


What is open-source workflow orchestration and when should you move on?
Open-source workflow orchestration solutions have existed for decades. In this post we talk about their pros, their cons, analogies with knives, and what moving-on might mean


This is brought to you by Orchestra.
Introduction
I’m a data engineer by trade but I didn’t come from a software engineering background. This has given me a semi-unique / not that unique perspective on how to run efficient data engineering pipelines — when I was working at JUUL, or Codat, I gained relatively little enjoyment from maintaining and debugging pipelines compared to working with stakeholders to create business value (creating dashboards and doing data science projects are fun. Working out why AutoLoader is different for Parquet vs. Json is not).
Upon discovering CI/CD in software, and upon having it impressed upon me by a team much smarter than me, I was slightly distressed at the amount of platform engineering the internet suggested I do.
Specifically, I realised our data pipelines had no Continuous Integration. When we pushed code to our dbt repo, sure we could have dbt’s Slim CI but given our massive data volumes, even using the -defer flag wasn’t exactly cost-effective. Creating our own janky github actions to clone tables, materialise views, and re-clone tables back into production didn’t seem like a worthwhile use of time in high growth environments.
Continuous Delivery we did have! Sort of — we had jobs running on schedules. The de-facto standard in DE as we all know, is to use an open-source workflow orchestration package to create end-to-end pipelines. However this required deployment onto Kubernetes — again not a concept or even a word I had heard of before.
And just to be completely clear, I am the CEO of Orchestra which is a platform for releasing data into production reliably and efficiently. This article is biased. If you work for Astronomer or you’re a core committer of Airflow that brews their morning coffee with Airflow who’s having a bad day, go back to Reddit! Medium is for people with sanity who enjoy good writing.
Ok. Let’s get into what an open-source orchestration tool is.
What’s an open-source Orchestration tool?
Let’s start with a definition from one the projects themselves:
Apache Airflow™ is an open-source platform for developing, scheduling, and monitoring batch-oriented workflows
There are a few components to this:
Developing
Airflow is written in Python, and you create graphs (DAGs) in Python. This is great, if your workflow is indeed, a step of Python scripts that need to be run.
As Data Engineers, this isn’t always the case. For example, suppose I’ve a lot of .parquet files sitting in S3. I might want to develop by writing pyspark jobs that manipulate .parquet files. This isn’t super straightforward using an open-source workflow orchestration tool alone. See, for example, how one does things using Lake FS:

The point is, the development environment is important. The example above relates to scenarios where you engineer data in an object store. Doing data engineering, or analytics engineering as it’s more commonly known, on a data warehouse, requires a separATE dev setup — the most popular is using dbt and the dbt cli. There are extensions which you would use together with your workflow orchestration package of choice.
Monitoring
Monitoring relates to the gathering of metadata from jobs. As data engineers, we’re typically interested in a few things
Graphs of data assets (i.e. “my tables”)
Dependencies (What table does this dashboard depend on)
Processes (what processes affect what tables)
Run duration (how long did this thing take)
Error messages and codes
Number of rows updated (how many rows were added to this table, how many .parquet files were added to this data asset)
Supplementary metadata (how many snowflake credits did this job use?)
Gathering this is easy using an open-source orchestration package. But it requires you to write a fair bit of code. There are lots of extensions like dbt_artifacts that can do some of this heavy lifting for you, but at scale writing tasks in DAGs to collect metadata is, I think it’s fair to say, perceived as a lot of effort.
There are companies that will do this for you, such as Monte Carlo.
Here’s an example of how you can create a complicated DAG that includes granular collection of metadata:
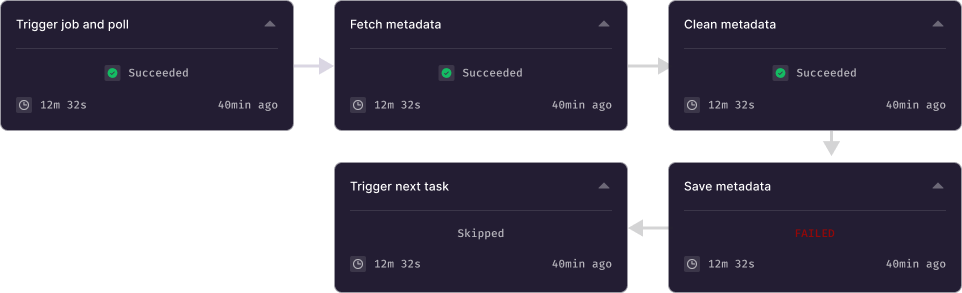
Batch-Orientated
An easy way to understand Batch is simply by thinking of something that needs to run on a schedule. Batch and streaming are not opposites, but rather sit on the same spectrum, but at different ends.
Software systems do not need an orchestration tool, because they speak to each other in real-time and are event-driven.
Data systems are not the same, because thinking of data transformation at an event level isn’t straightforward. Sure, you can join streams using a stream processing engine, but incrementalising window functions efficiently is actually really hard — so hard it’s still unsolved.
This necessitates an element of batch, and is where open-source orchestration packages come in.
For some workloads, you might not want to do this. Two of the leading providers of data warehousing have solutions that enable a stream like experience. Databricks’ Delta Live (which is built on Spark structured streaming) and Snowflake’s Dynamic Tables.
Workflows
Many open-source orchestration tools are frequently described as Swiss Army Knives because of their almost infinite levels of flexibility.
It’s therefore more apt to describe them as “workflow” orchestrators vs. something data-specific. Prefect really lean into this.
The process of building a data engineering pipeline is crystallising as something a bit more specific than just a series of tasks that are run as a workflow. Indeed, it’s the process of releasing data into production reliably and efficiently, and more and more it resembles Github action-style workflows you find in software engineering.
This leads to a lot of boilerplate code if done using a workflow orchestration tool. Every DAG needs to handle things like cloning datasets, materialising data, running tests, and re-cloning the data back into production. All very doable, but not out-the-box.
Other components
You will have noticed that “developing”, “monitoring”, “batch-oriented” and “workflows” are all taken directly from the definition of the project itself.
There are other components that are worth considering too.
The first is the concept of integrations or plugins. Plugins are the boilerplate code you need to run tasks that require interactivity with external systems. Orchestration tools have a rich variety of plugins, all open-sourced. There are pros and cons to this approach, that are clearly so important to us that Forbes even wrote an article about it. Pros include wide coverage, price (they’re free), and the ability to get rigorous testing through mass use. The con is that if the connector is not good, or is flaky, then as a user you’re left alone. This is why even some companies like Stitch, built on the Singer open-source project (which is what Meltano is also built on) distinguish between managed and non-managed connectors.

