
How we think about Data Pipelines is changing
The goal is to reliably and efficiently release data into production


Data Pipelines are series of tasks organised in a directed acyclic graph or “DAG”. Historically, these are run on open-source workflow orchestration packages like Airflow or Prefect, and require infrastructure managed by data engineers or platform teams. These data pipelines typically run on a schedule, and allow data engineers to update data in locations such as data warehouses or data lakes.
This is now changing. There is a great shift in mentality happening. As the data engineering industry matures, mindsets are shifting from a “move data to serve the business at all costs” mindset to “reliability and efficiency” / “software engineering” mindset.
Continuous Data Integration and Delivery
I’ve written before about how Data Teams ship data whereas software teams ship code.
This is a process called “Continuous Data Integration and Delivery”, and is the process of reliably and efficiently releasing data into production. There are subtle differences with the definition of “CI/CD” as used in Software Engineer, illustrated below.
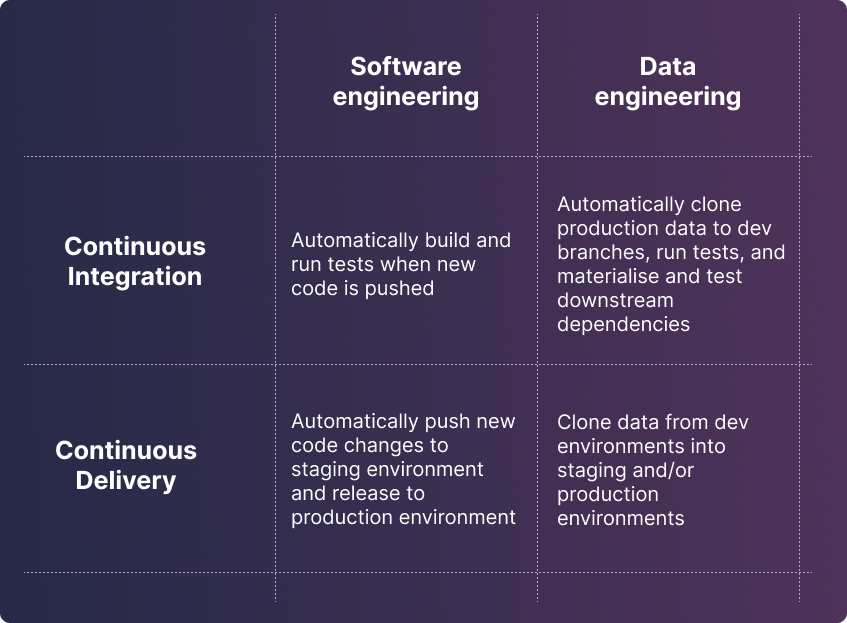
In software engineering, Continuous Delivery is non-trivial because of the importance of having a near exact replica for code to operate in a staging environment.
Within Data Engineering, this is not necessary because the good we ship is data. If there is a table of data, and we know that as long as a few conditions are satisfied, the data is of a sufficient quality to be used, then that is sufficient for it to be “released” into production, so to speak.
The process of releasing data into production — the analog for Continuous Delivery — is very simple, as it simply relates to copying or cloning a dataset.
Furthermore, a key pillar of data engineering is reacting to new data as it arrives or checking to see if new data exists. There is no analog for this in software engineering — software applications do not need to poll APIs for the existence of new code, whereas data applications do.
Given the analog of Continuous Delivery in data is so trivial, we can loosely define Continuous Data Integration as the process of reliably and efficiently releasing data into production in response to code changes. Code changes that govern the state of the data are “continuously integrated” via a process of cloning, materialising views, and running tests.
We can also loosely define Continuous Data Delivery as the process of reliably and efficiently releasing new data into production. This covers the invocations of pipelines or operations in response to the existence of new data.
Thinking about these two processes as the same type of operation but in a different context is a fairly radical departure from how most data teams think about data pipelines, or data release pipelines.
Additional considerations
There are lots of additional considerations to think about here, and that’s because there is so much to consider beyond merely releasing data in production.
