
What is Data Orchestration and why is it misunderstood?
Data Orchestration has often been confused with workflow orchestration. Workflow orchestration is the process of triggering and monitoring the status of tasks; nothing more, nothing less.


Preface
This post is part of our long-reads series. I’m often asked what Orchestra does and how it fits in the landscape we have today. I, alongside many actual thought leaders, believe there is a big difference between “data orchestration” - the process of reliably and efficiently moving data into production, and workflow orchestration. In here, we dive into what orchestration is, how these concepts interact with it, and take a closer look at why some platforms offer orchestration capabilities but are actually a bit more. This is all tied to the concept of an “Orchestration Pyramid”, which is just a diagrammatic representation of how a complete data architecture might look. This first appeared on the Orchestra Blog.
Introduction
Data Orchestration has often been confused with workflow orchestration. Workflow orchestration is the process of triggering and monitoring the status of tasks; nothing more, nothing less. Its essence is the batch or “not-real-time” analogue of streaming and event-based systems / microservices; in the absence of multiple independent microservices with well-defined data contracts between them, a workflow orchestration tool takes responsibility for triggering and monitoring tasks.
Data Orchestration, we believe, is a subset of workflow orchestration - it is the process of releasing data to a production environment reliably and efficiently. This may include elements of data movement (“EL” in “ELT”), data transformation using Python, Spark or SQL (The “T” in “ELT”), elements of environment management (CI/CD for Data or GitOps for Data or Continuous Data Integration and Delivery), role-based access control (“RBAC”), alerting and monitoring, and data observability.
What is misunderstood about this process is that there is so much more to reliably and efficiently releasing data into production than simply writing the execution code within a python repository with workflow orchestration logic.
There is the CI/CD for that code. There is then the CI/CD for the data. There is alerting, the gathering of metadata / ensuring data is collected, lineage, and so on and so forth. A brief tour of the Modern Data Stack or “MDS” instructs the practitioner to purchase multiple tools for these purposes.
This presents an interesting problem statement for intellectual proponents of the data industry, who believe that software best practices can be copied one-for-one and printed upon data professionals. If that’s the case, then why is data orchestration so complicated? And why do the so-called “experts” advocate the purchase of dozens of tools for data practitioners?
Data Orchestration: a brief history, what it is and why it matters
Before diving into its misunderstood nature, it’s helpful to understand the function of data orchestration from base principles, as well as its history.
Data Orchestration in the popularist data sphere has its roots in big tech. Luigi was spun out of Spotify in the early 2010’s. Airflow, the winner in that particular battle and the industry heavyweight came from AirBNB. Meta have a very similar, internal, non public tool called DataSwarm.
For us data engineers, Data Orchestration platforms (or more accurately, “workflow orchestration platforms”) have been open-sourced. This is important, as it means their architecture is quite similar - these packages can be run on containers which need to be deployed in such a way that they can be scaled up and down, should they need to be.
Since these, there have been multiple other open-sourced workflow orchestration packages. By contrast to Airflow and Luigi, which were truly open-source (Airflow is, after all, part of the Apache Software foundation), Prefect, Dagster, Mage and now French-born “Kestra” all claim to be better, easier, and slicker alternatives to Airflow - relatively nice to organise data.
Fundamentally, they are all, extremely similar, offering a framework to write code and execute directed acyclic graphs or “DAG”s within some containerisable environment. Doing this yourself is free, and you will pay their parent company (respectively, Prefect Labs, Elementl, Mage and Kestra who are eponymous) for deployment and additional cloud functionality such as logging, role-based access control, customer support, amongst other things.
What is interesting, is that in the last 5-10 years, is the emergence of two driving forces in data. The first is the rise of the “Modern” data stack or “MDS” - however it’s more accurately a “Modular” data stack. In part proliferated by much venture capital money into the data industry, the modular data stack represents a huge contrast to what workflow orchestration platforms like Airflow were initially used for.
Airflow was a popular framework, not just for triggering and monitoring tasks, but also for the logic of those tasks themselves. There are countless articles on how to ingest data using Airflow, how to transform data using Airflow, how to copy it using Airflow, and so on and so forth. This places your Airflow or workflow orchestration platform at the centre of your compute bill, and also drastically increases the computational power you need to run through your orchestrator.
