


How to set up an AWS lambda function | Lambdas for Data Engineers
AWS lambda offers a lot of power for Data Engineers. In this article, we explore the basics and how Data Teams should leverage serverless


Substack note
Just a few takeaways here as the below is a fairly noddy instructional how-to article
If your team wants to use python, stuff like Lambdas, you had better be comfortable letting them into AWS and having a conversation with them about CI/CD and/or the nuances between dev prod and staging. This is probably the most complicated thing, conceptually, in data and one of the biggest technical differences between data and software engineering.
If you think they won’t get this, then running python at scale, robustly, may be something you need to think about (i.e. go managed)Lambdas are really powerful but they’re not for everything. They’re short-lived, and don’t scale vertically but horizontally (i.e. one worker can’t suddenly 10x its memory, RAM etc. but you can very quickly go from 1 to 10 workers, provided they’re doing different independent things).
So very good for A) multiple API calls to the same place where you don’t getrate limited and know what those API calls are and B) running lots of processes that are maybe calling separate APIs in parallelLambdas are really good for streaming / event-based stuff
That’s all for now! More on use-cases for AWS lambda for data teams to come.
Introduction
Serverless computing is a cloud service that allows developers to run code without having to manage the underlying infrastructure. The cloud service provider automatically handles the infrastructure, such as provisioning, scaling, and managing, so developers can focus on business logic
AWS’ implementation of this is called AWS Lambda. It provides data teams with an easy way to implement and run python code in production. This is normally used for ad-hoc workloads or ELT.
In this article we will show how to set-up an AWS Lambda Function and talk about some of the use-cases for Data Teams. We’ll also briefly discuss the limitations of AWS Lambda and what they should / shouldn’t be used for. We’ll also spend some time answering some common questions data folks have about AWS lambda.
Let’s dive in!
Structuring a Git Repository for AWS Lambda
The first thing to bear in mind is how to set-up a Git Repository for an AWS lambda function.
An AWS Lambda function or serverless function is designed to be a short-lived process that can be executable on given memory and storage requirements.
This means you will effectively define a function or series of functions in Python to be called by your Lambda.
The simplest set-up is like this:

Firstly you need a .yaml file which will tell your git provider what to do when you push changes to your Lambda. Here we are using Github, so the file needs to be in the \workflows folder.
Second — settings.json for your VSCode environment which should be gitignored (last box).
Also add a Read Me if you are so inclined.
Finally — the Lambda function itself.
Generally the folder structure can be anything here. I would always start simple — one folder per Lambda with a main.py file inside. You can make this as complicated as you like.
Main.py for AWS lambda
The Hello World example for AWS lambda is per below
import json
def lambda_handler(event, context):
# TODO implement
return {"statusCode": 200, "body": json.dumps("Hello from Lambda!")}More information on the required parameters can be found in the AWS Documentation for AWS lambda here. You need the event and context. To paraphrase:
The first argument is the event object. An event is a JSON-formatted document that contains data for a Lambda function to process. The Lambda runtime converts the event to an object and passes it to your function code. It is usually of the Python
dicttype. It can also belist,str,int,float, or theNoneTypetype.The event object contains information from the invoking service. When you invoke a function, you determine the structure and contents of the event. When an AWS service invokes your function, the service defines the event structure. For more information about events from AWS services, see Invoking Lambda with events from other AWS services.
The second argument is the context object. A context object is passed to your function by Lambda at runtime. This object provides methods and properties that provide information about the invocation, function, and runtime environment.
Really this code can be anything which is great. More on this later.
Setting up the Lambda function in AWS
This is boring but I include it for completeness.
Unintuitive: go to IAM first:
You will need to create:
A user for accessing the Lambda Function
A Group for the user to be in
A policy the group has access to
You can give users policies / permissions directly; this is not recommended.

