
Real time is going mainstream | Why Real-time is the new standard in data engineering
Anyone building a data stack in 2026 needs to think of these patterns first

I’ve always thought real-time systems were overcomplex for my use-cases. Kafka, Debezium, Debezium-Kafka - who cares? The business doesn’t need data that fast anyway.
I’ve changed my mind and for one simple reason - data has a chicken and egg problem.
In “It’s only a problem if someone notices” I argued that data teams need to recalibrate. Sometimes the business is like a horse that needs to be lead to water. Show them what is possible, and then ask them what they want.
Don’t just ask them what they want.
Instead of “I need a real-time dashboard” getting “Ah yes but Mr. CEO, but when do you really need the data?” (smarmy, annoying, the corporate equivalent of how left-wing public figures are simply more unlikeable than people like Joe Rogan), why not try
“Hey, I need a real-time dashboard” getting “Cool, I’m building it that way more or elss (like 5/15mins). also just so you know if everything’s like that it’ll be quite expensive”.
And here is why:
Native connectors and CDC Support
Most warehouess offer native connectors and CDC support even for applications. Sure they break when you ned to do more complex stuff like SCD Type 2 but its’s a good start.
Engineering Teams want to get involved
Which means you can get them to drop data in clean form into object storage. Boom, no more databases, real-time into the warehouse baby
ELT Tools are smarter
Tools like Fivetran and Estuary already coalesce batch and CDC/real-time into single platforms / paradigms and the industry is competitive so it’s not like amanaged kafka instance that could break the bank
Warehouses are doing random cool shit that makes this even easier
Clickhouse Postgres allows you to have managed postgres with direct replication into Clickhouse at the press of a button, supposedly (I’ve not tried it but will soon). Databricks’ Neon acquisition and recent postgres announcements RE Lakebase (google: Lakebase March 2026) are a similar thing. Who else has Postgres? Snowflake
Of course if you’re a data leader going into a large enterprise with any amount of legacy your option to do this disappears.
And of course, lest we not forget - coding is fun. In the architecture above, there is no space for you to write an ad-hoc python script. And as data people, we always need those.
The point being, this approach should get you 90% of the way there but inevitably something will come up. There will be some stupid API, or some recurrent task, or something that it doesn’t make sense to stream, that also needs accounting for.
This is why I like Orchestra because it’s not just about orchestrating batch workflows but about being the unified control plane for AI and Data operations. It’s about monitoring too. Today we integrate with Estuary.
Why is this important? Because there is nothing to orchestrate. Estuary is just “running”. There is nothing to “trigger”. But things can still break. What happens if someone takes down your salesforce instance? Wouldn’t you like to know?
The Orchestra integration allows you to monitor KPIs in Metrics via the OpenTelemetry API, such as the latency, number of new rows, and so on. It actually stores the state so it can compare values over time. The data is available via MCP, so that if stuff does break down down there is the lineage trail available for review.
Read on more if you’re excited! And if you’re building a new data stack please consider starting ambitiously with a bit more real-time/kappa architecture focus. It doesn’t have to be Kafka in 2026 to be fast.
Introduction
Today we’re super happy to announce our integration with Estuary, the right-time data platform.
Estuary is an ELT tool that allows seamless replication of data from any database in near real-time using CDC, but also has a host of other API-basec connectors. Estuary can be deployed within a customer’s VPC and unifies both batch and streaming, earning it the rightful moniker of the “Right-time” data platform.
With Estuary, instead of spending lots of time managing and building connectors, data teams can simply set configurations and let the data flow.
Similarly, with Orchestra, instead of spending lots of time managing and building orchestration and monitoring systems, data teams can set their pipelines as .yml and let Orchestra handle the rest.
What you can do with Estuary and Orchestra
You can now monitor all your Estuary Connections for latency, drift, and row counts.
