
Understanding the compute value-chain: how to run Python optimally in Data
Computational power grows more and more expensive as you move deeper into the cloud


Substack Note
Orchestra added support for AWS Lambda and other cloud-hosted python processes this week. We’re also working on supporting remote/on-premises connectors, and the reason for this is simple - we want data teams to run efficient architectures.
To understand what this means, you need to understand how computational power grows more and more expensive as you move through the value-chain.
The adage of “data being the new oil” is surprisingly apt here. Raw electricity and compute is the oil. Machines on AWS is crude, abstractions like AWS Lambda or vendor-provided solutions are refined [oil].
This is what the value-chain looks like roughly speaking. The markups are very very rough guesses.

As you can see, running stuff on-premises is basically the cheapest option, but you’ll need more headcount and it will be more painful. Once you move to cloud there is a mark-up as a hyperscaler is the middleman. And so on and so forth.
As Data Leaders, we need to understand what the constraints are in the world in which we operate. By being aware of the tradeoffs to leveraging compute in different places, we can effectively choose architectures that suit our organisations’ needs.
Furthermore, if you’re able to easily integrate all these different sources there is no reason to not employ multiple methods. We work with lots of folks who have complex cloud deployments combined with legacy on-premise systems that aren’t going away anytime soon. Having the flexibility to run workloads, specifically python elt ones, where they run best is a fantastic string to have in one’s bow.
The complexity arrives, of course, when you try to stitch everything together. But that’s what Orchestra is for! Read on if you want to hear about how we think about executing python in hard-to-reach cloud environments.
Orchestra supports AWS Lambda
Introduction
Today we’re extremely excited to announce Orchestra’s support for Python execution for ELT (Extract-Load-Transform) in Cloud Environments.
Simply pip install orchestra-sdk(SDK here) and you are ready to start.
This means that if you’re running python for ELT (or anything else) on any service in the cloud, be it AWS Lambda, an Azure App Service, or Kubernetes cluster, as long as there is an exposed endpoint for the Task Orchestra can get visibility of it.
As the diagram below explains, this is helping push Orchestra to coverage of 100% of data use-cases to truly become a single pane of glass for the entire data and cloud stack.

We’re excited to see what you build! Read on to learn more about a Modular Architecture and how Orchestra is the only Unified Control Plane to truly facilitate this.
Run Python where it runs for ELT and ETL
The diagram below illustrates the growing price of compute resources as they move through the value-chain. You can view cloud vendors such as Snowflake or Databricks as companies that consume cloud compute from vendors like AWS, Azure and Google at the end of the value-chain. Leveraging some tools which use Snowflake under-the-hood is another step in the value chain.
The adage of “data being the new oil” is surprisingly apt here. Raw electricity and compute is the oil. Machines on AWS is crude, abstractions like AWS Lambda or vendor-provided solutions are refined [oil].

We see that the “ways of old”; running everything on premise, while cheaper required an enormous amount of effort.
The purest form of cloud-hosted compute capacity, something like an AWS EC2 box, exists in the cloud with a mark-up or fee associated for managing and maintaining all the data centres that the hyperscalers do.
Any additional managed compute offerings like Kubernetes Services or Lambdas are abstractions upon these machines, which therefore tend to be even more expensive for like-for-like workloads.
In Parallel, other tools lease this compute from hyperscalers, paying the same price as us minus any discount due to scale and gaining a little in terms of economies of scale.
This is then marked-up again, which means when you purchase compute from Snowflake or Databricks you need to pay.
However, as you go through the cycle the user experience improves. There is less and less infrastructure to manage. Which means where you lease your compute is a game of trade-offs. There is no right answer, and an organisation will likely have a combination of these in play at once.
By supporting Python, Orchestra gives Data Teams the ability to Run Python where it runs, in the ways that make the most sense to data engineers.
This is in stark contrast to OSS Workflow Orchestration Tools, which want you to run all your python in their environment. Some of these tools even use Snowflake under the hood, which means you are leasing compute from them at the very end of the value-chain.

