from sagemaker.inputs import TrainingInput
from sagemaker.xgboost.estimator import XGBoost
role = get_execution_role()
sm_session = sagemaker.Session()
bucket = None #optionally specify your bucket here, eg: 'mybucket-us-east-1'; Otherwise, SageMaker will use
#the default acct bucket to upload model artifacts
if bucket is None and sm_session is not None:
bucket = sm_session.default_bucket()
print(f"bucket={bucket}, role={role}")
prefix = "sagemaker/sagemaker-snowflake-example"
output_path = "s3://{}/{}/{}/output".format(bucket, prefix, "housing-dist-xgb")
custom_img_name = "xgboost-ddp-training-custom"
custom_img_tag = "latest"
account_id = boto3.client('sts').get_caller_identity().get('Account')
# collect default subnet IDs to deploy Sagemaker training job into
ec2_session = boto3.Session(region_name=region)
ec2_resource = ec2_session.resource("ec2")
subnet_ids = []
for vpc in ec2_resource.vpcs.all():
# here you can choose which subnet based on the id
if vpc.is_default == True:
for subnet in vpc.subnets.all():
if subnet.default_for_az == True:
subnet_ids.append(subnet.id)
# Retrieve XGBoost custom container from ECR registry path
xgb_image_uri = image_uris.retrieve('xgboost', region, version='1.5-1')
print(f"\nusing XGBoost image: {xgb_image_uri}")
# Create Sagemaker Estimator
xgb_script_mode_estimator = sagemaker.estimator.Estimator(
image_uri = xgb_image_uri,
role=role,
instance_count=instance_count,
instance_type=instance_type,
output_path="s3://{}/{}/output".format(bucket, prefix),
sagemaker_session=sm_session,
entry_point="train.py",
source_dir="./src",
hyperparameters=hyperparams,
environment=env,
subnets = subnet_ids,
)
# Estimator fitting
xgb_script_mode_estimator.fit()This is the juicy part of Sagemaker — by leveraging a model for training (in this case XGBoost) that’s in a container image and passing this as a parameter to the sagemaker estimator, you simply need to provide the relevant parameters (for model training and infrastructure) and call the “fit()” method to produce a model.
The result of this is that the trained model will be available in your chosen S3 bucket.
How to run an AWS Sagemaker Job on a schedule
A common use-case once models are performing well is to run training jobs on a schedule.
Models decay — if new data arrives over the course of the week that means a model from a week a go is no longer a good predictor, a new model will need to be trained and deployed to ensure models in production do not decay as well, leading to sub-optimal business outcomes.
Fortunately, by nesting all the above code in a single python file, this is essentially a Sagemaker Training Job, that can be called at any time using this endpoint.
This can be done in Python, which naturally means you should be using a Python-based Orchestration tool like Airflow, or a managed service with a Sagemaker integration like Orchestra.
An illustration of the new data pipeline which connects AWS Sagemaker to the existing data pipeline is below:

What about LLMs?
LLMs are not available under the aforementioned endpoint, however a fine-tuning job follows the same architectural structure.
Instead of calling the SageMaker Training job, you would call the CreateAutoMLJob endpoint.
Conclusion
In this article, we covered how to connect Amazon Sagemaker to Snowflake which is a popular data warehouse. With Generative AI promising to democratise LLMs for all organisations, the question is no longer, if, when, but how.
One approach is to use data that is owned by analytics teams as a basis for fine-tuning LLMs. This would be powerful for use-cases such as email analysis, internal documentation or code-scanning.
We demonstrated how this data can be imported from Snowflake directly into a container in AWS and used to train a Machine Learning model or fine-tune an LLM. This can then happen periodically through access to AWS Sagemaker via the API, which would be handled by an Orchestration tool.
This presents a really big opportunity for data analysts and engineers. Instead of just providing Data-as-a-product, these teams now have everything they need to deploy ML models and LLMs. Provided organisations are ready for this, it’s an exciting time to be working in data🚀
Learn more about me
Hugo Lu is the co-founder and CEO of Orchestra, the Unified Control Plane for Data Operations.