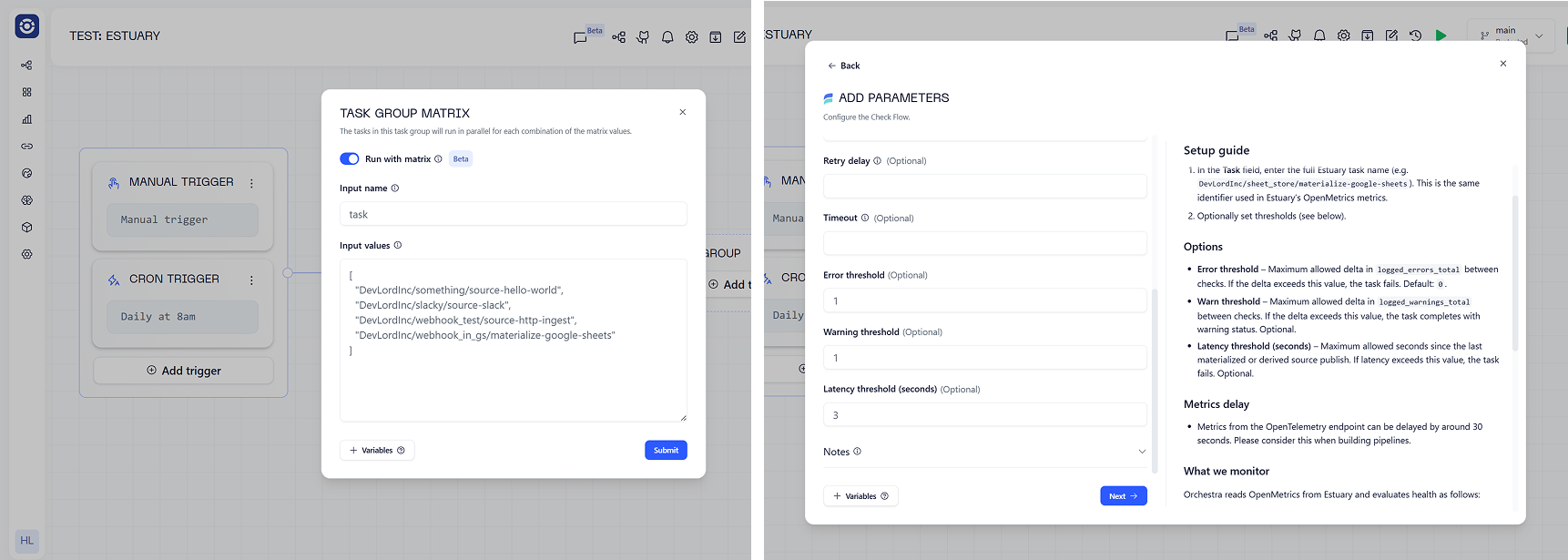
By leveraging the Open Telemetry endpoint, Estuary and Orchestra users can be 100% that data meets SLAs and Standards before processing it.
Check-out the resources below!
👋 Learn more about Orchestra and Estuary
📚 Read the Estuary Docs
We can’t wait to see what you build.
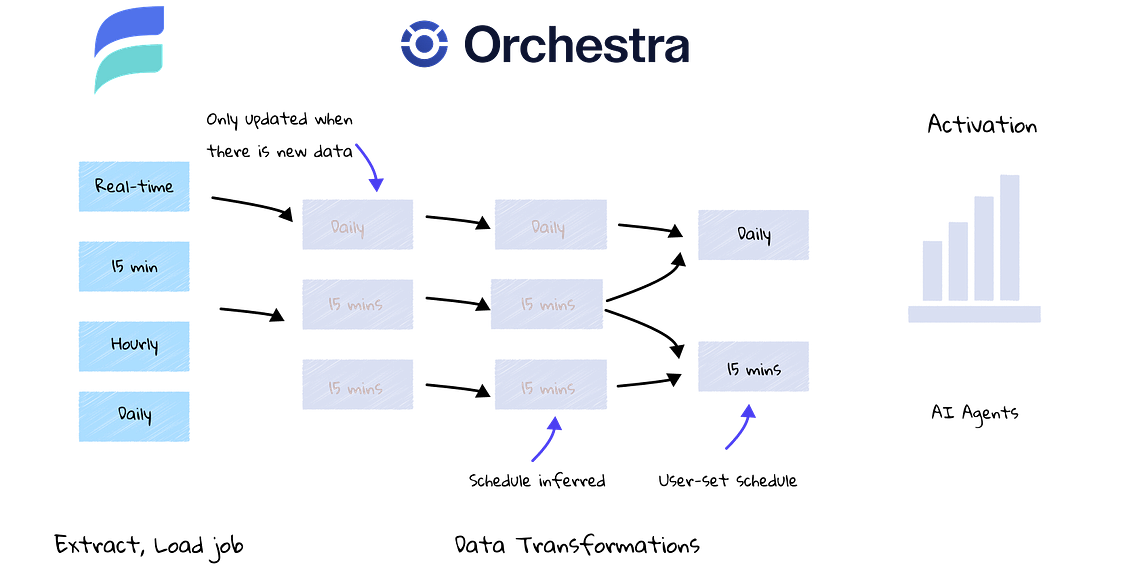
The Problem of scheduling without Real-Time Data
We are particularly excited for our integration with Estuary in light of Orchestra’s recent developments in the data transformation space.
