


What is a Control Plane for Data Operations?
Explain Orchestra to me like I’m 5

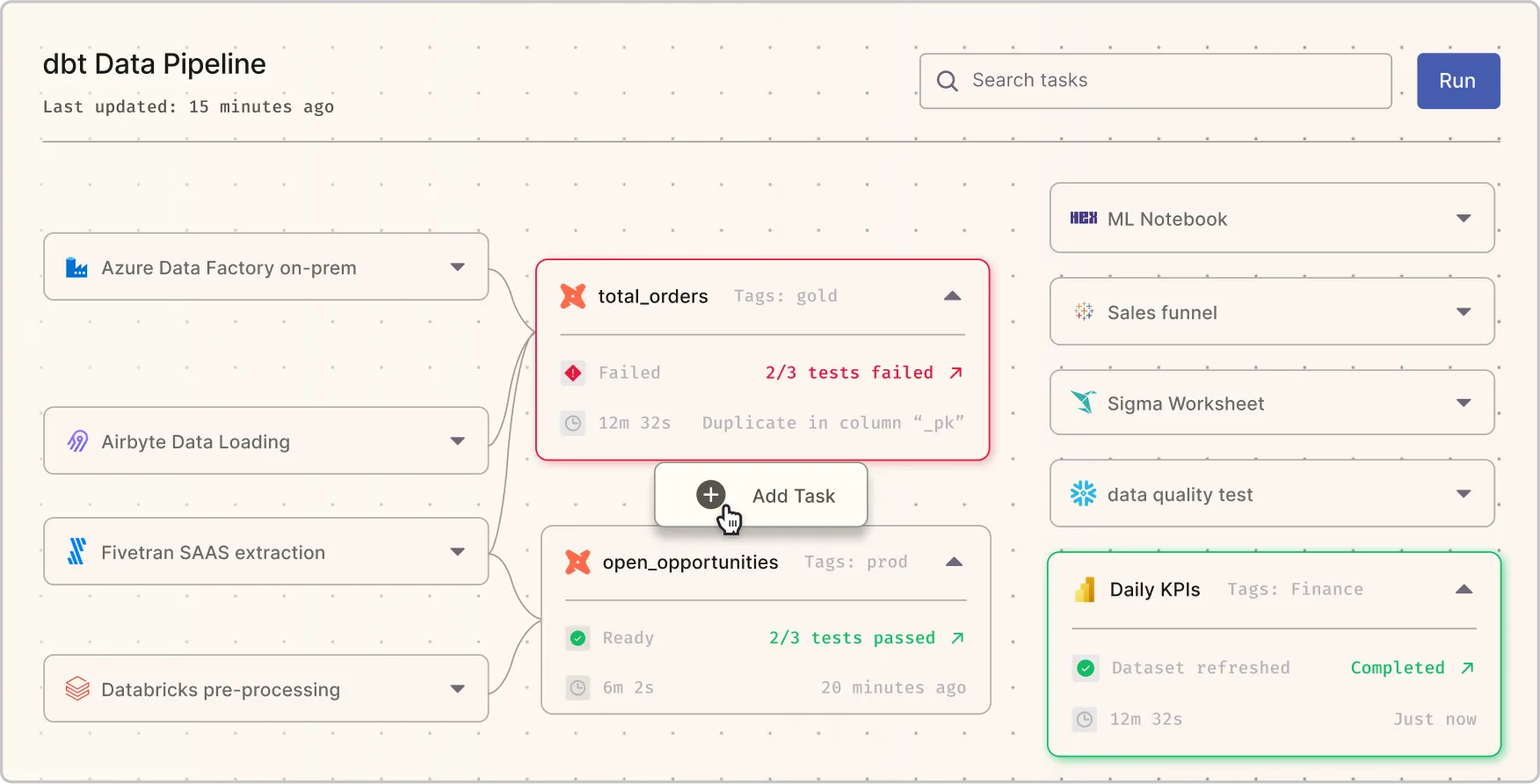
Foreword
Some of the biggest pains we see facing data engineers and analytics engineers is that they spend too much time maintaining boilerplate infrastructure, and still have no visibility into pipeline failures.
It means you’re constantly fighting fires and don’t have time to focus on building. What’s worse is that the business doesn’t trust the data.
At Orchestra we’re building a Unified Control Plane for Data Ops. A Data Status page if you like, with some incredible features to give data teams their time back so they can focus on building.
We are seeing a lot of companies start to bill themselves as a Unified Control Plane for Data Operations. These range from Catalogs, to orchestrators, observability tools, to even dbt Cloud.
It is obvious Data Teams need a single place to view and monitor the health of all their data flows that is easy to use, has the power of a flexible orchestrator / data quality testing, a lot of metadata. Personally, I think the only viable alternative to an Orchestra at this stage is a custom-build + a log-based observability tool. I genuinely think this is a great option for companies where they have top top tier engineers (think Airflow+Datahub). For the other 99% of us, this vision is going to come at immense cost, immense time to value, and is overkill for the vast majority of use-cases.
How is Orchestra a Data Control Plane??
Imagine your entire data stack was connected and you could trigger anything in any piece of cloud or on-premises infrastructure whenever anything happened.
Now imagine that whenever you triggered any of these processes all the metadata from those processes got aggregated somewhere.
Now imagine that metadata automatically got cleaned and surfaced to you in a really nice UI. Throw in automated alerting (based on anything happening in the platform) and a way to prioritise data incidents, and that’s Orchestra. It’s a true unified control plane for your data operations.
What Problems does Orchestra Solve?
Disjointed coordination and scheduling of data pipelines
Without Orchestration, Data Pipelines run on schedules. This requires Data Teams to have know-how of how long things take and when to schedule things.