The MDS counters this, by offering users different components that specialise in different parts of your data release pipeline. So for example, using Airflow to trigger and monitor a tool like Fivetran, Airbyte, Stitch, Portable or a streaming engine like Striim, Redpanda, Estuary or Upsolver is different to writing that code yourself and executing it within Airflow itself.
The second big driver in data is how releasing data into production reliably and efficiently is vastly more complicated than releasing code. This makes intuitive sense - codebases are simply repositories of text, and are quite small. The functionality of the code needs to be tested, and requires a staging environment to be done robustly. However this is the biggest overhead to a sensible operation.
Data, by contrast, can be BIG (see Data Lake Considerations). It can take up petabytes of space. Transformations are complicated, and expensive. Complicated data sets may entail dozens of steps, which creates data release pipelines that are longer than their software counterparts.
Where software teams that adopt a microservice architecture can operate relatively independently due to the well-understood nature of data contracts, data teams cannot, since consumers of data rely on producers of data, which creates natural but undesirable bottlenecks.
The upshot of this is that releasing data reliably and efficiently into production is hard, and requires a lot of functionality to be done well. This includes but is not limited to: data contracts, data quality testing, smart-management of multiple environments, CI/CD for code, GitOps for data, clear and well-established lines of communication between multiple teams, data governance, FinOps, alerting, data lineage and metadata aggregation.
By understanding what data orchestration is, or more accurately, what workflow orchestration is, we’ll see why although it is critical to creating awesome data pipelines, it’s not enough.
What is Data Orchestration and why teams start orchestrating
The beginning state, that is all too familiar for anyone who’s built a data team from the ground-up, is the scenario where an organisation wishes to make the most of its data. However, it lacks having the customer data all in one place.
It lacks the ability to centralise the customer data, and keep it refreshed. It may lack quality (the data may be unreliable, or incorrect). Furthermore, it may lack the talent to make the most of the customer data, even if it’s made available in a clear and refreshable manner.
In order to faciliate the technical part of the solution to this problem, data teams need to build data pipelines or was we prefer to call them, data release pipelines. These are essentially strings of operations designed to:
Centralise data or move data
Transform and manage data
Aggregate Data
Organise data (execution plans for DAGs in logical folder structures)
A simple example would be to use a third party ingestion tool to move data from a SAAS application to a data warehouse. The pipeline would then execute some SQL, to clean and aggregate the data in the warehouse. The pipeline would then be complete; the data organised.
A workflow orchestration tool (not a data orchestration tool) is necessary to reliably and efficiently execute this flow. The workflow orchestration tool achieves the following benefits:
Data Governance and expectation control
By specifying what data engineers want to happen in the data orchestration tool, data teams benefit from explicitly stating what they expect to happen. This is absoultely fundamental for data governance. Without this, organisation of customer data is essentially a buzz of activity, and auditors have no way of understanding what of this activity (if any) is actually intended and therefore necessary.
Avoiding redundant compute and polluting data quality
Because the orchestration tool is responsible for triggering and executing jobs, downstream jobs are skipped if upstream jobs fail. This means data quality is never compromised if a workflow orchestration tool is used - the worst that can happen is that data comes out of date.
Furthermore, this also avoids redundant compute. If all tasks happened on a schedule, irrespective of upstream tasks’ status, then downstream tasks would need to be run at least twice in order to recover from errors. This redundant computation is avoided when a workflow orchestration tool is used.
Reliability and maintainability
An orchestration tool stores logs of tasks, so in the event an error is introduced into the data release pipeline, the orchestration platform can help data teams easily maintain it through metadata provision.
This is how workflow orchestration or “data orchestration as we know it” operates in a traditional business setting and why data teams that are successful and scale effectively bring on a workflow orchestration tool early on.
Unlocking success in data in 2024: the transformative benefits of end-to-end and holistic data orchestration
End-to-end and holistic data orchestration and data management covers some of those additional pieces of functionality we believe are necessary to reliably and efficiently release data into production. We discuss these in this section and how Orchestra can enable this. It assumes that different parts of the data pipeline are carried out by a combination of third-party data saas tools and home-built code, so data teams can use the right tool for the right job.
Intelligent and complete metadata gathering
In order to understand how an invocation of a pipeline or “pipeline run” performs, it’s necessary to capture metadata from all parts of it. This is extremely arduous to do in a workflow ochestration tool, as you need three tasks.