Orchestra is a unified control plane with first-class support for integrations across the entire value-chain. This means it is the only solution that is truly aligned with an efficient, modular and versatile architecture.
How to Orchestrate Python in AWS Lambda using Orchestra
AWS Lambda is a good example of a widely-used compute resource that traditional orchestration tools struggle to deal with.
This is because there is no way to poll for the completion of a specific Lambda Function.
This means that in order for Orchestra to know if something is complete, we need to make use of a unique Orchestra feature which is the ability to listen to webhook events.
In this case, Orchestra will trigger the Lambda function. You should pip install orchestra-sdk onto the Lambda by including it in the requirements.txt (or similar) file.
A simple Python decorator is all that is required for you to complete visibility.

To trigger this, head over to
https://app.getorchestra.io
and head to Integrations. Search for “AWS Lambda”.
Like other AWS Integrations, a connection is facilitated via an IAM Role:
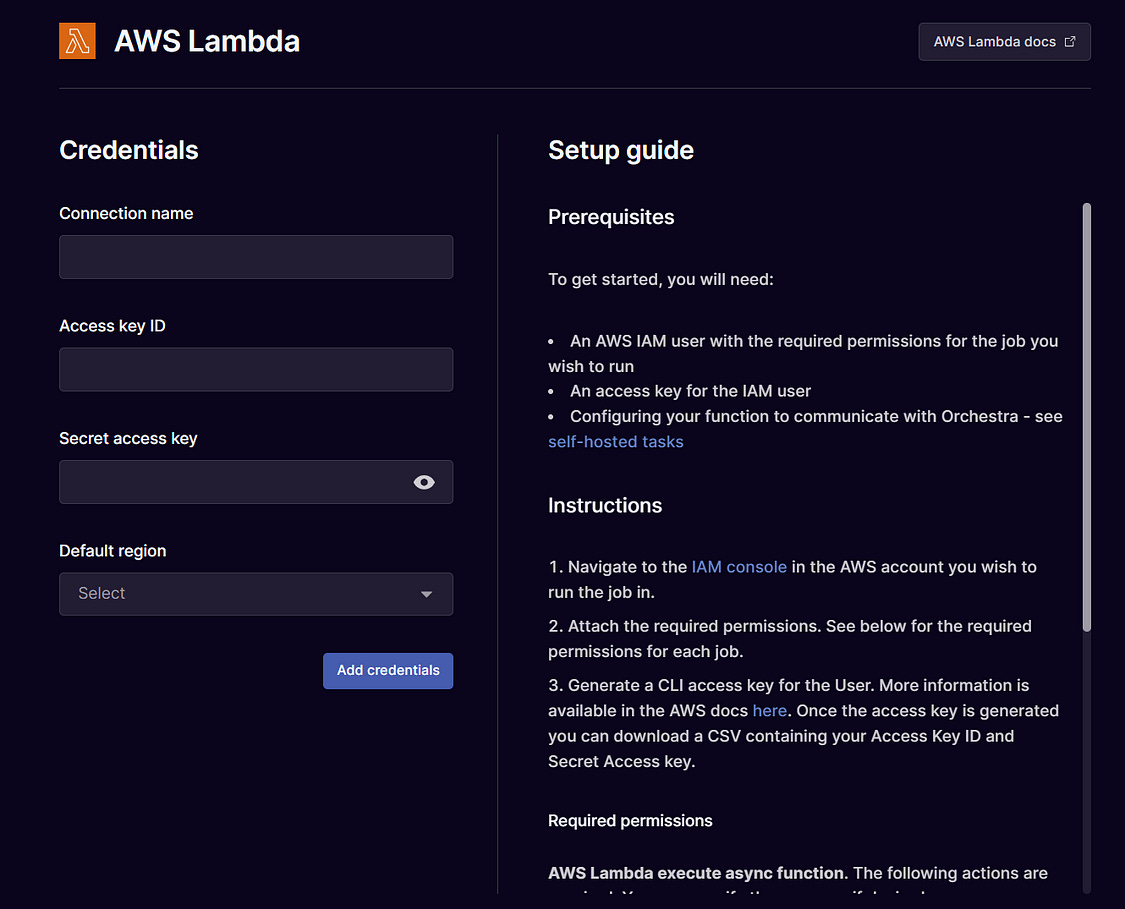
Then, all that is required for you to parameterise AWS lambda in the pipeline builder is its name.
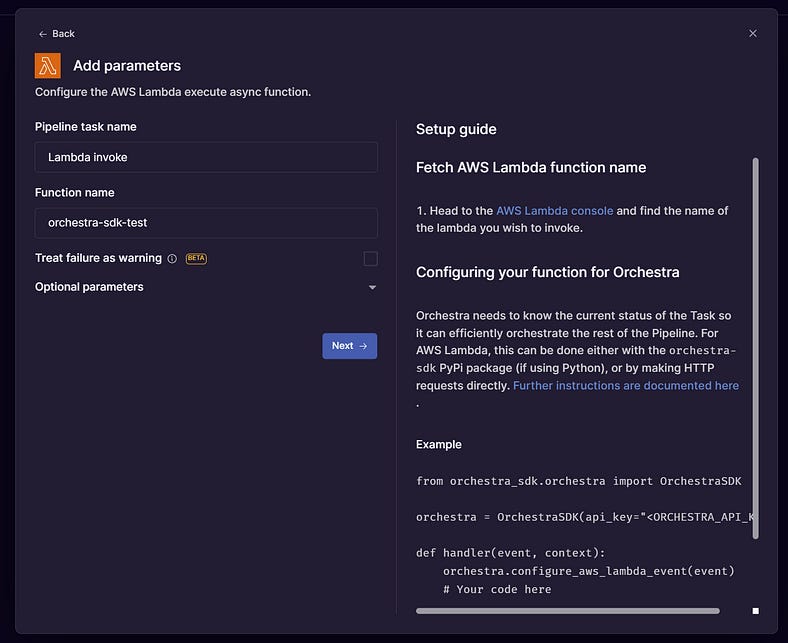