Historically, companies with legacy ELT tools would have a myriad of tricky pipelines on different schedules to manage.
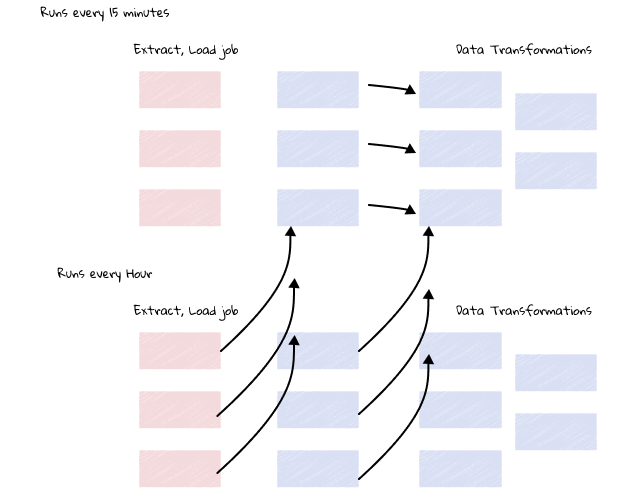
Specifically:
Engineers need to set different schedules and keep track of them in their EL tools
Engineers need to manually set tags on different transformation models
Engineers need to have separate end-to-end pipelines for every schedule
Schedules need to be more complex than necessary to avoid overlaps on the hour / at midnight for example (which means hourly schedules are in fact, everything except midnight)
Adding more schedules is time-consuming because of all the above points
With Estuary and Orchestra, you just set your desired frequency and everything “just works”.
Declarative Scheduling with Estuary and Orchestra
This means that engineers can focus on “settting it and forgetting it”.
Meanwhile, Orchestra polls Estuary to ensure connectors are healthy before running downstream transformations either in tools like Coalesce or orchestra-dbt.