There is one to trigger the task, one to poll for the completion of the task, one to fetch the metadata for the task, one to store it, one to clean it, multiple to summarise it, and so on. Orchestra intelligently gathers and cleans metadata away from core pipeline logic, which means engineers debugging pipelines triggered and monitored by Orchestra get access to everything.
End-to-end data lineage
Data lineage allows teams to see what business assets depend on what data orchestration processes. It serves a purpose for debugging, but also is an important control for data governance and auditability - understanding access to disparate data sources in the context of a lineage graph is particularly powerful.
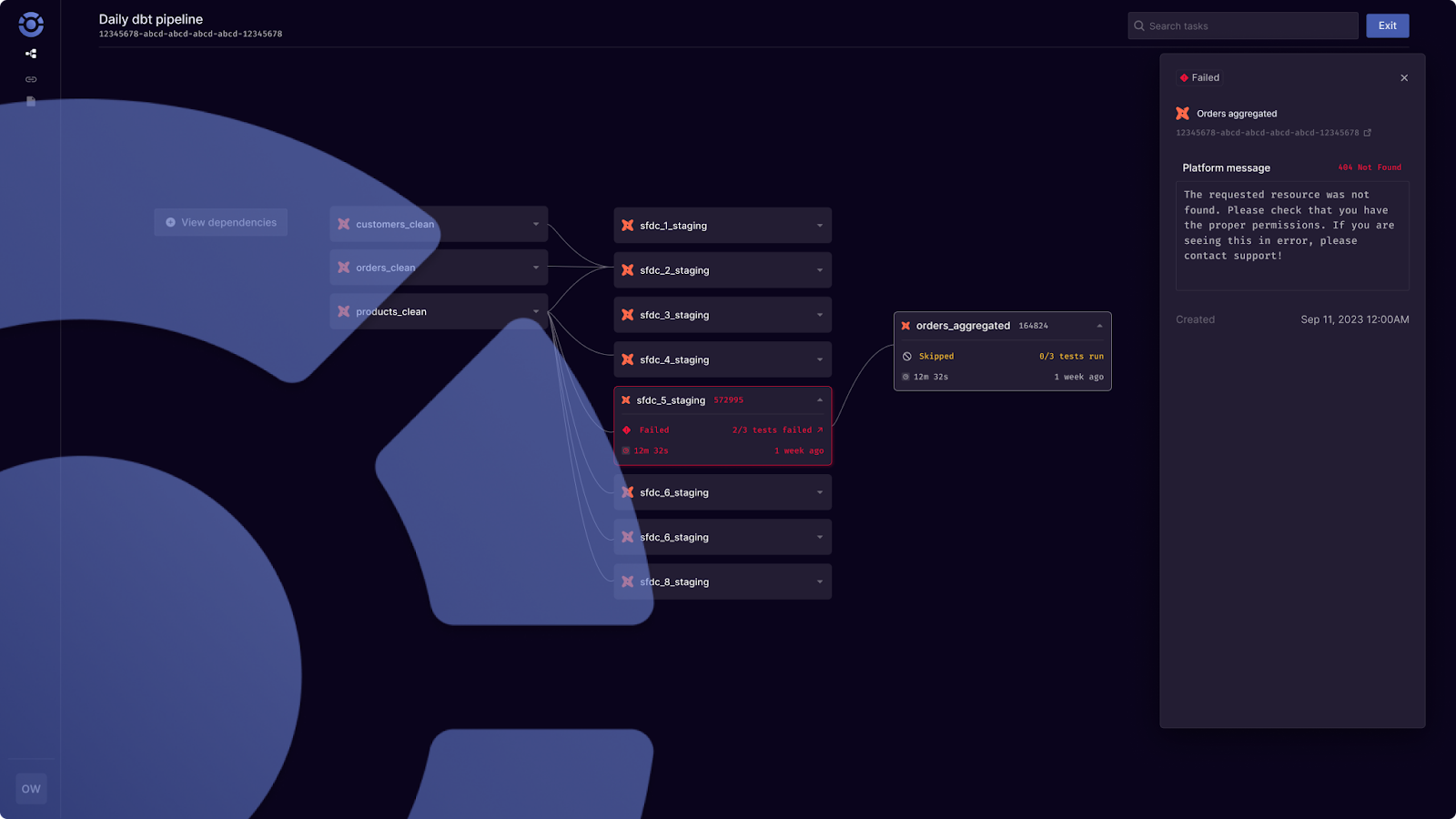
An orchestration tool contains a plan of what depends on what, and what data teams expect to happen. It is therefore the natural place for engineers and product managers to view lineage graphs. Orchestra has full visibility of data assets and operations executed and monitored by the orchestration platform, so users can see helpful metadata but also things like access control (for data governance) in the context of a lineage graph.
