
A detailed guide to running dbt Core in Production in AWS on ECS
How to run dbt Core as cheaply and reliably as possible on AWS


Note to Substack
Ok so this post is actually written by my Co-Founder Will after he asked me why anyone would want to pay for managed dbt and I said ok if it’s so simple go away and do it.
Well, he actually did and wrote this awesome guide. It’s pretty detailed but on the topic of leadership - the real question you should be asking (and this applies to running python code, or indeed, any code) is whether you should be paying a third party vendor that’s NOT a cloud provider for running your dbt or python…
Note - running dbt in production doesn’t really require lots of compute. It’s your warehouse that’s doing the heavy lifting. In production, dbt is just an orchestrator, and as I’ve written before, orchestration alone should not be expensive.
At least, when you run python, you’re using compute. A simple function that fetches, cleans, and pushes a billion rows should cost you money.
However, it raises the question for Heads of Data and Data Architects around where that compute should be. Should we be running python in Airflow and paying GCP for this via Cloud Composer (which has a mark-up), or should we run python directly in a google cloud function?
Should we pay for managed dbt when a consultancy can set it up on ECS for you for a few hundred bucks and you can then pay AWS directly and thereby run it as cheaply as possible?
You all know what I think! Anyway, if you’re interested in setting up dbt on your own in ECS, read on. If you answer yes to
Are you on AWS? and
Do you pay more than $10k to someone for running your dbt?
Then the article below is a must-read. Enough from me, over to Will…
Introduction
This guide outlines how to run dbt Core on AWS Elastic Container Service (ECS) and how to connect it to the rest of your stack using Orchestra. It includes sections on setting up the required infrastructure, granting required permissions, writing the Dockerfile, and the script to execute the dbt commands.
There are clear and tangible benefits to running dbt Core in ECS. Firstly, ECS is a completely scalable solution and easier to manage than Kubernetes, so for teams without a platform team, this is an incredible option for self-hosting dbt-core with full visibility and control. Secondly, as you run it yourself the compute cost is as low as possible. This makes self-hosting dbt Core in ECS the method of choice for running dbt in production on AWS, provided visibility and lineage can be achieved (which is covered by Orchestra)
By the end of this guide you will have a dbt Core project in production that runs on ECS. Once complete you can use the Orchestra UI to trigger your dbt Core job and monitor its progress. By following this guide you will get dbt Core lineage tracking and data quality checks within the Orchestra platform automatically.
This guide is written using a dbt Project that runs on Google BigQuery. However, the same principles can be applied to any dbt Core project that runs on any dbt adapter.
Sections
Prerequisites
It is assumed you have a basic understanding of dbt Core and AWS services. Before you begin, you will need the following:
An AWS account
A dbt Core project in a git repository
Basic knowledge of Docker, Terraform and Bash scripting (or you can learn that now!)
Setting up the Infrastructure
We configure the infrastructure using Terraform. The infrastructure consists of the following resources:
ECS cluster. Docs here.
ECS task definition.
ECR (Elastic Container Registry) repository. Docs here.
S3 Bucket for storing the dbt Core output artifacts. Docs here.
AWS IAM (Identity Access Management) execute role for the ECS task.
AWS IAM task role for the ECS task.
AWS IAM user for Orchestra to manage the ECS task.
