
Why dbt Core™ has to run in an Orchestrator
It is just plain sense that if you're running dbt, you have to be using an Orchestrator

Foreword
Some of the biggest pains we see facing data engineers and analytics engineers is that they spend too much time building infrastructure just to work out what is going on.
Did my pipeline fail? Why did it fail? Did stuff upstream fail? Why did it build these models? Why are there lots of models like this? Can I delete these models because I think they’re all duplicative?
The answer to these problems is to have a control plane for data operations. A little bit similar to the Control Plane in Networking. By doing this, you get a birds-eye view of everything going on in your data stack and can Govern from Day 1. This saves time (debugging), effort (stuff is not duplicative) and resource (don’t need an army of platform engineers).
It’s faster too.
This is why, if you’re building a data team you simply have to have an orchestration platform. As dbt is just pushing down queries to a warehouse, which is pretty much the simplest thing you could possibly orchestrate, that orchestrator has to run dbt as well (see more here).
Now - there are many providers of Cloud IDEs - developer environments for the less technically inclined of us who seem to run into a wall of procrastination and inaction when faced with the Task of downloading VSCode and developing locally. You may think you should be paying for an IDE (A developer environment) that has a deployment environment bundled with it.
I don’t really care if you think buying an IDE is right for you or not - if there are 100 analysts in your company who are ready and waiting to start writing immaculate SQL if they could but have an IDE in the Cloud, then go get em tiger
But when it comes to execution, governance, orchestration, monitoring, metadata etc. you introduce a huge amount of complexity by running basic operations (like SQL Pushdown queries i.e. dbt) outside of your control plane. For example you could, in theory, buy an IDE for your 100 analysts, have them push code to git, and then let Orchestra run your dbt Core for you. Nothing wrong with that.
This is why you need something like Orchestra. Your Orchestrator should be running dbt, parsing the metadata, surfacing it so you can easily identify bottlenecks, monitor costs, and so on. Why? Because it does that anyway, for literally all your other stuff. it is optimised for that. It is just correct.
At Orchestra we’re building a Unified Control Plane for Data Ops for Teams that don’t want, can’t or don’t have the time to build it themselves. With some incredible features to give data teams their time back so they can focus on building. You can try it now, free, here.
Earlier this month we announced support for dbt Core™. This makes Orchestra all you need to start building a Data Stack with all the juicy infrastructure most people leave until too late. Sound interesting? Let’s chat.
Press Release for the dbt Core announcement below
Introduction
Today we are excited to announce support for dbt Core™ in Orchestra. This underpins our commitment to the dbt Community to providing a Unified Control Plane for data operations, especially for teams that leverage data build tool — or “dbt” for short.
This builds on our existing integrations to dbt Cloud™, dbt Core on ECS, and dbt Core on AWS EC2. Now, users can simply import their credentials into Orchestra and leverage dbt commands as Orchestra Tasks.
At Orchestra, our mission is to make Data Teams successful. One of the ways we do this is by minimizing the boilerplate infrastructure and platform integration they need to write and maintain. In addition to the core Orchestration and Observability framework, something we still required our users to do was maintain their own infrastructure for running dbt Core.
With this integration, there is one less job to do and one less resource to manage. This results in more time back for data engineers to focus on building instead of maintaining infrastructure.
The Problem
Data Build Tool or “dbt” is a developer framework for structuring repositories of SQL code. The need for this arises when manually specifying dependencies between hundreds of different SQL models becomes untenable — dbt handles dependencies automatically, which makes this approach highly favourable.
In Production, Data Teams typically require updates to data to run on time or event-based schedules. This means running dbt ( dbt run ) on a time or event-basd schedule.
As dbt is a command-line tool, the infrastructure requirements are not the same as simply needing to run a python script or SQL Query on a schedule. As a result, Data Engineering and Platform Engineering Teams go to great lengths to deploy dbt Core code in various ways: Kubernetes, Airflow on Kubernetes, Prefect on Kubernetes, EC2, ECS, Azure Virtual Machines, Azure Data Factory, and so on and so forth.