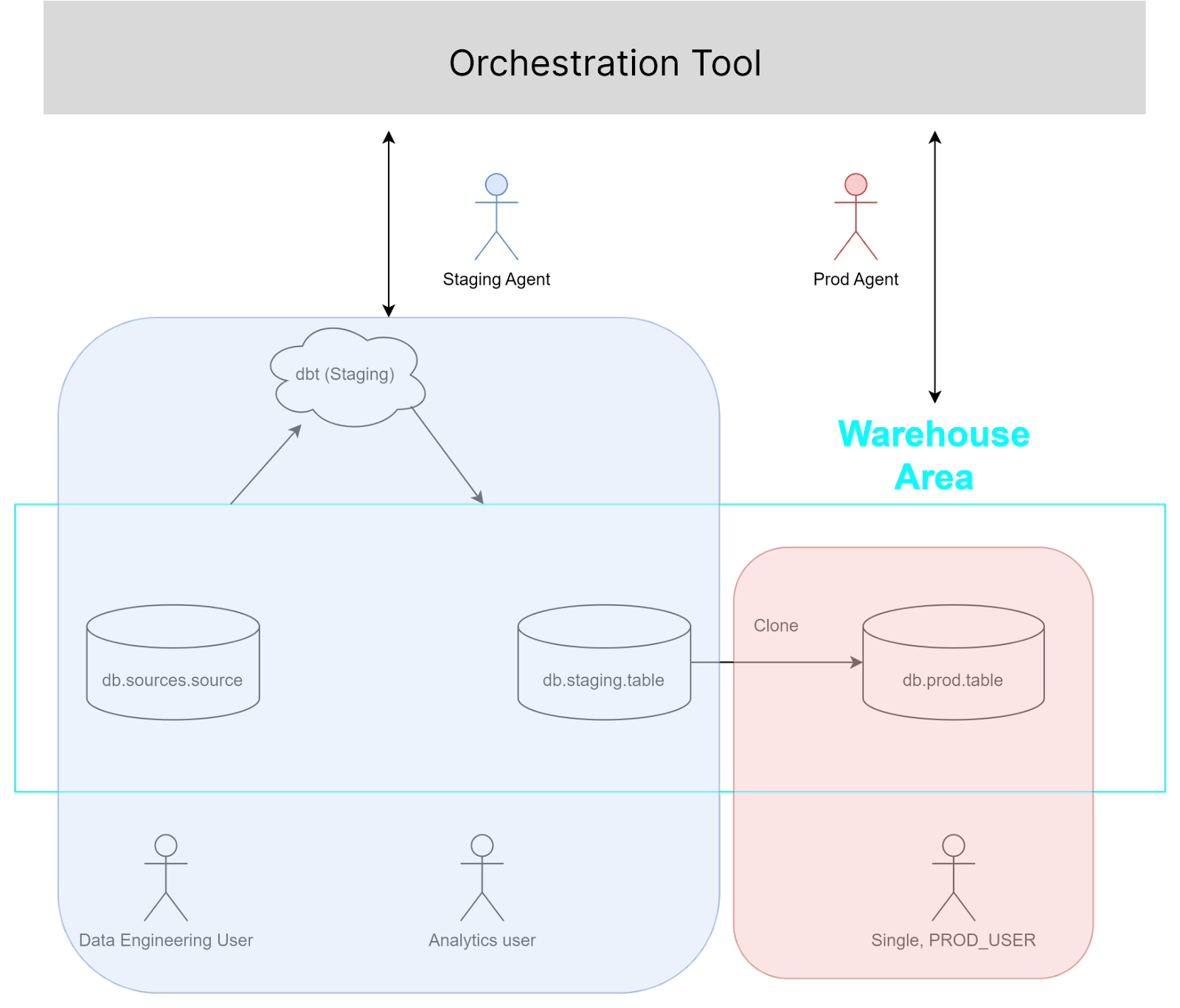
Environment management
Environment management is one of the most misunderstood concepts, I believe, for most data engineers. While a “staging environment” in software is “an exact replica of production”, we need to zoom out to understand its necessity - in order to test a piece of software, it has to be run, somewhere. It’s a bit like an army squadron practicing a raid on an exact replica of a real-world hideout. The real-world needs to be replicated, and it needs to be done exactly.