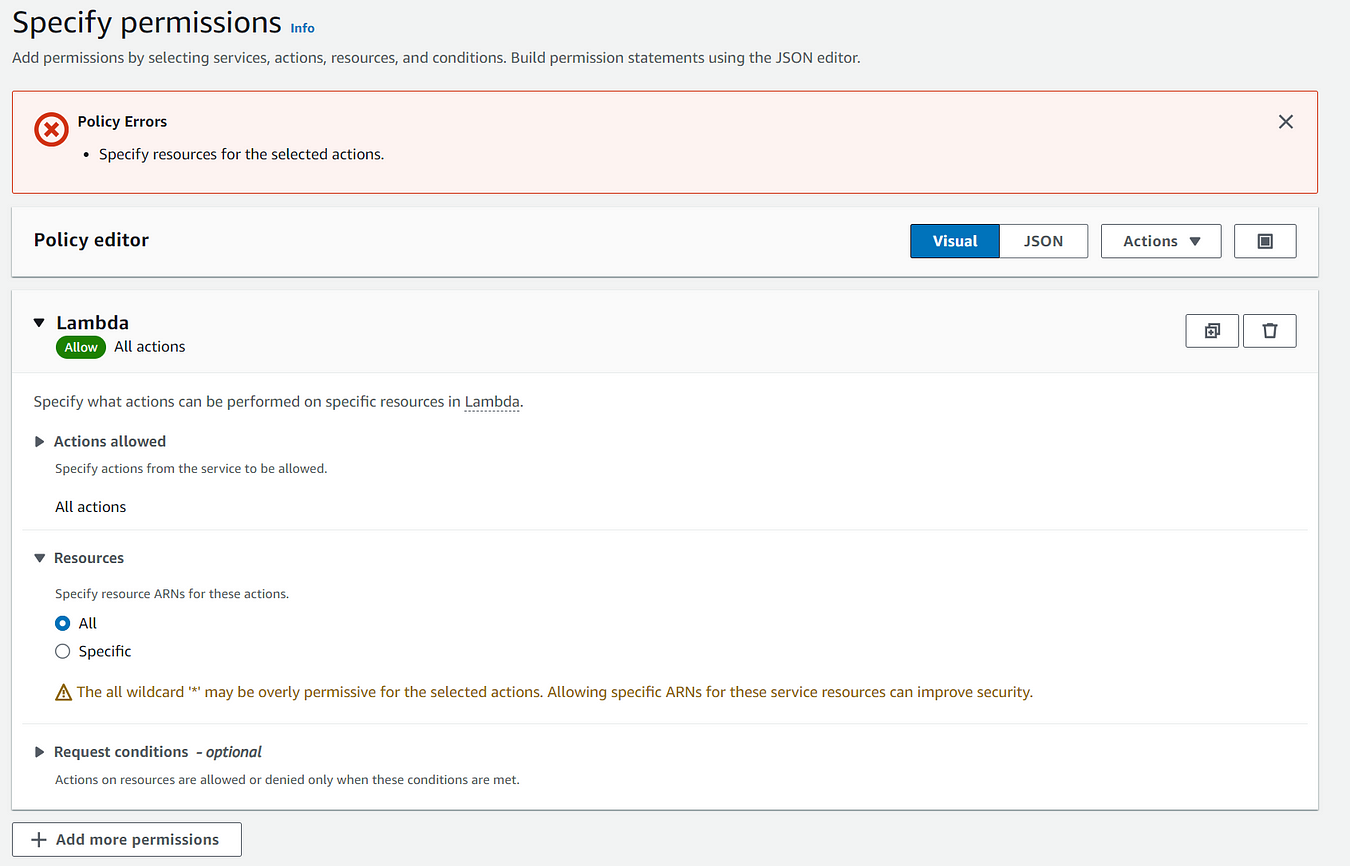
You could use the AWS Lambda Policy which is AWS managed. All this means is AWS have already decided what permissions the policy has. Otherwise, create one yourself, it will look something like this:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"lambda:GetFunctionConfiguration",
"lambda:InvokeFunction",
"lambda:UpdateFunctionCode",
"lambda:UpdateFunctionConfiguration",
"lambda:CreateFunction",
"lambda:DeleteFunction"
],
"Resource": "[]"
},
{
"Effect": "Allow",
"Action": [
"iam:PassRole"
],
"Resource": "arn:aws:iam::[number]:role/*"
}
]
}Save this and return to it later. If you already created your lambda, you may not have square brackets in the above you’ll need to change.
The next step is to create the Lambda. Search for Lambda in the console, and create one from scratch. Make sure the python version you’re using is the same as on the Github runner and ideally your local computer
Correct the .yml file on the policy with the newly-created AWS Function’s name and you are now good to go. The reason we did it this way around was because if you were being really automated and doing this all in terraform, you would need the policy created first as the terraform would handle creation / updates / deletion to the lambda.
Deploying the code from Git to AWS Lambda
For Data Engineers and Analytics Engineers, this is probably the most daunting part of the process.
Whereas it is straightforward for anyone to understand a .sql or a .py file, understand wtf is actually going on under the hood of a github actions yml file is a bit harder, conceptually. Let’s take a look at the one I’ve used to deploy a lambda.

