
The Snowflake and Databricks Chess War is over
Reading between the lines after the Snowflake and Databricks summits


Everything Released at the Snowflake Summit 2025
2024 was the Year of the AI&Data Intelligence Cloud. 2025 is back to pipes and users
Phew! I’m still digesting everything from the Databricks and Snowflake summits but after a little bit of recovery I am pleased to be writing again to share what the big takeaways are from the Snowflake Summit.
Where 2024 and 2023 were the years of “AI” where we mistook every speaker for constantly smiling when they were in fact, just constantly saying the letters “A” and “I”.
What has become clear is that Snowflake is executing a very, very careful marketing strategy. Where the entire world seems to be trying to consolidate spend into their centres of gravity (c.f. Salesforce, Databricks, Fabric, GCP etc.) Snowflake are sticking to the partner ecosystem.
At least — that is what appears. Sridhar and the team are incredibly smart. They know that by expanding their platform too largely it will dilute the message. Just look at how badly Lakebase has been received by the data community.

To understand the Snowflake Endgame, let’s look at what got released.
Snowflake Summit 2025: What’s New Across AI, Engineering, Analytics, and App Development
At Snowflake Summit 2025, the company doubled down on its vision to become the enterprise data and AI platform. As enterprises scale their AI efforts, Snowflake is rethinking what it means to manage, govern, and act on data — not just with better tools, but by fundamentally reshaping how users interact with data across its lifecycle.
Below is a breakdown of the key announcements across AI, engineering, analytics, collaboration, and platform — each aimed at helping businesses deliver value faster, more securely, and more intelligently.
Agentic AI, Inside the Snowflake Perimeter
Snowflake introduced a unified AI stack that simplifies and accelerates the development of AI and ML apps — fully managed within Snowflake’s governed perimeter.
Snowflake Intelligence (public preview soon): An agentic AI interface that lets business users explore structured and unstructured data through natural language — no code required. Built on models from Anthropic and OpenAI, and powered by Cortex Agents.
Data Science Agent (private preview): An ML co-pilot that handles data prep, feature engineering, and training via conversational AI.
Cortex AISQL (public preview): Enables multimodal AI directly through SQL — including document analysis, image processing and more.
Enhanced Document AI (public preview): Extract structured tables from complex PDFs with schema-aware models.
AI Observability (generally available soon): Monitor and troubleshoot generative AI applications with no-code tools.
Access to models from OpenAI, Anthropic, Meta, Mistral and others — all securely run inside Snowflake.
📚 Read more on Snowflake’s AI and ML innovations.
Simplifying Data Engineering with Interoperability
Snowflake continues its mission to make data engineering seamless and scalable — removing complexity from ingestion, pipeline orchestration and lakehouse architecture.
Snowflake Openflow (GA on AWS): A managed, multimodal ingestion framework based on Apache NiFi. Hundreds of prebuilt connectors. Deep Oracle replication support.
dbt Projects on Snowflake (public preview soon): Build, test, and run dbt projects natively in Snowsight, with Git and AI Copilot assistance via Snowflake Workspaces.
Expanded Apache Iceberg support: Read/write from external catalogs using Catalog Linked Databases. Build pipelines using Dynamic Iceberg tables. Merge on Read and VARIANT support (private preview).
DevOps Enhancements: GA release of Snowflake’s Terraform provider, support for custom Git URLs, and Python 3.9 in Notebooks.
📘 Full breakdown: Data engineering updates
AI-Powered Analytics and Smarter Migrations
AI doesn’t just need good data — it needs context. Snowflake’s analytics enhancements focus on making data interpretable and portable.
Semantic Views (public preview): Define business metrics and relationships in Snowflake, making BI and AI more consistent and interpretable.
Standard Warehouse Gen2: With 2.1x performance gains across core workloads in the last year, Gen2 improves DML (delete/update/merge) speeds and table scans.
SnowConvert AI: Automates code conversion and validation to streamline warehouse migrations — a game changer for legacy systems.