The second is deployment. With an open-source workflow orchestration package, you need to deploy it somehow. This is non-trivial, and requires thought around concepts like multiple environment deployment and graceful shutdown. The latter of these can lead to particularly gnarly errors. This is all manageable, of course.
Something else to consider is that if you pay for deployment using something like AWS MWAA you solve the problem, but at that point one of the key benefits of using open-source (that it’s free) disappears, and so too does vendor lock-in (you’re locked in to AWS). Which renders this discussion moot. I’ve written more about open-core here.
The final component is to distinguish between execution and orchestration. Orchestration packages’ infinite flexibility allows you to run anything inside it. For example, in Airflow you could run this as a task:
import csv
from data_science import train_func
with DAG(
dag_id="train_model",
schedule="@daily",
tags=["produces", "dataset-scheduled"],
) as dag1:
# [START task_outlet]
with open('big_data.txt') as csv_file: # This has 1bn rows
csv_reader = csv.reader(csv_file, delimiter=',')
output = train_func(csv_reader) # This trains an ML model
# [END task_outlet]This is not recommended, because it needs a lot of compute-power. You ideally need to spread this over a cluster — feasible if you’re already running an open-source package on a K8s cluster, but terminal if you’re running it on a cluster that doesn’t have autoscaling. This gets even more complicated if you need to run compute on infrastructure that requires GPUs, which isone reason why Flyte exists.
There is a risk orchestration packages are abused and used for multiple types of task that require different types of infrastructure to operate reliably and efficiently.
Should I upgrade?
Generally, when things become too complicated to manage on our own, the time is right to upgrade.
With open-source orchestration packages, or indeed, for any own-built infrastructure, this principle holds true. It’s generic advice, but it’s true.
But what does upgrading mean in this context? Suppose you have a big repo with your code in it using one of the packages. What does it mean to upgrade? Sure, you can use MWAA for managed deployment but that doesn’t save loads of time — after all, you still have all those GitHub actions to write and that massive code base to maintain.
What is interesting is that in other parts of data, a lot of the functionality we use has already become available in cheap, commoditised software. Take ELT as an example, there are lots of vendors. This means that the bar to paying for something is lower — building connectors yourself is always an option, but when Portable is $200 a month per connector, the cost is pretty low.
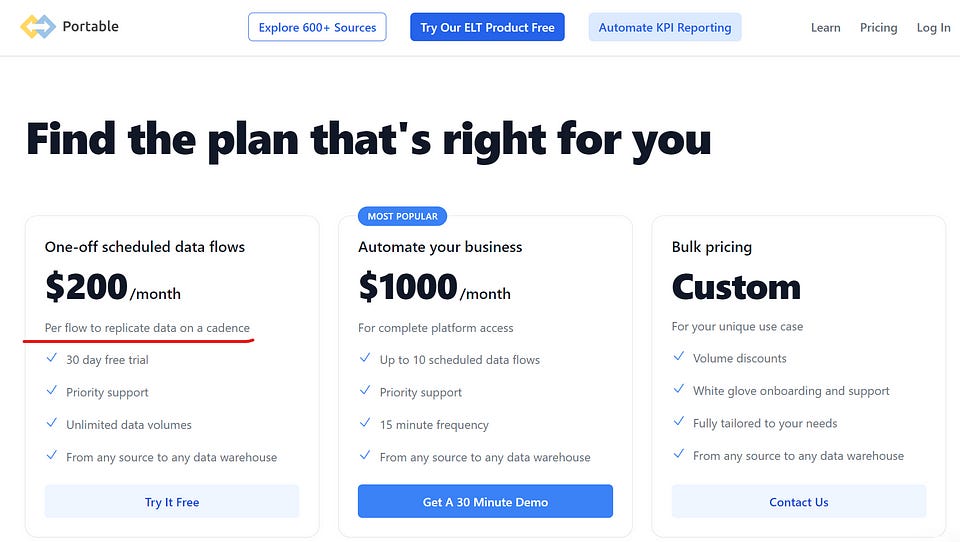
This requires pretty much no code, and it works because we are happy for someone else to maintain connector code, generally as long as we have some control over things like schema evolution.
So where does that leave open-source orchestration packages?
It depends what you’re trying to do
Running workflow orchestration tools for workflow orchestration is pretty easy. Prefect are not wrong that you can deploy their platform for free in a few minutes. The one caveat is that all you’re deploying is a “Hello World” Dag.
The process of reliably and efficiently releasing data into production using best practices is, I think, much more complex. I think the data community will eventually land on something like this, with many of the elements of continuous integration, continuous deployment, monitoring, granular observability, and the like. However as data is such a nascent industry by comparison to software engineering, it’s impossible to know for certain.
I think over time, less people will use these packages for releasing data into production since it’s complex and the scrutiny under which it’s under grows by the day:

This means that for simple graphs with simple tasks, where code bases are manageable, you can probably get away with building and maintaining your own infrastructure. However for complicated data operations, it probably makes sense to offload some of this burden and pay for managed deployment. However this still doesn’t solve the problem of the boilerplate code in your codebase.
I guess it comes down to if you think your orchestration tool should handle things like monitoring, data assets, gathering metadata and so on. If it does, then really there is nothing to upgrade to, nothing to move on to. It’s interesting that at Meta, they just build everything themselves. However what’s inevitable is that the boilerplate code they use to do the things I’ve mentioned above, is sufficiently abstracted such that it equates to the same thing. Needless to say, there is probably a group with people in it like Mike here who are Dataswarm experts and act as a platform team to everyone else. Open-source orchestration packages alone are, therefore, still swiss-army-knives of the data engineering world. Sure, you can pay for managed deployment, but currently there is nothing to really move on to.
Conclusion
I have had a few jobs in my career but one of the most enjoyable was working in a kitchen. It was not a Wetherspoons — who (for my US readers’ benefit) are a chain of pubs infamous for microwaving ALL their food. No, for my sins it was a French restaurant in London that’s had a Michelin star for a very long time.
These people were absolute pros, at the top of their game. They were all doing highly skilled, specialised operations. From trimming the tops off egg shells for serving Eggs Kayanas to baking tuiles in the shape of olive garlands, everything used was specialist, particularly the knives.
There were no Swiss Army Knives.
I think as data engineers and data practitioners generally, we ought to strive for excellence and think about what we want to do. Do we want to use a Swiss Army Knife for our operations, or do we aspire to do something better? Something at a higher standard, a higher quality?
At Meta, resources are as unlimited as it gets and it’s possible to support a code-first approach towards any problem. In the real world most other people live in, this luxury is not affordable and we substitute software engineering cost for tooling. Tooling is becoming more specialised, more specific, and that unlocks a greater level of quality for our data operations. Using an open-source workflow orchestration package without the required technical and human infrastructure around it is like using a swiss-army-knife to cook a nice meal; you might as well just do something really simple and slap it in the microwave.
🚀If you enjoyed this please consider subscribing to a #dataroundup I do as part of Orchestra, which has other similar and good articles from myself and lots of other great writers in the data space here 🚀