


This once hot data trend from a few months ago got resuscitated by our industry’s data sweetheart
It just keeps coming back


I wrote a while ago about how Data Mesh sort of ties in with organisations doing less work, by leveraging more out-the-box solutions. dbt’s recent announcements around dbt Mesh sort of lean-in to data mesh, but in such a way that is almost opposite in ethos; as a solution to managing dbt that’s written and deployed at an enormous scale…one that arguably creates “bloat” or a “data swamp”. One thing is certain - is that data mesh is so badly-defined that it can be applied to my previous examples (where teams become self-serving by doing simple operations using out-the-box tools) AND dbt Mesh; hundreds of developers writing dbt at once. Polar opposites, one definition. Anyway - read on to see more about dbt Mesh in practice from London Coalesce 2023.
What’s Data mesh?
See this nice resource from Starburst.io.
Data Mesh — an approach founded by Zhamak Dehghani — refers to a decentralized, distributed approach to enterprise data management. It is a holistic concept that sees different datasets as distributed products, orientated around domains. The idea is that each domain-specific dataset has its own embedded engineers and product owners to manage that data and its availability to other teams, driving a level of data ownership and responsibility, which is often lacking in the current data platforms that are largely centralized, monolithic, and often built around complex pipelines
Sounds like BS right?
I understand data mesh as a way of organising your data team in an idealised world. In this idealised world, you have a team of about 4–5 platform engineers / data engineers. They are experts in building and managing data infrastructure, but also in communicating how to use said infra and documenting quirks. They maintain the core of dbt projects, manage snowflake admin access, and govern abstractions in Airflow.
In this company there are also embedded analysts — people with non-data jobs that also have data skills who leverage the central infrastructure.
These people rarely exist, and this is an ideal many of us are aware of and have already given up on. It is hard enough to get the marketing team to build a dashboard, let alone have them build an end to end pipeline — and good luck convincing your CMO to spend their budget on a data hire.
So that’s data mesh, what’s dbt mesh?
DBT Mesh
Dbt Mesh and the surrounding product updates are here.
There was an interesting talk from Siemens AG who had this slide at London Coalesce:

There’s a problem here:
Too many people writing dbt
Too many dbt models
Orchestrating multiple dbt models
“dbt Mesh” is therefore a way to split this up. To get over (1) and (2), dbt advocate separate repositories for separate teams. There is also now a feature which is called cross_project_ref that allows dbt models to reference other models. Enterprise clients can now get this orchestration capability.
This means
Too many people writing dbt
is not a problem; it’s just like having lots of software teams with their own repo.
This means
Too many dbt models
Is also not a problem (smaller repos)
It also means
Orchestrating multiple dbt models
Has had to become something dbt Cloud supports (it didn’t before — you would need to do it in Airflow or another open-source orchestration package).
So what’s new? Really — only this last point.
Technical aside
There is no way to easily run separate dbt jobs across projects on either a schedule or using asset-based scheduling. You can only enable “triggering” a job after a job it depends on (in another project) has run. This is limiting, because it means if a base table like “customers” runs every 15 minutes, then everything you want to depend on it downstream also has to run every 15 minutes (because it runs every time the customers table updates, I guess).
You can use Orchestra or an open-source workflow orchestration package to do this, which in my eyes (even my unbiased eyes) is preferable. dbt is a great tool for transforming data — specifically dbt-core.
Having schedules or declarations of what you want to happen (that may or may not be asset-based) is separate, all-encompassing pipeline logic that I would argue should live somewhere else. Having things auto-trigger dependencies is a bit scary to me.
There is one exception here — which if efficient, spells the end of dbt; not just dbt cloud but dbt core. And that’s dynamic tables. These are basically Snowflake’s answer to dbt. You specify the SQL for a dynamic table and Snowflake auto-updates it for you — no orchestrator required.
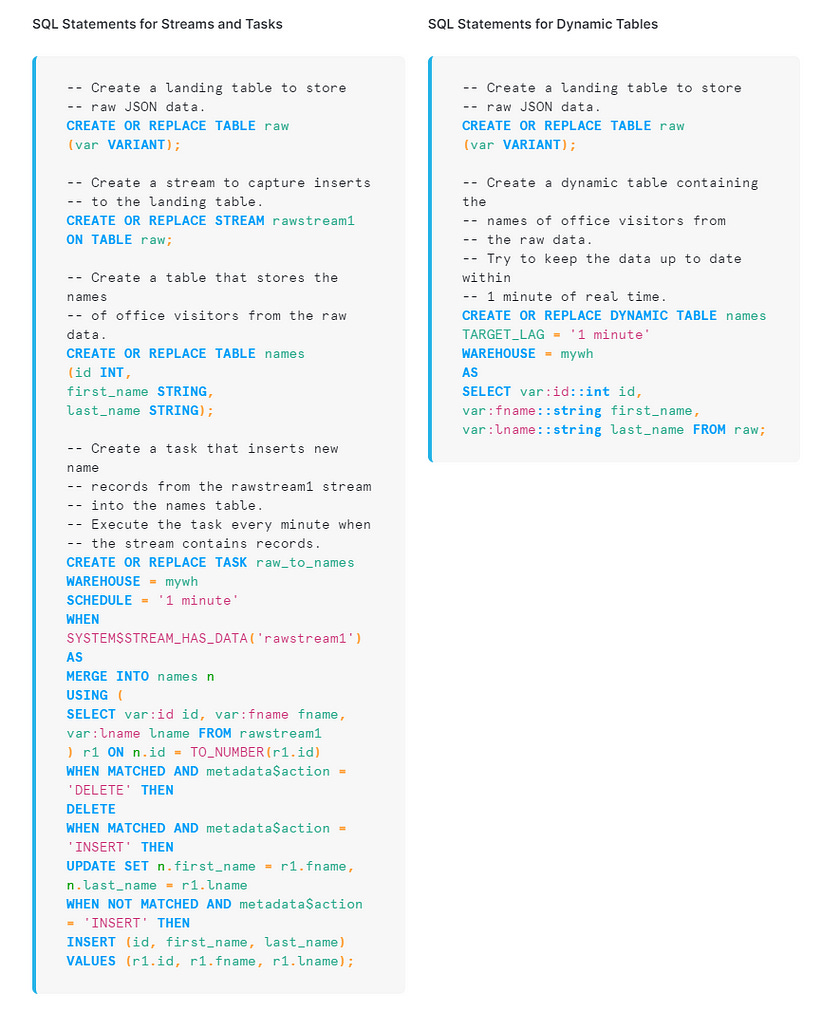
Word on the street is that these are not actually that efficient (incremental batch updates far cheaper), so don’t hold your breath!
Conclusion
“dbt Mesh” hops onto the idealistic and unrealistic concept of “data mesh”. It is, in fact, a set of much-needed features to dbt-core, but mainly dbt-cloud, that allows multiple teams to work on dbt with slightly less friction. Let’s face it — all those 550 dbt developers at Siemens AG are obviously not in the same team. The announcement of dbt Mesh is not the deciding factor in separating these developers into different teams, creating a data mesh full of embedded analysts; it’s more of a feature that makes that existing structure easier. What’s more, as much as I would love multinational company Siemens AG to be representative of my professional environment, it simply isn’t.
So what will happen now? Probably, not much. There may be a few more voices in the community that now equate orchestration of different dbt projects as “practicing data mesh” but really — who cares about data mesh?
Anyway — hope you enjoy and check out dynamic tables and Databricks’ version (Delta Live Tables), which is more mature too! ⭐️