🔍 Learn more in the Analytics and Migrations blog.
Collaboration-Ready Data, Apps, and Agents
To unlock true business value, organizations need to share, build and act on data — safely. Snowflake’s collaboration updates push beyond sharing into app extensibility and real-time enrichment.
Cortex Knowledge Extensions (GA soon): Enrich apps with real-time data from AP, USA TODAY, Packt, CB Insights, Stack Overflow, and more — with full attribution and IP protections.
Sharing of Semantic Models (private preview): Share internal or third-party data sets in an AI-ready format — enabling natural language querying across domains.
Agentic Native Apps: Developers can now build and distribute apps powered by Cortex Agents directly via Snowflake Marketplace.
Snowflake Native App Framework updates: New tools for security (permissions, versioning), observability and compliance help turn prototypes into production.
🤝 Explore Snowflake’s collaboration announcements.
Raising the Bar for Modern Data Infrastructure
Infrastructure should be invisible. With adaptive compute, external catalog discovery, and out-of-the-box observability, Snowflake wants to make performance a default — not a manual chore.
Adaptive Warehouses (private preview): Warehouses that scale compute dynamically and route queries intelligently to meet demand without user intervention.
Horizon Catalog: Now supports Iceberg and will support external discovery from relational DBs, dashboards and semantic models (private preview).
Copilot for Horizon (private preview): Use natural language to perform governance, security and metadata discovery tasks.
Snowflake Trust Center and security updates: New MFA options, password protection, account security hardening.
Snowflake Trail + Observability: Get full observability across Snowpark apps, Openflow pipelines and GenAI agents (generally available soon).
🔧 Dive deeper into Snowflake’s platform innovations.
Summary
Snowflake continues to reimagine how organizations engage with their data — not just through performance or cost improvements, but through intelligent, secure and human-centric interfaces.
From data engineers to app developers, business analysts to AI builders, the platform is evolving to serve a wider range of users — with fewer barriers, faster time to value, and more trust built in.
You can explore all Summit 2025 announcements here.
OK So what did we learn?
Openflow and dbt
Snowflake is not trying to kill Fivetran or trying to kill dbt Labs. If it was, dbt Labs would not have let Snowflake use the Fusion Engine.
Instead, they see value in providing ELT services atop Snowflake to customers. This means that earlier-stage customers can use Snowflake as a complete AI and Data Platform without relying on other tools.
The intention is to gradate above.
So Snowflake is stealing data pie, but not all of it, while retaining the Partner-lead GTM strategy.
Search
Search and semantics is the dark horse here. Semantic layers are becoming more of the rage these days because they moonlight as MCP servers, which means with well-tagged data people can start to ask AI questions like “Build me a dashboard that answers X” which is a huge time-saver for analysts.
Combine this with the cortex releases and Snowflake are sitting ontop of an absolute machine of automation that can happen.
NOTE: Snowflake miss CRUCIAL elements of data here. Horizon Catalog does not have loads of other integrations, which means it has no data from your orchestrator about your data products or your assets outside of Snowflake. Snowflake would need to build integrations to every tool in the Modern Data Stack as well as clean and aggregate this metadata for it to be available.
Snowflake also lacks the ability to gather data into Horizon arbitrarily.
This is why at Orchestra we are building the Integration and Metadata layer for the entire AI and Data stack. Want your metadata available for AI? You need an Orchestrator that fetches the metadata for you (or you can by Atlan, and it will be really expensive and really slow).
Still, there is a lot of data in these Snowflake Enterprise implementations, and even in scale-ups, so its a huge play to start truly democratising AI and Data which resonates hugely with me as someone that came into Data from the business side.
Solving legitimate problems
Adaptive warehouses and semantic layers are nice problems to solve that could have been pushed down the road. Cost and semantics are genuine problems for many data teams, so I love seeing the Product Team announce features that do this.