For data, this isn’t necessary in most environments because of the ability to clone or “point” to datasets. This is similar to the concept of blue/green deployments in software engineering. It means that data orchestration tools basically get to handle environment management by “pointing” production resources (which are possibly disparate data sources) to the most up-to-date data assets, which may exist in a staging environment in the context of either code changes or new data arriving.
This is very simple using a tool like Airflow, although it requires an additional set of tasks (which is a to clone or “Point” production resources at the latest and most up-to-date data assets in a data pipeline).
Unfortunately, in practice this nuance is often lost, and results in the most “rigorous” data teams having one environment (with extra storage) for staging and one for production. This results in literally double cost for any data pipeline, in addition to doubled latency. Arguably, the pipelines also fail more often.
Orchestra allows users to easily enable environment management by having different connections for different data environments (subdirectories in Azure Data Lake Storage, Schema in Snowflake and so on) as well as out-the-box commands for cloning data assets and managing them effectively.
Data Product Enablement
One of the biggest challenges for data teams is understanding the value data pipelines bring. Having a single pane of glass to see both cost, usage and customer data is helpful in the context of data products, because it provides a current and historical view of the value data pipelines actually bring. This is impossible using workflow orchestration tools, because they are necessarily confined to triggering and monitoring pieces of code within their ecosystem. The Orchestra platform takes care of this.
Data Governance and Role-based Access Control (“RBAC”)
Tied to environment management, having RBAC in place as part of a data orchestration pipeline can be extremely valuable. For example, you might inspect a list of individuals to be added to and removed from lists as a step in a data pipeline. Ensuring separation of production and staging environments also allows solely programmatic access, which is helpful in terms of “locking down production” and achieving effective data governance. This is one of the Orchestra platform’s killer features.
Cross-functional collaboration; data mesh and scalability
At a large scale, it may not be feasible to have all your code in a single repository. Indeed, it may not even make sense to use a single orchestration tool (for example, analytics engineering teams like using dbt, as opposed to Airflow or Prefect; those using data analysis tools). It’s therefore vital for technical and non-technical team members to have an interface that is capable of triggering and monitoring multiple tools and systems.
While Data Observability platforms are capable of aggregating all this metadata, it comes at a high set-up cost and maintenance cost due to the ongoing and somewhat incessant polling required. Workflow orchestration platforms often really struggle to play nice with other instances of themselves and to this end even dbt have implemented cross project ref which is only available to enterprise customers.
Orchestra not only interfaces with infrastructure pieces like the Airflow and Prefect Servers, but also has highly flexible observability components like being able to fetch metadata from S3 and trigger and monitoring tasks in Cloud Infrastructure such as ECS containers, which means it actually complements existing Workflow orchestrators if necessary. This means you get the benefit of flexible orchestration, and consolidated, aggregated metadata in a user-friendly UI.
Complete flexibility and interoperability
The greatest strength of a code-first workflow orchestration package is the ability to interface with any API; just write the code and you are good to go. This, however, is also its greatest weakness as it introduces a cost (of maintenance and of execution). Holistic, end-to-end data orchestration tools and platforms are completely interoperable (with all the functionality above) with specific pieces of data infrastructure - not necessarily random APIs - but APIs like AWS’ and BigQuery’s are a must.
Orchestra is the only platform to have complete custom-built integrations with data tools and data infrastructure providers, which we believe removes a lot of boilerplate code maintenance many data teams currently do to ensure their workflow orchestration pipelines are flexible and interoperable with a wide number of tools.
Tool up for Success: picking the best orchestration tools of 2024
Picking a single best-in-class tool and trying to ensure it’s interoperable with everything else can be an expensive game to play in 2024. Many tools with the best orchestration features are all-in-one platforms, so we give them an honourable mention here.