Our task definition is defined in terraform as below:
resource "aws_ecs_task_definition" "dbt_task" {
family = "dbt-task"
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = 256
memory = 512 runtime_platform {
operating_system_family = "LINUX"
cpu_architecture = "ARM64"
} execution_role_arn = aws_iam_role.execute_role.arn task_role_arn = aws_iam_role.task_role_arn container_definitions = jsonencode([
{
name = "dbt-task"
image = "${aws_ecr_repository.dbt.repository_url}:latest"
cpu = 256
memory = 512
essential = true,
environment = [
{
name = "GCP_PROJECT"
value = var.gcp_project
},
{
name = "GCP_BIGQUERY_SCHEMA"
value = var.gcp_schema
},
{
name = "ARTIFACT_BUCKET_NAME"
value = aws_s3_bucket.dbt_artifacts.id
}
],
secrets = [
{
"name" : "SERVICE_ACCOUNT_JSON",
"valueFrom" : "${data.aws_secretsmanager_secret.gcp_dbt_bigquery.arn}"
},
],
logConfiguration = {
logDriver = "awslogs"
options = {
"awslogs-group" = "/ecs/dbt-task"
"awslogs-region" = "eu-west-2"
"awslogs-create-group" = "true"
"awslogs-stream-prefix" = "dbt-task"
}
}
}
]) depends_on = [
aws_ecr_repository.dbt,
aws_s3_bucket.dbt_artifacts,
aws_iam_role.execute_role,
aws_iam_role.task_role
]
}This has several points that are noteworthy:
Orchestra requires all ECS jobs to be configured to run using the
awsvpcnetwork and to use theFARGATEcompatibility modeThe
runtime_platformblock is required to specify the architecture of the ECS task. You can use either x86_64 or ARM64, this is discussed in further detail in the Writing the Dockerfile sectionThe
execution_role_arnandtask_role_arnare the IAM roles that the ECS task will assume. These roles are created in the Granting Required Permissions sectionThe image is defined using the ECR repo URL and the ‘latest’ tag. If deploying this project using CI/CD, you may want to use a specific tag for the image, this allows rollbacks and specific versioning of the dbt Core image
The GCP environment variables are passed to the ECS task using the
environmentblock. These are used by dbt Core to connect to the BigQuery databaseWe use Serivce account JSON to authenticate with GCP. This is passed to the ECS task using the
secretsblock. The secret is stored in AWS Secrets Manager and is retrieved using the AWS secrets manager data sourceIt is recommended to enable logging for your ECS task as it helps debugging any issues you may encounter. This is done using the
logConfigurationblock
Additional Network Configuration
When running an ECS task in an ECS cluster you need to provide a list of Subnet IDs the task can run in and a list of Security Group IDs to control the traffic to and from the task. You can configure separate Subnets and Security Groups, or leverage AWS account defaults. AWS automatically generates a default VPC for each account, with default subnets in each availability zone and a default security group. These defaults are suitable for your ECS task. Refer to the documentation for instructions on creating custom configurations: here.
Granting Required Permissions
Execute Role
AWS provides a managed policy called AmazonECSTaskExecutionRolePolicy that provides the required permissions for ECS to execute the task. Some additional permissions are required to enable our task defintion:
In order for ECS to inject the secret as an environment variable the role requires permissions to read that secret from Secrets Manager, documentation on this can be found here
In order for ECS to output logs to cloudwatch the role requries permissions to write to cloudwatch logs, documentation on this can be found here
We create an IAM role and attach this policy to it. We use a data provider to get the ARN of the AmazonECSTaskExecutionRolePolicy policy, and create our own policy for managing the secrets manager permissions.
# AWS Managed policy for ECS task execution role
data "aws_iam_policy" "ecs_task_execution_role_policy" {
arn = "arn:aws:iam::aws:policy/service-role/AmazonECSTaskExecutionRolePolicy"
}
# AWS Secrets manager policy
data "aws_iam_policy_document" "secrets_manager_policy_doc" {
version = "2012-10-17"
statement {
effect = "Allow"
actions = [
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret"
]
resources = "<SECRET_ARN>"
}
}
resource "aws_iam_policy" "secrets_manager_policy" {
name = "ExecuteRoleSecretsManagerPolicy"
path = "/"
description = "Permissions required by execute role to access secrets manager secret."