It makes scheduling very easy since the only thing that data folks need to do is
Configure Estuary Connectors
Define Business logic
Add SLAs to models (see below)
Build a simple Orchestra pipeline (see below)
Example SLA for dbt
models:
- name: dim_orders
description: Dimension table for orders
config:
freshness:
build_after:
count: 2
period: hour
updates_on: all
- name: final_model
description: Final model for the project
columns:
- name: order_id
tests:
- not_null
- unique
config:
freshness:
build_after:
count: 1
period: hourExample Orchestra pipeline
version: v1
name: ‘TEST: Estuary’
pipeline:
0078c254-ca29-4742-949f-34e9fdaa581c:
tasks:
4b10e6fd-6447-4bb8-9938-b11a8bc6ab4c:
integration: ESTUARY
integration_job: ESTUARY_CHECK_FLOW
parameters:
task: ${{ MATRIX.task }}
error_threshold: 1
warn_threshold: 1
latency_threshold: 3
depends_on: []
name: Check task
connection: test_91003
depends_on: []
name: ‘’
matrix:
inputs:
task:
- DevLordInc/something/source-hello-world
- DevLordInc/slacky/source-slack
- DevLordInc/webhook_test/source-http-ingest
- DevLordInc/webhook_in_gs/materialize-google-sheets
38c6e1bb-b900-40e6-8c23-4b720736747d:
tasks:
3ca8743b-4037-48c9-908f-2c0ba014ca70:
integration: DBT_CORE
integration_job: DBT_CORE_EXECUTE
parameters:
commands: dbt build
package_manager: PIP
python_version: ‘3.12’
use_state_orchestration: true
depends_on: []
name: excute dbt core
depends_on:
- 0078c254-ca29-4742-949f-34e9fdaa581c
name: ‘’
schedule:
- name: Daily at 8am
cron: 0 8 ? * * *
timezone: Europe/London
webhook:
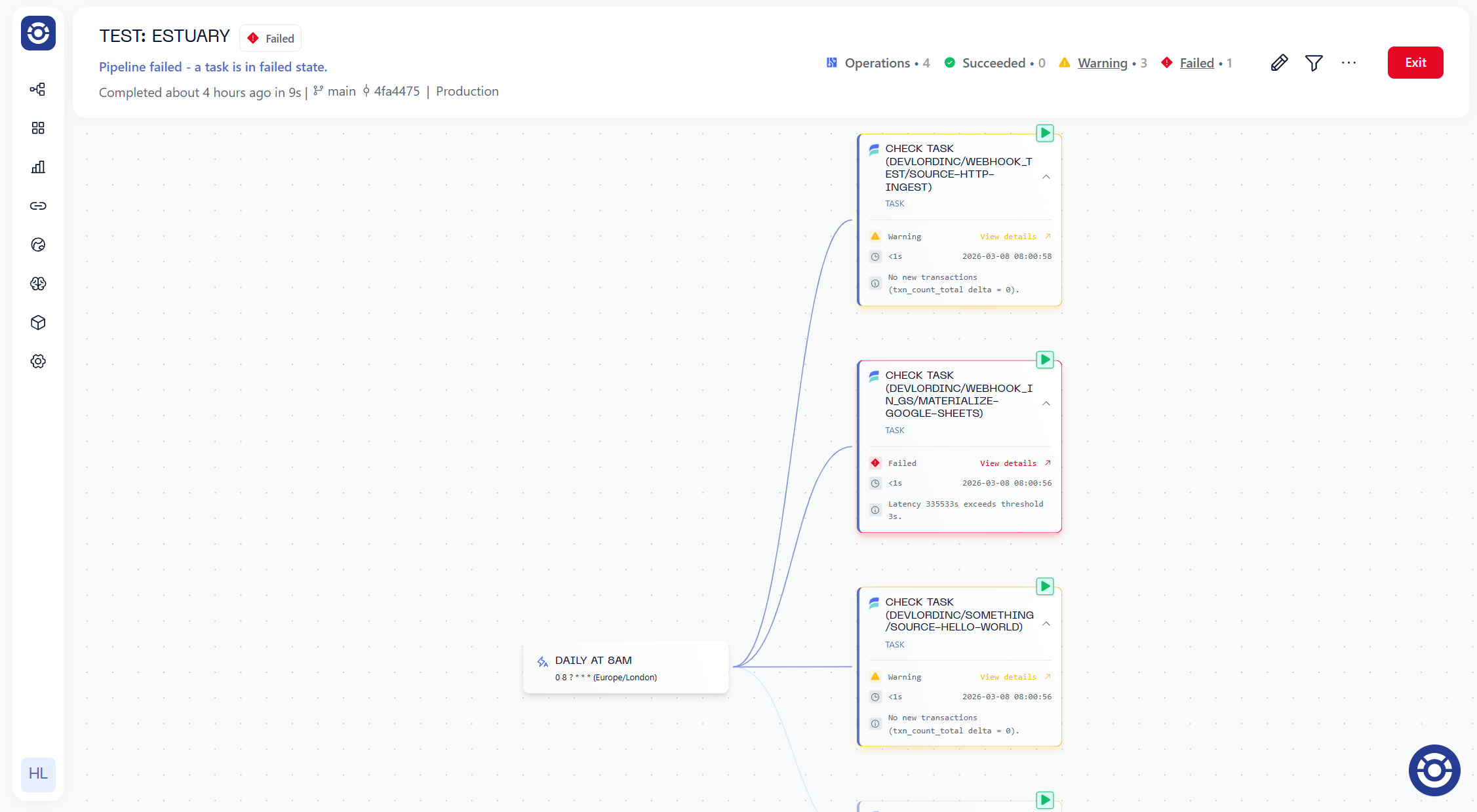
enabled: falseBy combining these two configurations you’ll achieve end-to-end lineage, orchestration and monitoring across ingest to transform and beyond. The entire Orchestration pipeline is less than 100 lines of code and be configured in a UI as well.