For something truly interoperable with any Modular Data Stack and is low-code, there really is nothing like Orchestra. Orchestra allows users to build DAGs using a slick no-code UI or by writing .yml for those requiring git control.
The core orchestration platform triggers and monitors tasks, which includes fetching granular metadata and exposing data lineage on an execution-by-execution level. This gives data engineers unparalleled visibility into why data release pipelines fail.
The UI also enables environment management, which is crucial for keeping data quality high. Platform admins can also control access to data assets and update these as part of data release pipelines, which encourages holistic data governance with security in mind. The final killer feature is the ability to group pipelines into products, and bring in both cost and usage metadata. This allows data product managers as well as engineers to understand the value of their data pipelines.
For all-in-one platforms with best-in-class orchestration:
Databricks gives you a warehouse, BI, Data Lake storage, and of course, databricks workflows. This is their code-first orchestrator that also has a no-code/low-code UI which is very handy when implementing a modular data stack on databricks. The cons are you still need to write code to do anything outside of databricks, but for DBX tasks, it’s a dream. Unity Catalog for Metadata is also a no brainer. A killer to manage data.
Y42 is a complete data platform that gives you an ingestion tool, a transformation tool, a warehouse and an orchestrator. You can build super robust pipelines using Y42, and they also provide GitOps for Data, which means data teams can see CI/CD runs and timed runs in the same place, which is extremely powerful and a very unique feature
Keboola and Weld are lite-er versions of Y42 that have a wide range of out-the-box integrations for ingesting, transforming and exposing data in BI and in data science projects. They’re very easy to get started, and very reasonably priced for data-lite workloads. Very easy to manage data.
Ascend.io is a data automation platform that streamlines and simplifies the process of data integration, data orchestration, and data transformation. It allows businesses to efficiently acquire collected data, process, and analyze data from various, disparate data sources (using data analysis tools), making it easier to derive insights and make data-driven decisions.
With Ascend.io, you can create data pipelines, automate data workflows, and ensure that your data is always up to date and accessible for analytics and reporting purposes. Their USP is do things quicker, more cheaply, ontop of Snowflake, Databricks or Bigquery.
For those of you looking to control everything in code and deploy it on Kubernetes/ECS yourselves:
The OG of workflow orchestration. Receives significant investment via the cuckoo of the data orchestration world Astronomer - a private company with no official affiliation with Airflow save for the many millions they funnel towards the “open source devs”/employees working on the AIrflow Project. Astronomer profit from large, unmanageable, overly-complicated AIrflow repositories they can run on their servers for large corporations.
Airflow gets the #1 spot because it A) can do everything abd B) has the “deepest” level of understanding in the labour market.
Prefect is written amazingly well, and has lots of nice features only battle-hardened devs will appreciate. It is, simply, the best way to run python on Kubernetes or ECS. Python-based data orchestration processes are a joy in Prefect, but a lot of effort to maintain at scale.
The team at Dagster / Elementl share a lot of our core values, particularly with regards to end-to-end and holistic data (not workflow) orchestration. You can see this through their awesome UI, asset-based scheduling, backfilling and dbt integration features. Although mapping data assets and end-to-end lineage are undoubtedly huge benefits of the Dagster platform, the core hurdle of needing to write and maintain a single repository of dagster code remains.
Noble France bring us Kestra, which we posit is derived from the English “Orchestra” and re-branded to the bi-sylabled and catchily spelt “Kestra”. Kestra’s orchestration layer is written in .yml, and includes some helpful out the box plugins for common data tools like Fivetrand and Airbyte. This is the closest we have come to seeing fully-managed easy-to-use integrations for data teams.
This is combined with the ability to execute arbitrary pieces of code, in multiple languages (which I guess is nice if you believe variety is the spice of life). However the company is still very young, and the integrations with analytics engineering environments are pretty early and observability / data products does not appear to be a huge priority for the Paris-based team.

Worthy mentions for Analytics Engineering
If you only care about executing dags of SQL and Python effectively in a data warehouse, then you can of course use dbt Cloud. Dbt Cloud also an out-the-box implementation of dbt’s slim CI (for CI/CD for Data) which is powerful, but expensive.
If you use Snowflake, you must must must check out Coalesce.io. We’ve written more about that here, and it’s truly excellent for reliably and efficiently releasing data into production in Snowflake environments. These are all technically data analysis tools too.