This unlocks some nice possibilities, like orchestrating multiple AWS Lambda Functions at once without AWS Step, or running AWS Lambdas in parallel with other data ingestion processes such as Fivetran, Airbyte or Portable Syncs.
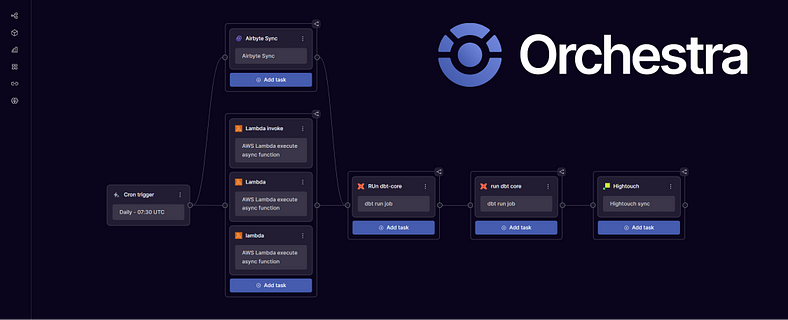
Conclusion
We’re excited to be adding value to data teams through first-class observabilty and support for Python Processes in traditionally non-monitorable structures like AWS Lambda.
We genuinely believe in the principles behind modular architecture, and hope the illustration of the value-chain resonates with you. Having an understanding and an ability to run python where it needs to run without being penalised is imperative to managing large data infrastructures at scale.
To learn more about Orchestra, why not check out the website or the 🧨 demo environment 🧨. A good place to start is also the Python SDK.
If you’re ready to give it a spin check out the platform here. If you want to speak, you can book in some time here.
Happy Building 🚀
Find out more about Orchestra
Orchestra is a platform for getting the most value out of your data as humanely possible. It’s also a feature-rich orchestration tool, and can solve for multiple use-cases and solutions.
Our docs are here, but why not also check out our integrations — we manage these so you can get started with your pipelines instantly. We also have a blog, written by the Orchestra team + guest writers, and some architecture diagrams for more in-depth reads.