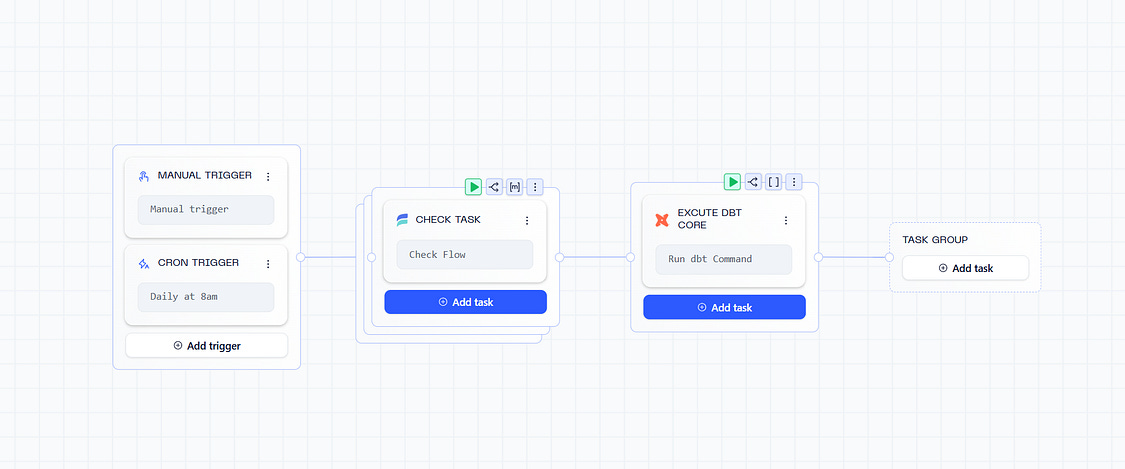
Configuring an Estuary Pipeline in Orchestra
Check out some more information on Estuary below 🚀
How does Estuary compare to Fivetran?
When evaluating Estuary vs Fivetran, data teams are typically comparing two modern data ingestion platforms designed to move data from operational systems into cloud data warehouses such as Snowflake, BigQuery, or Databricks. Both tools help organizations automate ELT pipelines, reduce engineering overhead, and maintain reliable data syncs, but they differ significantly in architecture, real-time capabilities, and operational control.
Fivetran is widely recognized as one of the most mature managed data ingestion tools on the market. It offers a large library of pre-built connectors and emphasizes simplicity: users configure a connector, choose a destination warehouse, and Fivetran handles schema changes, retries, and incremental syncs automatically. This makes it particularly attractive for companies that want a fully managed ELT pipeline with minimal engineering maintenance. Pricing is usage-based, typically calculated using Monthly Active Rows (MAR), which can become expensive as data volumes grow, but many organizations accept the premium in exchange for reliability and reduced operational effort.
Estuary, by contrast, positions itself as a real-time data integration platform built on streaming architecture. Instead of relying primarily on scheduled batch syncs, Estuary uses change data capture (CDC) and streaming pipelines to move data continuously from source systems into analytics platforms. This makes it appealing for teams building real-time analytics pipelines, event-driven architectures, or operational data platforms. Estuary also offers more flexibility for engineers who want deeper control over pipeline configuration, schema evolution, and transformations within the ingestion layer.