Data Orchestration Implementation: deriving the fastest time to value
Typically, many data teams only think about orchestration, observability, governance and so on after they’re well into their data journeys, after teams cross the 4 or 5 person threshold.
We believe that these structural, far-reaching concepts should be considered earlier. After evaluating your needs in terms of data size, latency and use-case (see here), an orchestration platform should be chosen. You may choose Airflow if your team has a lot of experience using it.
If the team has strong Python skills but not necessarily Airflow, you could choose Prefect. If you have no platform team or want to save on overhead, a fully flexible and interoperable cloud-based orchestration and observability tool like Orchestra will be appropriate.
The fastest time to value will then be to focus on building a small number of data pipelines or data products, focussing on both their cost to deliver and their usage. For example, you might have an hourly pipeline that produces data for a few dashboards. Perhaps these are customer usage dashboards for different teams like Sales, Product and Solutions Engineering. Note as well - the metadata collected should be available somehow.
With two basic datapoints like cost to deliver (e.g. in Snowflake credits) and in usage (for example, the number of queries to these dashboards or the number of active users querying), data teams can instantly compare ROI across data products and use this to prioritise data initiatives and critically evaluate the success of existing ones, before investing time and money building more and more data infrastructure.
Data Orchestration trends in 2024 and beyond
In this whitepaper, we’ve dived into the differences between workflow orchestration and automated data orchestration. We’ve seen that the automated data orchestration process of reliably and efficiently releasing data into production requires much more than robustly executing and monitoring Tasks in a DAG.
There are seriously transformative benefits to implementing end-to-end and holistic, automated data orchestration, however building a system that enables data products, computes lineage, aggregates metadata / ensures metadata is collected and so on is challenging and frought with difficulty.
While existing workflow orchestration platforms like Airflow and Prefect can no doubt be adapted to implement these features, it requires a technically strong data team which may not be available to many companies. Some “all-in-one” platforms that are lower-code such as Weld, Keboola or Ascend.io may represent better alternatives. Orchestration and observability concerns can also be addressed by choosing a large data platform like Databricks.
One trend we see is growing complexity in data, which lends itself to a modular data stack. We believe this increases the emphasis on the interoperability of data stack tools that operate “above the parapet” and deal only with metadata rather than data itself - just like Orchestra. This is why we believe Orchestra represents the easiest and most compelling way to get started with and operate data release pipelines at scale.
Another trend is, of course, artificial intelligence. We believe Data Teams will need to trigger and monitor workloads that primarily process unstructured data such as documents and emails. This will be extremely challenging to do natively in python-based workflow orchestration platforms, and we will see saas tools built specifically for this purpose that Orchestra will invest time in, understanding the best way to trigger and monitor jobs in these services (as well as how they can facilitate data products).

The final important trend we see affecting automated data orchestration is the advent of data products. Understanding the ROI of data initiatives is imperative to effectively scaling data teams. It is almost impossible to do without gathering information from the orchestration and control plane at the same time. This leaves observability tools completely in the dark, since they have no context of why operations are executed what initiatives their costs relate to.
A platform like Orchestra gives product owners the ability to see incredibly granular cost information; not only cost per data product over time, but cost per run, cost per tool, cost per a given query or data asset by run within a specific tool. It remains to be seen how much of this is necessary to do an adequate job, but what is certain is that this information is a must for any data team concerned with generating an ROI.
We hope this material has been helpful to you in explaining the differences between data orchestration and workflow orchestration. We hope that the reasons for building an overarching system whose goal is to reliably and efficiently release data into production rather than a large Airflow repository that simply executes tasks in a schedule is compelling.
There are extremely exciting trends in data that point to it continuing to be a fascinating and fast-moving area of tech, and we’re very happy to be at the forefront of innovation in data orchestration, observability and data products.
Find out more about Orchestra
Orchestra is a platform for getting the most value out of your data as humanely possible. It’s also a feature-rich orchestration tool, and can solve for multiple use-cases and solutions. Our docs are here, but why not also check out our integrations - we manage these so you can get started with your pipelines instantly. We also have a blog, written by the Orchestra team + guest writers, and some whitepapers for more in-depth reads.
Also we did a load of cool semi AI-driven Guides that are actually pretty good:
Any thoughts on Windmill or mage.ai?