Crunchy
Crunchy Data. AKA Snowflake Postgres. Yes — Snowflake too will move into operational workloads now or so it appears…
So what’s the conclusion of the Snowflake Summit?
Rather than dilute a marketing footprint that is already quite large, Snowflake chose to double-down on Data infrastructure by shipping core feature updates while announcing additional engineering features like OpenFlow and dbt.
They are doubling down on AI. There is now more investment in the building blocks for AI (semantics) and also postgres.
I thought during the streaming wars the goal of Snowflake and Databricks would be to go after low-latency streaming use-cases. Postgres supports this.
The Streaming Wars 2.0
What not to miss in Real-time Data and AI in 2025medium.com
However unistore is not going away, and based off this graph of Supabase Users
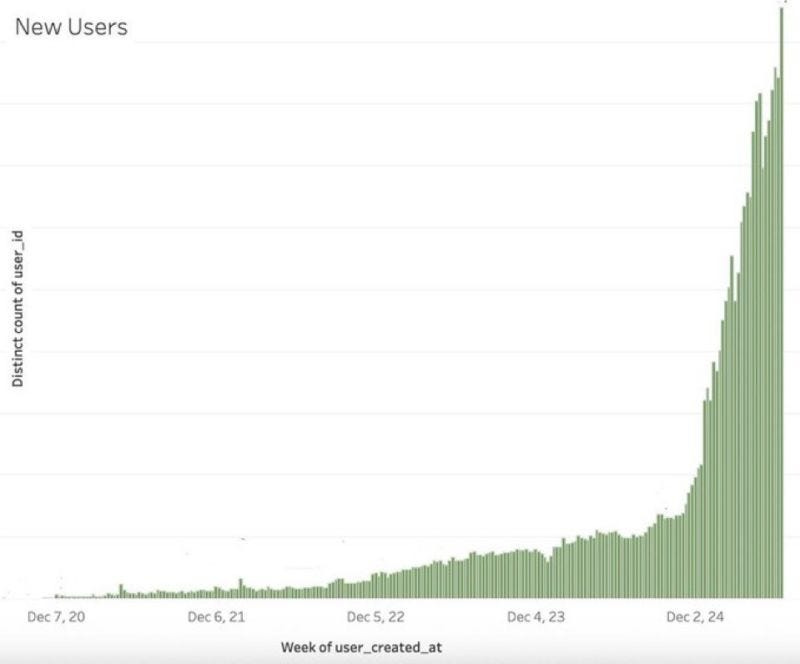
We can see that the thing really driving Postgres adoption is not Streaming use-cases but agents. This is corroborated by Databricks’ acquisition of Neon, and makes more sense for Snowflake too in the context of Cortex and Semantics.
Agents need memory and memory requires databases. If Data Teams need agents, they’ll drive compute to Snowflake through Crunchy / Snowflake Postgres
Lowering the Barrier to Entry
When I worked at JUUL I was manually aggregating 60 excel sheets into a sales report. I learned data engineering out of necessity, but at the time, there was something I thought was a bit odd.
Why was there this huge, incomprehensibly complicated data stack and layers of teams in between me (the business user) and getting my report automated?
Snowflake appear to be leaning HARD on the “ease of use” angle to lower the barrier to entry and thus bring more and more people into the Snowflake ecosystem, rather than drive more technical users into the ecosystem through new use-cases.
I love this strategy. People are becoming more and more technical every day. You can already use AI to vibe code a governed data pipeline using Orchestra. We are firm believers in lowering the barrier to entry for doing data work — after all, much data work is not for data people. Why shouldn’t we all be data people?
And this is where you can see the two strategies diverge. Snowflake know they have an incredible product so they are focussed on bringing people in.
Anyone that follows me knows I believe their one missing piece here is a reliable Framework for building Governed Data Pipelines or Orchestration Framework.
Their recent forays into git-controlling queries is not enough — anybody in data for more than a few years writes their code or their “Source of truth” in their orchestration repo. I do not want to git-control my SQL query to Snowflake and create a task. I want to write my query in my orchestration repo and call it from there, because then I only have one place I need to monitor things.