In addition to the high platform overhead this takes, debugging dbt Core in this system is complicated. A simple dbt command can nest multiple steps, the materialisation of multiple tables, as well as data quality tests.
Additional work is required to parse dbt artifacts to surface all the relevant metadata (“This test failed on this table with those results returned”) — for want of getting unhelpful messages that require debugging (“Run dbt Daily failed”)

Understanding the Value-Drivers for dbt development
Developing Code is generally done with a (free) desktop-based code editor, such as VS Code. One solution to the problems around lineage, metadata and automated infrastructure management is to purchase a dbt IDE.
With a cloud-based dbt IDE, users don’t need to install VS Code or any other code editor and can instead leverage the Internet-based Development Environment.
While convenient to less technical profiles, many Data Engineers and Analytics Engineers find that they are comfortable developing locally, and threfore may struggle to find an option for running dbt Core on managed infrastructure, where the value exchange makes sense — there is no need to pay for an IDE if you are comfortable developing locally.
Indeed, if we are to implement software best practices, getting comfortable with an industry standard IDE is likely a good place to start. Indeed, 99.999% of software engineers use an IDE in a local (or remote) development environment.
The Ideal place to run dbt Core: your Orchestration Tool
You can run dbt Core code locally, with a Cloud IDE provider, on your own infrastructure, with Orchestra — where should you?
At Orchestra, we believe it should run in your Orchestration Tool, and there is a very simple reason for that. That is because running dbt Core is exactly the same thing as running a Data Pipeline in an Orchestration Tool.
To understand why, we need to examine what dbt is actually doing — push-down queries.

A Push Down Query is executed by a Query Engine. In Data Warehouses, this is often provided by the Data Warehouse Provider (e.g. Snowflake) and is the “Compute” that is referred to in the “Storage vs. Compute” debate.
An Orchestrator does no data processing. It just sends the query to the query engine (“Push-down”). This can be done in a synchronous way, where you await a response from the query engine that says what happened.
Alternatively, it can be done asynchronously, and rather than wait for a response, the query engine should almost immediately return a response with a query id. The Orchestration tool should then poll for the result of the query using the provided query id.
When you execute a dbt command on your laptop, you are running SQL Queries in a Synchronous way. Generally, you would expect a computer to only be able to make so many connections i.e. hang on so many requests, and that’s what the dbt Threads parameter is for.
You can therefore think of running dbt as an Orchestrator, albeit one that is incredibly limited. Having to keep a computer on just to wait for the response from your data warehouse is not efficient.
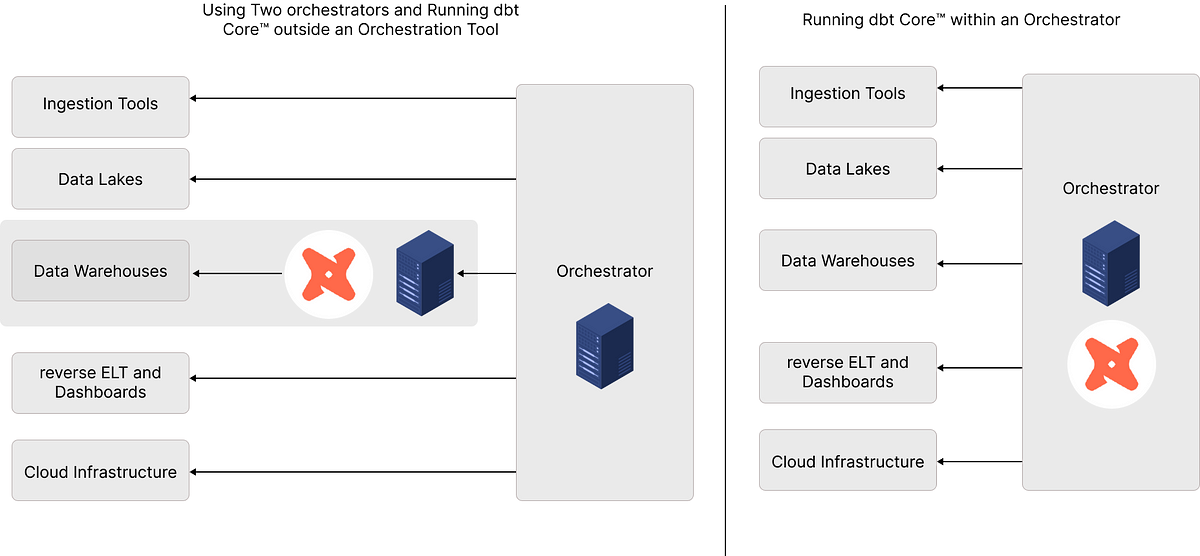
Furthermore, wouldn’t we like to orchestrate more than just warehouse Queries? Wouldn’t we monitor jobs in other SAAS tools, or cloud/on-premise infrastructure? Surely the Orchestrator we Analysts use should be the same as the Data Engineers?