Another key difference lies in the design philosophy of the platforms. Fivetran focuses on simplicity and abstraction, hiding infrastructure complexity from the user. Estuary exposes more of the pipeline mechanics and is designed for organizations comfortable working with streaming data infrastructure. As a result, Fivetran is often preferred by analytics teams prioritizing fast setup and reliability, while Estuary appeals to engineering-heavy organizations building low-latency data pipelines or real-time data platforms.
In practice, the choice between Estuary and Fivetran depends on the data latency requirements, scale, and engineering resources of the organization. Companies focused on traditional warehouse analytics may prefer Fivetran’s mature ecosystem and ease of use. Teams building modern streaming architectures or operational analytics systems may find Estuary’s real-time capabilities and CDC-driven pipelines better suited to their needs. Both tools ultimately aim to solve the same challenge — reliable cloud data ingestion and pipeline automation — but they approach it through different architectural models.
Estuary vs. Fivetran pricing
When comparing Estuary and Fivetran on pricing, the biggest difference comes down to how each platform measures usage and charges for data ingestion. Both offer free tiers and usage-based pricing, but their cost models are fundamentally different, which can significantly affect total cost as pipelines scale.
Fivetran pricing is based on the Monthly Active Rows (MAR) model. This means companies pay based on the number of rows that are inserted or updated each month in the source systems connected to Fivetran. At first glance this seems straightforward, but costs can grow quickly for large or frequently updated datasets. The platform internally normalizes data into multiple rows, which can increase the MAR count and make pricing harder to predict for complex schemas or high-volume workloads. For organizations syncing large operational databases or rapidly changing SaaS data, this pricing model can lead to unexpectedly high bills as data volumes scale.
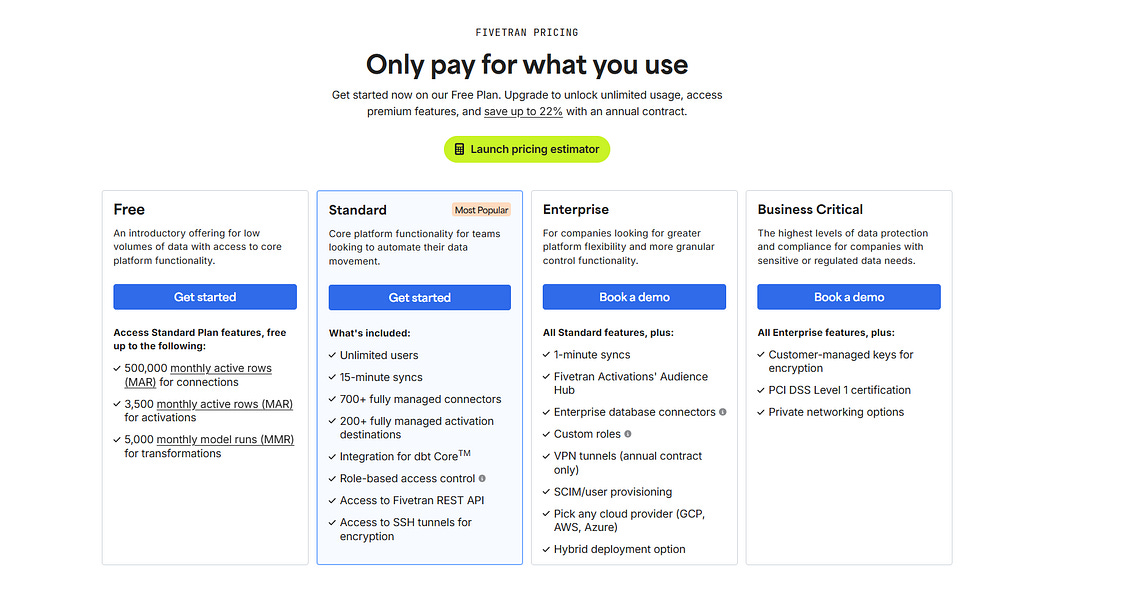
Estuary pricing, by contrast, is typically volume-based, charging primarily for the amount of data moved through the platform rather than the number of rows processed. In practical terms, this means organizations pay based on gigabytes or terabytes of data transferred through pipelines, often with additional small infrastructure charges for running captures or materializations. This model tends to be easier to estimate because cost correlates directly with data volume rather than row changes or schema structure.