That future is also obviously not Snowflake Tasks which is woefully underdeveloped. It is something declarative, like Orchestra, that an AI can generate that is fed by the metadata it produces (including the Snowflake Metadata).
Imagine if Snowflake had an AI that could write AI and Data workflows for you, with full CI/CD, that executed jobs across your data estate and gathered the metadata and dumped it in Snowflake, all to be ready for Snowflake Cortex to use.
Contrast this with Databricks, who appear to be making their platform even harder to use but are expanding their use-cases for that demographic of people that understand Databricks.
This means Snowflake and Databricks will still fight but only really after newbuilds and migrations. The demographic they appeal to is differing again - Databricks, to more “I’ll go all in on you” type people, with very spark-y technical folks who are all probably Databricks experts for specific Data use-cases, vs. Snowflake. Snowflake who will go after most other companies and aim to democratise Data and AI within an open ecosystem, where you come to Snowflake for the lightning fast compute and you stay for the ecosystem.
Two very different persona. One big reason I think the two companies’ paths are diverging (there are others, and I will write about this).
It’s a fantastic time to be building in data! Let it SNOW! ❄❄❄❄❄❄❄❄❄
Note — Databricks recently announced a step change in growth. That’s phenomenal, to create this type of second order change. But the question is - at what cost? Time will tell.
Edit - a lot of the summit at Databricks’ narrative was around expanding to new personas and use-cases. See Databricks One and Low-code editor for lakeflow, for example. Here is where I think that falls down - I don’t know if people will be able to come in and use those tools without learning a huge amount about Databricks. As we know, the metdata is key, and I don’t think you can just “give” people parts of the platform unless they’re really well contained. Let’s see. Perhaps Snowflake are focussing just on less while Databricks continue to fight many wars on many fronts.
🤝 Announcements and sources
Snowflake Intelligence: https://www.snowflake.com/blog/introducing-snowflake-intelligence/
Cortex Agents: https://www.snowflake.com/blog/introducing-cortex-agents-in-snowflake/
Cortex AISQL: https://www.snowflake.com/blog/introducing-cortex-aisql/
AI Observability: https://www.snowflake.com/blog/ai-observability-cortex-ai/
AI and ML innovations: https://www.snowflake.com/blog/ai-ml-announcements-summit-2025/
Snowflake Openflow: https://www.snowflake.com/blog/introducing-openflow/
dbt Projects on Snowflake: https://www.snowflake.com/blog/dbt-on-snowsight/
Apache Iceberg support: https://www.snowflake.com/blog/apache-iceberg-summit-2025/
Data engineering updates: https://www.snowflake.com/blog/data-engineering-summit-2025/
Semantic Views: https://www.snowflake.com/blog/semantic-views/
Standard Warehouse Generation 2: https://www.snowflake.com/blog/standard-warehouse-generation-2/
SnowConvert AI: https://www.snowflake.com/blog/snowconvert-ai/
Analytics and Migrations blog: https://www.snowflake.com/blog/analytics-ai-powered-data-migration/
Cortex Knowledge Extensions: https://www.snowflake.com/blog/cortex-knowledge-extensions/
Agentic Native Apps: https://www.snowflake.com/blog/agentic-snowflake-native-apps/
Collaboration announcements: https://www.snowflake.com/blog/snowflake-marketplace-ai-collaboration/
Adaptive Warehouses: https://www.snowflake.com/blog/adaptive-warehouses/
Horizon Catalog: https://www.snowflake.com/blog/horizon-catalog-external-discovery/
Snowflake Trust Center: https://www.snowflake.com/blog/trust-center-updates/
Platform innovations: https://www.snowflake.com/blog/platform-announcements-summit-2025/
Summit 2025 announcements: https://www.snowflake.com/blog/summit-2025-announcements/
Hi Hugo, they banned me on medium so I am over here on substack now. Nice to link to you here again.