Data isn’t static. It doesn’t simply exist in a place where it can be manipulated. It arrives in locations sparsely distributed across an organisation. It gets moved between tools. It arrives at different frequencies and only after the laborious process of “ELT” does it finally arrive in a data lake or data warehouse.
Furthermore, Github Actions isn’t a sufficient infrastructure for doing all of this work. Perhaps as an orchestration layer, but certainly not for doing heavy-compute and doing data management.
These factors lead to many additional considerations for how to design a system that’s capable of delivering Continuous Data Integration and Delivery, which I discuss here
User Interface
Having a single User Interface to view Data deployments is key. Data teams who just use the UIs from multiple cloud data providers for DataOps will be at a loss when it comes to aggregating metadata to do effective DataOps, but also BizFinOps.
There are also data deployments to aggregate, which typically arise due to:
New data arriving
A change in the logic for how to materialise the data
These are currently handled using a workflow orchestration tool and GitHub actions or something similar. This creates a disjoint — Data Teams need to inspect multiple tools to understand when data tables have been updated, what their definitions are, and so on. You could, of course, buy an observability tool. However this is yet another UI, another tool, and another cost.
Having a genuine single pane of glass for Orchestration, Observability, and some kind of Ops would be a killer feature and one I would have loved to use at Codat, where we’d stitched together a whole host of open-sourced and closed-source vendor SAAS tools.
Observability or Metadata gathering
I alluded to this in the previous section, but observability and metadata gathering is fundamental to a strong Data Pipeline.
The important thing here, which I believe Observability Platforms miss, is to place the Observation in the Pipeline itself. Otherwise, presenting data engineers with metadata, pieces of information like “this failed” or “that table is stale” is undesirable, since it’s A) ex-post (after it’s too late) and B) unrelated to pipeline runs. Sure — a table is broken. But is it broken because of a change someone just pushed or because of some new data that arrived?
There was another good talk from Andrew Jones I attended recently where he spoke about the 1, 10, 100 pyramid.

Prevention Cost — Preventing an error in data at the point of extraction will cost you a $1.
Correction Cost — Having someone correct an error post extraction will cost you $10.
Failure Cost — Letting bad data run through a process to its end resting place will cost you $100.
Observability tools are in the yellow to red section. If they’re setup on your prod databases, the likelihood is you’re in a race against time to fix the issue before someone realises.
Having analysts patch bad data with hacky SQL sits in the yellow section.
Orchestration with observability combined is between the green and the yellow. If all your data pipelines have access to all your metadata, and can implement data quality tests as you materialise and update tables and views, then you can pause a pipeline any time these tests fail. This means no bad data ever gets into production.
This is extremely powerful, which is why I believe having an Orchestration tool that executes data pipelines with access to granular metadata is the way forward (disclosure my start-up is doing just that).
Summary
We are moving away from data-agnostic workflow orchestration tools plus janky or non-existent Continuous Integration to unified Continuous DATA Integration and Delivery.
There will be platforms that enable data teams to get full, reliable, and efficient version-controlling of datasets and rock-solid data pipelines. These will have observability capabilities built-in, and while many are not end-to-end yet, it certainly feels like this is the way things are heading.
There are many mature data tools that are doing this. For example, for data warehousing CI and CD, Y42 have the concept of “Virtual Data Builds” which is basically the same thing as part 1 of this article. For the Data Lake environment, Einat Orr over at Lake FS / Treeverse posted on this recently — what they do is functionally pretty similar and easily implementable in Snowflake (I wrote an article about that here). SQLMesh’ “enterprise” version (don’t believe the open source happy clappyness, this is a venture backed business. They will try to make money, like all of us) has observability and version control built into it, and it’s pretty cool.
You can, of course, still do all of this using something like Airflow. Hell, you could brew your morning coffee with Airflow if you wanted to. I guess the question is — do you have the time, the patience, and the expertise to write all of that code? Or are you like me, and do you just want to get shit done? 🐠