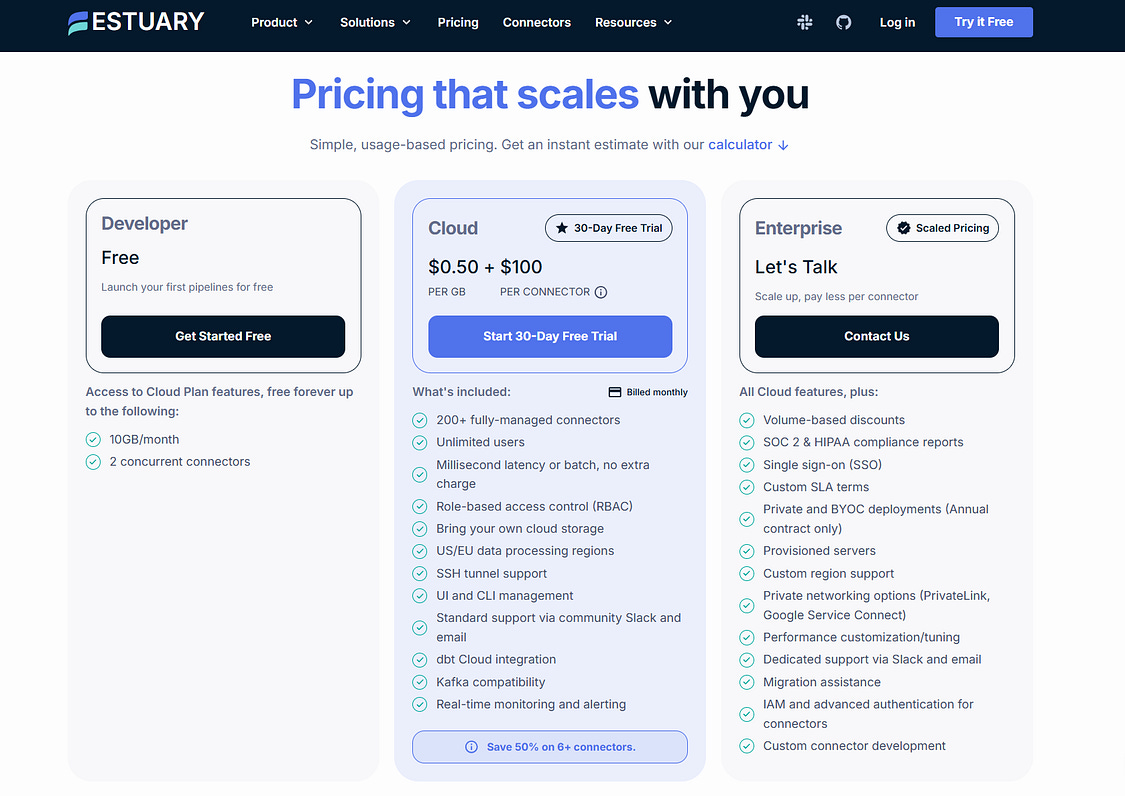
The difference between row-based pricing and volume-based pricing becomes especially important for modern data pipelines that use change data capture (CDC) or streaming architectures. In these environments, the number of row updates can be extremely high even when the actual data volume is relatively small. With Fivetran’s MAR model, costs may scale quickly as update frequency increases, while Estuary’s data-volume pricing tends to remain more predictable when processing frequent incremental changes or real-time streams.
In summary, Fivetran’s pricing model prioritizes simplicity for smaller workloads but can become expensive at scale, particularly for databases with frequent updates. Estuary focuses on predictable, data-volume-based pricing, which can be more cost-efficient for high-throughput or streaming data pipelines. For buyers evaluating data ingestion platforms, the decision often comes down to workload characteristics: batch analytics pipelines with moderate change rates may fit well with Fivetran, while large-scale CDC or real-time pipelines often benefit from Estuary’s consumption-based pricing approach.