A .yml file here is an abstraction over code that is going to be run on a machine (a github actions runner, in this case). Every dash (so -uses, -name etc.) refer to a single step or thing you’ll do on the computer. This could be as simple as running a bash command, or making a series of api requests.
Actions checkout — this checks out the code from Git onto a runner. Similar to doing the below in BASH:
git clone - depth=1 <repository-url> .
git fetch - depth=<specified-depth> origin <ref>
git checkout <commit-sha or branch/tag name>or
GET /repos/:owner/:repo/git/ref/heads/:branch
GET /repos/:owner/:repo/pulls/:pull_numberset-up Python: what is this “uses” block? What does that actions/@setup-python@v4 mean? Well — these are essentially mappings from arbitrary strings to code steps. There is a marketplace for actions where you can search for them (see here)
Install Dependencies — installs the dependencies ina requirements.txt file (if you have it) onto the container
Zip lambda — a Lambda function references the code it uses to run either as a zip file or an image in S3. This is explored here. Here, we’re using zip. If you needed to change to use an image, you would use a different git action to push this code in an image to amazon container registry (ECR).
Deploy to AWS Lambda — this is an action provided by AWS that ensures the github runner can authenticate to AWS. To make this work you need to save two secrets into the environment section of Github. See docs.
final run steps — this is a very simple github action.Now we’ve finished zipping the code we want and authorising the github runner to AWS, we’re basically going to make use of this endpoint to update the function code on the Lambda.
Note: there is no CI/CD here. Understanding how to set-up your dev/staging/prod environments in a lambda architecture is well-documented and out of scope of this article. You should definitely be using CI/CD and have a separate staging account / env if you’re thinking of doing this in a production / enterprise context.
Conclusion — Lambda for Data Teams
That’s more or less it! This git action gives you an automated flow to go from dev to prod (eek) for updating python code on AWS Lambda functions.
There is lots more to do like setting up triggers, logging, and also writing some actual code! We’ll dive into this in future artcles.
Common Lambda FAQs
How to create an AWS Lambda function?
Sign in to AWS Management Console
Go to the AWS Management Console and sign in with your credentials.
2. Navigate to AWS Lambda
Once logged in, type “Lambda” in the search bar and select Lambda from the results.
3. Create a New Lambda Function
On the AWS Lambda page, click on the Create function button.
Choose a method to create your function:
Author from scratch: Create a function with new code.
Use a blueprint: Start with a pre-made template.
Container image: Deploy a function packaged as a container.
Browse serverless app repository: Use a pre-built serverless application.
4. Configure the Function
Function Name: Provide a unique name for your function.
Runtime: Choose the runtime environment (e.g., Node.js, Python, Java, etc.).
Permissions:
By default, Lambda will create a new execution role with basic Lambda permissions.
You can also choose an existing role if you have one.
5. Write the Lambda Function Code
You can write your Lambda function code directly in the in-browser code editor or upload a .zip file containing your code and dependencies.
For example, a simple Python function might look like this:
def lambda_handler(event, context):
return {
'statusCode': 200,
'body': 'Hello from Lambda!'
}If your function depends on external libraries, you will need to package them with your code and upload it as a .zip file.
6. Configure Function Settings
Environment Variables: Set key-value pairs to store configuration settings.
Timeout: Define how long your function can run before it’s terminated (default is 3 seconds).
Memory: Allocate memory for your function (default is 128 MB).
VPC: If your function needs access to resources in a VPC, configure it here.
7. Set Up Triggers
You can specify one or more triggers that will invoke your Lambda function. Triggers can be events from services like S3, API Gateway, CloudWatch, DynamoDB, etc.
For example, you could set up an S3 bucket as a trigger so that your function is invoked whenever a new file is uploaded to the bucket.
8. Deploy the Function
Once your code is ready and settings are configured, click Deploy to publish your function.
9. Test the Function
After deploying, you can test your function within the Lambda console.
Click on Test, create a new test event with sample input data, and then execute it to see the result.
The console will show logs, output, and any errors that occurred during execution.
How do you set a Lambda function?
See above
How do I host a Lambda function in AWS?
See above
What is the first step in creating a Lambda function?
Sign in to the management console in AWS and search for “Lambda”. If you follow the steps in the guide above, you’ll see how to create the instance.
This can also be done programmatically using terraform.
The first step to setting-up the code for Lambdas is a bit different. Why not leverage this example repo. This will be different depending on if you’re using Python, Javascript etc.