Not only is this tedious to schedule, but when pipelines break, data teams need to manually rerun things. This leads to wasted time, broken SLAs and a loss of trust in data from the business.
Difficult and tedious debugging
Ok great! You Orchestrated your pipelines, but one has failed. With a tool like Airflow, you might need to go into each individual tool to find the actual error. Orchestra aggregates metadata and provides helpful error messages, so you can debug from one place.

This saves data engineers time and helps pipelines recover faster.
Alert fatigue and unhelpful alerts
It’s a small thing, but building a customisable automated alerting system to teams, slack and email is…maybe not actually as small thing as we realise.
You can easily identify as a proactive rather than a reactive data team by using Orchestra to automatically send you alerts and affected stakeholders. This again builds trust, and saves Data Teams time building the same ol’ infrastructure.
Disparate and untracked metadata
Aggregating metadata is normally left to a separate tool. Some engineers decide to build pipelines to fetch the metadata from their actual data pipelines.
We do the data engineering for data engineers. Because of our unique approach to Orchestration, metadata is automatically collected, cleaned, and surfaced in our industry-leading UI — catalog-style.
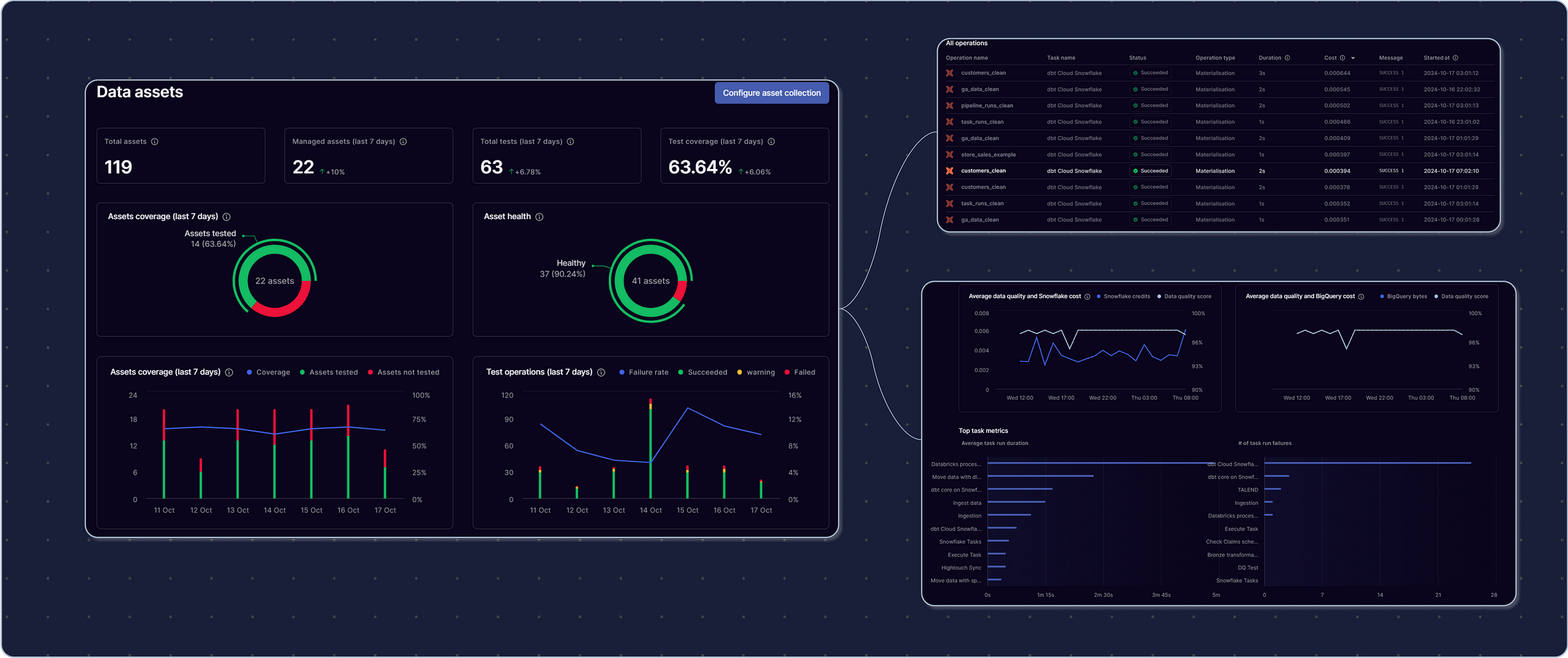
This not only saves Data Teams time building unnecessarily complicated infrastructure, but decreases stack complexity, reduces cost / TCO, and provides engineers with true visibility into everything going on in the data ecosystem.
Bonus: proactively identify data quality issues and anomalies through tracking metadata over time in Orchestra.
How does Orchestra compare to other Workflow Orchestrators / “Control Planes” ?
It’s only natural to want to understand features, so let’s go into that here.
Fully-featured Orchestration Engine: parity
Orchestra has a fully-featured orchestration engine; this means a declarative framework, automatic logging and alerts, conditionality or branching, infinite concurrency, Tasks and Task Groups, Multiple Triggers (although we don’t support sensors yet), swish UI, the ability to re-run nodes from the point of failure.
Ease of use: very high
In any OSS Orchestrator to get anything done you must write python, hand-roll integrations, wait on CI/CD checks, set-up staging environments, and just be really really slow.
Orchestra is code-first (yml based) and GUI-driven. Governance is built into the platform but we will release a full git integration soon.
This means you can develop literally 90% faster and also not have to be a python whizz to be an awesome data platform manager.
Python: basic
Orchestra is written in .yml and is not an open-sourced orchestrator; you cannot run it on your own Kubernetes cluster.
Because of this, you can’t actually do any data processing in Orchestra. We are releasing Orchestra-hosted python later this year (so you write python code, put it in a git repo, we pull it and run it), but it’s not recommended to use this feature for heavy-duty jobs like ELT.
You could interpret this as an advantage for a traditional oss orchestrator, but really we don’t think it’s necessary in a modular architecture (you have ten places to run python already, we can run it if you really want) plus we want you to use us the right way.