Indeed, every Data and Analytics Team Member requires something to schedule and kick-off tasks, or at least handle the dependencies between tasks (e.g. an SNS Queue between AWS Lambda Functions). Without this, nothing would ever start, and data would never update — this might as well be a fully-featured Orchestration Framework.
This results in cleaner architecture which is simpler to maintain and more cost-effective. This results in more time for Data Teams to focus on building instead of knitting together different pieces of cloud infrastructure.
One Step Further: Governance and Guardrails
In addition to Architectural Desirability and managed infrastructure, there is one other important benefit to running dbt Core™ in Orchestra.
As the dream of Self-Serve BI proliferated, Dashboards died. A high percentage of Dashboards are not used.
To solve this, we empowered those building the dashboards with domain knowledge and tools like dbt to model data too. This lead to the same problem in a different place — too many dbt models, code spaghetti, duplication, and huge drops in analytics velocity.
Indeed, 60% of leaders have prioritised Data Governance and breaking free of the Silo Trap. By running dbt Core in Orchestra, analysts can take advantage of Orchestra’s advanced Role Based Access Control and Governance Features.
Analysts will not be prevented from leveraging dbt and committing dbt Code. However, because Orchestra is a true unified Control Plane, additional levels of Role-based Access Control are required to produce Data Products in Orchestra, and actually run dbt Core™ in Production.
Combining dbt Core™ with Orchestra’s Role-Based Access Control and Governance features can therefore be a way to tame uncontrollable model building.
The benefits to this are enormous — deduplication of work can instantly double a team’s productivity. Less models mean less cost. Implementing a Data Governance process is practically impossible without a Unified Control Plane like Orchestra (traditionally, Data Catalogs), and we would encourage you to get in touch with our partners if that’s something your organisation would benefit from.
Pricing
Orchestra provides fixed pricing and dbt Core™ is no different — your plan will include a fixed number of dbt Core minutes. For 2024, we’re waiving the limit up to 300 minutes per day — just get in touch, mention this article, and we’ll get you set-up.
Your fixed price will be loosely based on overall usage, but there are no complicated materialisation vs. operation run charges, hidden or variable charges. This is part of our commitment to ensure Data Teams get value for money and predictability which helps mitigates financial risk.
Conclusion
We are very excited to continue our commitment to the dbt Community by adding support for dbt Core to Orchestra.
Our hope is that no matter how you choose to run dbt Core, that Orchestra can act as a Genuine Unified Control Plane for Data Operations. By building Data Products with Orchestra, we hope to save time and visibility headaches for Data and Analytics Teams by providing everything they need to build a world-class data stack out the box.
Data Engineers and Analytics Engineers can be proactive instead of reactive, avoid wasting time managing boilerplate infrastructure and painfully debugging data pipelines and manually re-running them. We believe this will help us achieve our mission to make Data Teams successful.
With hundreds of thousands of people empowered to build their own data pipelines with dbt, we’re excited to be able to offer Orchestra as well, which will hopefully be another great step in empowering anyone to become a Citizen Data Engineer.
Find out more about Orchestra
Orchestra is a unified control plane for Data and AI Operations.
We help Data Teams spend less time maintaining infrastructure, make them proactive instead of reactive, and ultimately win trust in data and AI from the Business
We do this by consolidating Orchestration with monitoring, data quality testing, and data discovery. You don’t need an observability, lineage, catalog etc. with Orchestra.
Check out