


The big 3 cracks beginning to show in the Modern Data Stack
Founders need to understand the cycle of bundling and unbundling and how to use this to their advantage


I’m Hugo Lu, CEO of Orchestra the data pipeline management platform. We’ve built a best-in-class platform for orchestration, observability and monitoring for data pipelines and assets in the modern/cloud stack. The best part is anyone can get started for free (no trial, free forever), just crack on with the button below! 🚀
Introduction
There’s this observation from our friends over in venture capital around bundling and unbundling.
This is the observation that, as economic cycles progress, software solutions go through patterns of consolidation, where single software vendors provide multiple solutions (“Bundling”). The market oscillates between this state and one where software solutions provide point solutions (“Unbundling”).
This reflects factors like increased investment and economic growth, but also growing complexity and technological advances. As technology improves, it may suddenly open up many opportunities that necessitate an increase in complexity and therefore the provision of more point solutions. Artifical Intelligence and Generative AI are a good example of this.
The Data industry is at an inflexion point. For the last 5 years, vendors in the data space have proliferated rapidly. Data stacks that include multiple tools have been touted as the future, and now people are beginning to doubt this.
In this article I’ll cover three big cracks beginning to show in the “Modern Data Stack” and the lessons they can teach us as entrepreneurs.
The first crack — All in One Data Platforms
The first thing to note is that we are finally seeing the next generation of “All-in-one” Data Platforms emerge in a big way. Where companies have been using complete data platforms like Talend, Informatica PowerCentre and Matillion, companies are now “Moving to Databricks and GCP”, skipping the entire MDS and going with a new all-in-one platform.
The announcements around Microsoft Fabric and Snowflake’s Snowpark and Polaris cement how data warehouses / compute engines are looking to take over all parts of the Data and AI space.
Of course, up until now Microsoft, Snowflake, Databricks and the rest have always “buddied up” with other vendors. Notably, those focussed on bringing data in (data ingestion software providers) and BI Tools.
Databricks’ summer announcements of Lakeflow (which I called, sage, I know) and AI/BI demonstrate this pattern is changing. Companies like Databricks are no longer looking to capitalise via partner networks — they are looking to eat everything and become the “all-in-one” data platform.

This is symptomatic of a turn in the business cycles where we are re-bundling things again.
Lessons for Entrepreneurs from consolidation
As someone building what is essentially a point solution for managing data pipelines, you might think that bundling isn’t welcome for me.
After all, why would you want an Orchestration engine when you already have one? After all, Databricks have workflows, Snowflake have Tasks. BigQuery have DataForm and BigQuery Workflows.
The thing is — I know from experience there is a huge amount of boilerplate built into Databricks code and workflows code that people are still all writing. Warehouses might become the de-facto way to manage your data, but Orchestra is trying to be the de-facto way for you to manage your data pipelines.
This is something I still see immense opportunity in. So the lesson is: don’t build something that’s easily bundled.
The Second Crack — terrible support and buggy services
How often do we hear about developers being impressed that a small tiny start-up offers incredible support through their CEO responding to slack questions within minutes?
How often do we hear about this happening at large enterprises? Far less!
It’s almost like as a matter of necessity, support gets worse over time as large companies ensure the best support is reserved for enterprises who are paying for it.
We rejoiced with the Modern Data Stack because, over the last 5 years, companies were always relatively early on in their journeys. Customer support was pretty good, and the quality of the product was good too (at least, relative to alternatives).
This has changed a lot. I don’t like to single out vendors, but Fivetran has received a lot of press recently around their support not being great. Something I’ve also seen a bit of myself over the years. dbt-core is receiving next to 0 support now from dbt Labs. This points towards companies having harder times and therefore cutting “non-core” activities; sadly support is often one of those things that gets hit first.
Services also get buggier. Fivetran does weird things, for example:

The other anecdote I’ll share is Snowflake. For example LLM Functions is now “Generally Available” — which I take to mean “anyone can use these”. Alas — it actually means “Available if it’s supported in your region” which I guess is fine but it makes you realise that when these things get announced, they’re not getting rolled out fully.
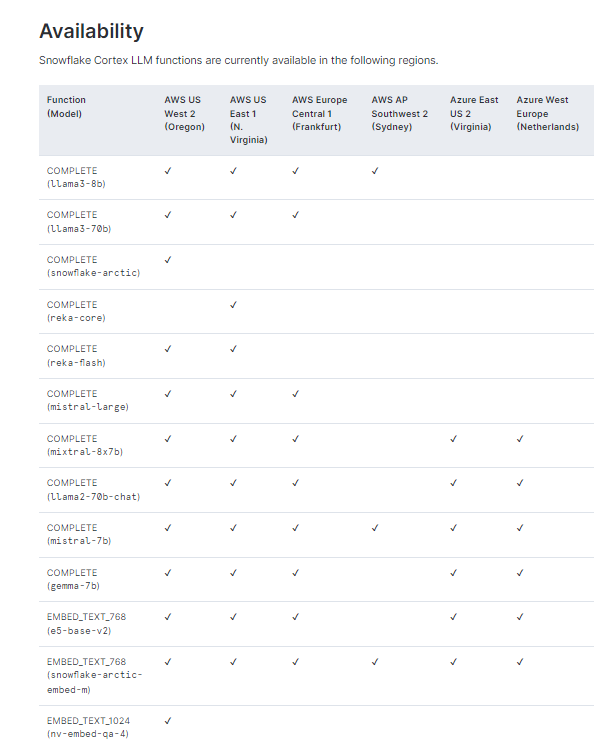
This is, of course, anecdotal. But a pattern I have seen emerging is worse and worse support and less and less complete products with complete launches. It screams of a system running on empty.
Lessons for CEOs from looking at bad support
Part of the reason companies like the MDS ones are in this position is that they raised money at pretty big valuations. Snowflake also is listed, so has all the pressures of being public company.
This means there is pressure to have both revenue and profit. This means you cut corners in the face of intense competition — I have a lot of sympathy for leaders in these positions.
The lesson for us is to be aware of what raising money in times (high and low) entails.

For those in 2021, it means putting that money to good use and getting a hell of a lot of revenue from it. That means Product-Market-Fit if you’re burning through that cash. For those in cooler times (like today) it means running leaner, or if you are looking to raise more money, ensuring you’ve got that Product-Market-Fit so you can capitalise while others struggle.
The Third and Final crack — competitive pressures
Snowflake talks a good game about being an ecosystem player and over the past 4 years especially, it’s been a big deal.
You are hard-pressed to find a Snowflake event of reasonable scale that isn’t full of sales reps from Fivetran, Sigma, dbt and so on. Some partners have reported almost 60% of deals coming through from referrals, which is a huge channel.
However, competitive pressures are putting a strain on these relationships.
Firstly, you see the need for revenue pushing companies like Snowflake into territories of their partners. Snowflake Tasks is a direct competitor to dbt. Snowflake ingest competes directly with a Fivetran or Airbyte.
You see this all across the field, with Fivetran adding dbt transformations (an incredibly ill thought-out feature), BI tools moving into semantic layers (such as Lightdash) but mainly in data warehouses just building everything (see Google Workflows, Google Catalog, Google Vertex AI, Dataplex).
There simply isn’t enough room for all these sub-vendors and now the competitive pressures are beginning to force different vendors to offer the same services — which will surely lead to a survival of the fittest
How to navigate competitive pressures as a leader
I actually think there aren’t too many lessons to be learned here. There was undoubted commercial power in bandying up together, but as time goes by we’ve seen product roadmaps clash, not sales teams per se.
So I think the lesson here is that after the good times end, you need to be on top.
Companies like Snowflake, Google and so on have nothing to lose by going into their competitors’ territories, provided they make a proper investment into new features and don’t release them half-heartedly.
This move is life-threatening for the start-up focussed only on one tiny part of the ecosystem.
When times are good, you have to go big! And when competitive pressures arise, don’t take it personally — they’re likely symptomatic of the wider market; everyone’s in the same boat
Conclusion — a rapidly changing data landscape
No surprise that we’re back once again in a rapidly changing data landscape.
As swiftly as many solutions and tools have arisen to populate market maps, they’ll be falling away again. Perhaps even correlated with NVIDIA’s stock price.
We see many attributes of the MDS are a function of the times / ZIRP era; many point solutions, high degree of partner cooperation, very high levels of investment, the rise of marketing in open-source etc.
We no longer have zero percent interest rates, and as a result competitive pressures are beginning to force cracks into the market structure of the Modern Data Stack.
While there are undoubtedly lessons for CEOs and Commercial leaders alike, the one constant (and I hate to say this) is change! Consolidation is already beginning, and it’s creating market disruption with services like Rockset even getting fully sunset due to acquisition.
It’s an interesting time to be in data so strap in and count your chickens cause stuff is about to go down 🐔
Hugo Lu