Deployment: monolithic vs. modular
A Traditional Orchestrator is a monolithic deployment.
You write all your code in python, spin up two Kubernetes environments for testing and prod, CI/CD checks that are actually really hard to do, and then hand-roll your entire data platform in python with an army of developers.
Orchestra works well with a modular architecture where you’re using a service/saas tool for ingestion, something for transformation (Orchestra can also run dbt Core), a warehouse, and different BI tools / reverse ELT / data science platforms.
Orchestra sits on top and you just use it to connect and monitor the whole stack. It is full managed SAAS, does no data processing, and by and large our users say the difference between this and something like Airflow is night and day.
GOVERNANCE
We’re still working on how we hash this out, but there is a huge issue in data at the moment which is Governance.
Companies hit scalability problems and decentralise data teams.
Then this creates model sprawl and dashboard sprawl, duplication, decision inertia. Complete mess → governance issue.
We believe thinking about Data as a Product in a Modular Architecture is the answer. This way, anyone can make changes to production code, however the criteria around what constitutes a data product people actually care about is a conversation that happens.
It’s definitely 80% process. But when you realise what the process entails (tracking of metadata, having a UI anyone can use, orchestration observability AND data quality all in one place) you’ll hopefully see that our vision is to both save data teams’ time through managed infrastructure AND to make them more effective by giving them a framework for focussing on what matters.

That’s all for now
We are still trying to execute on a fairly bold vision here. There has been a tendency in data for things to get a bit too unbundled, and issues data teams face (like wanting column level lineage, or visibility into their data pipelines etc.) now are “solved” by a plethora of vendors, each fighting for very small pieces of pie.
We believe one thing that sets us apart is that we’ve worked as data engineers, software engineers, analysts and everything in between. We believe that in addition to being a crucial piece of infrastructure that every data team needs, that a Unified Control Plane for Data Operations can do more.
Indeed, that is putting business and data operations at the heart of the platform. It should be a way to Govern, a way to reduce footprint (rather than only increase it), a way to have discussions with the business, a way to bring people in.
You can learn more on the Orchestra website or you can connect with me on Linkedin.
Find out more about Orchestra
Orchestra is a unified control plane for Data and AI Operations.
We help Data Teams spend less time maintaining infrastructure, make them proactive instead of reactive, and ultimately win trust in data and AI from the Business
We do this by consolidating Orchestration with monitoring, data quality testing, and data discovery. You don’t need an observability, lineage, catalog etc. with Orchestra.
Check out