


Orchestration with Data Quality: Announcing Data Reconciliation
Why automating cross-db reconciliation is another way to gain trust you might want to consider


Substack Note
We sort of did a pre-release of this feature a while ago and someone said “oh it’s very novel of you to combine orchestration with observability”
This somewhat irked me? idk why?
My reference point for the platform is always A) what do data teams want/need and B) what are they doing today
When it comes to auto-reconciling data across databases, they almost always start off with
Airflow Task to query data
Connections to the two destinations
New Task to compare the results
(Optional) when the data gets big (and fast) store a checkpoint somewhere in a db so you don’t need to query all the data all the time
It’s (4) that’s really annoying. The other step data teams do is
After building your DAG with lots of “Data Quality Tasks”, build a nice UI and alerting system
This “nice UI and alerting system” is also a key feature of Orchestra as a control plane for data things, so that makes sense.
Point being, it makes quite a lot of sense to offer this from your orchestration plane because it’s what your data team was probably doing anyway. The other nice aspect is that automatic cross-db reconciliation is another weapon in the arsenal of gaining trust with your end stakeholders - trust is of course, an increasingly important currency for data teams, and we should try to build it however we can!
The announcement / technical detail if of interest. There is a good excalidraw diagram about half way down.
Introduction
Today we’re excited to announce the latest standalone feature in Orchestra: Data Reconciliation, or “DataRec”, for short.
A problem many data teams face is the need to intermittently reconcile data between what exists in source and target databases. These often come in the form of tedious “can you check these numbers match?”-type requests. Not only are these tasks mundane for data teams, but time-consuming and increase context-switching.
With DataRec, Orchestra users can easily reconcile data between source databases like SQL Server and target databases like Snowflake, BigQuery or Databricks.
Because of Orchestra’s flexible integration paradigm, any integration can be used as a source or target. Data teams need only write the queries and specify the connections and Orchestra handles the rest.
Orchestra users can use this additional security to keep building trust with end stakeholders, which ultimately increases the rate of Data and AI adoption in an organisation, while (hopefully!) decreasing the number of those pesky and annoying tickets to reconcile data sources.

Streaming and Apache Iceberg
While orchestration is best understood in the context of batch workloads, DataRec is targeted at batch, but more so, streaming and CDC use-cases.
For large and fast-moving data, adding data quality checks as gating items is much less trivial than in batch systems where dbt or Coalesce can be used.
Furthermore, implementing quality checks *across* different pieces of infrastructure is even harder, as it requires multiple points of integration.
The biggest challenge, however, relates to speed and cost. Anybody can write a script to count every row in a table (or two) and compare the results — but this is inefficient and potentially very costly.
That is why Orchestra allows the incremental checking of row counts, time stamps, and auto-incrementing IDs. Instead of scanning the entire table, Orchestra stores a cache or checkpoint for each successful test. We are also excited to add AWS S3, ADLS Gen-2 and BigQuery to the Near-term Product Roadmap in this vein.
This means data engineers don’t need to worry about inefficient data quality tests taking up too much load on key data infrastructure — tests can be run “little and often”, providing both increased visibility and efficiency.
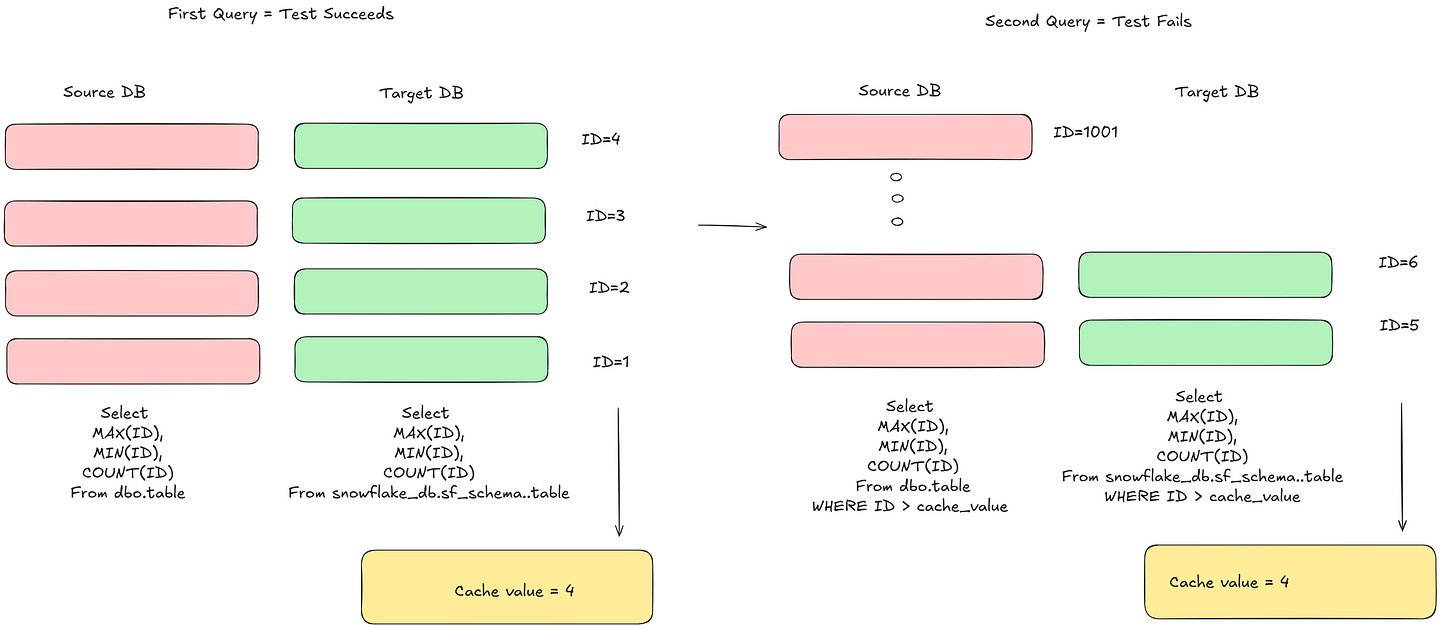
In the example above, you can see that if there is a Source DB and Target DB with 4 records in both, the initial data reconciliation test succeeds and updates the cache value.
On Subsequent Tests, the cache value filters the data so the queries process data incrementally. This improves performance and reduces cost. In the second case, there are new records in the source that are not in the Target — this causes the tests to fail and the cache value is not updated
These can also be incorporated into data pipelines, which means data transformations on streamed data in (possibly in an iceberg format) only occur if data quality is sufficient.
Learn more
We can’t wait to see what you build — for the time being, this feature is available to people on all plans. Why not try:
SQL Server to Snowflake Rec: moving data from SQL server to snowflake via CDC? Not sure if you always get all the rows? Tired of finding missing hours weeks late?
Answer: DataRec cursor field
Multi Cloud: large organisation replicating data across different environments? Not sure everything always makes it?
Answer: DataRec Cursor Field
Gnarly data: do you have data without a time stamp or auto incrementing ID where you need to specify a custom query to reconcile data?
Answer: DataRec Manual query
Find out more about Orchestra
Orchestra is a unified control plane for Data and AI Operations.
We help Data Teams spend less time maintaining infrastructure, make them proactive instead of reactive, and ultimately win trust in data and AI from the Business
We do this by consolidating Orchestration with monitoring, data quality testing, and data discovery. You don’t need an observability, lineage, catalog etc. with Orchestra.
Check out