policy = data.aws_iam_policy_document.secrets_manager_policy_doc.json
}
# Logging policy
data "aws_iam_policy_document" "ecs_logs_policy_doc" {
version = "2012-10-17"
statement {
effect = "Allow"
actions = [
"logs:PutLogEvents",
"logs:DescribeLogStreams",
"logs:DescribeLogGroups",
"logs:CreateLogStream",
"logs:CreateLogGroup"
]
resources = [
"*"
]
}
}
resource "aws_iam_policy" "ecs_logs_policy" {
name = "ecs_logs_policy"
path = "/"
description = "Permissions for ecs containers to write logs to cloudwatch"
policy = data.aws_iam_policy_document.ecs_logs_policy_doc.json
}
resource "aws_iam_role" "execute_role" {
name = "execute_role"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Sid = ""
Principal = {
Service = "ecs-tasks.amazonaws.com"
}
},
]
})
}
resource "aws_iam_role_policy_attachment" "attach_ecs_task_execution_role_policy" {
role = aws_iam_role.execute_role.name
policy_arn = data.aws_iam_policy.ecs_task_execution_role_policy.arn
}
resource "aws_iam_role_policy_attachment" "attach_secrets_manager_policy" {
role = aws_iam_role.execute_role.name
policy_arn = aws_iam_policy.secrets_manager_policy.arn
}
resource "aws_iam_role_policy_attachment" "attach_ecs_logs_policy" {
role = aws_iam_role.execute_role.name
policy_arn = aws_iam_policy.ecs_logs_policy.arn
}Task Role
The task role is the role that the ECS task assumes when it is running. This role requires permissions to write to the S3 artifacts bucket. We create an IAM role and attach the required policies to it. More information about the permissions the ECS task needs in order to assume the role can be found here.
Note that the AWS account ID is parsed using the data aws_caller_identity provider.
resource "aws_iam_role" "task_role" {
name = "task_role" assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
"Effect" : "Allow",
"Principal" : {
"Service" : [
"ecs-tasks.amazonaws.com"
]
},
"Action" : "sts:AssumeRole",
"Condition" : {
"ArnLike" : {
"aws:SourceArn" : "arn:aws:ecs:eu-west-2:${data.aws_caller_identity.current.account_id}:*"
},
"StringEquals" : {
"aws:SourceAccount" : "${data.aws_caller_identity.current.account_id}"
}
}
}
]
})
}# S3 PutObject permission
data "aws_iam_policy_document" "s3_artifact_policy_doc" {
version = "2012-10-17"
statement {
effect = "Allow"
actions = [
"s3:PutObject"
]
resources = [
"${aws_s3_bucket.dbt_artifacts.arn}/*",
"${aws_s3_bucket.dbt_artifacts.arn}"
]
}
}resource "aws_iam_policy" "s3_artifact_policy" {
name = "S3ArtifactPolicy"
path = "/"
description = "Permissions required by task to write to S3" policy = data.aws_iam_policy_document.s3_artifact_policy_doc.json
}resource "aws_iam_role_policy_attachment" "s3_output_policy_attachment" {
role = aws_iam_role.task_role.name
policy_arn = aws_iam_policy.s3_artifact_policy.arn
}Orchestra User
Orchestra requires an IAM user to manage the ECS task. This user requires the following permissions:
ecs:RunTaskto trigger the ECS taskecs:DescribeTasksto monitor the ECS taskecs:StopTaskto stop the ECS taskecs:DescribeTaskDefinitionto get the task definition. Orchestra uses this to inject the ORCHESTRA_TASK_RUN_ID environment variable into the ECS task. More information on why this is necessary can be found in the Writing the dbt Script sectioniam:PassRoleto pass the task & execute roles to the ECS taskiam:GetRoleto get the task & execute roless3:GetObjectto get the dbt Core output artifacts from the S3 buckets3:ListBucketto list the contents of the S3 bucket
Note: Some of the permissions here can be restricted further by adding stricter resource ARNs. For example, the ecs:RunTask action can be restricted to a specific task definition ARN. This is not done in this example but is recommended for production use.
resource "aws_iam_user" "orchestra_user" {
name = "orchestra_user"
}data "aws_iam_policy_document" "orchestra_policy_doc" {
version = "2012-10-17"
statement {
effect = "Allow"
actions = [
"ecs:RunTask",
"ecs:StopTask",
"ecs:DescribeTasks",
]
resources = [
"arn:aws:ecs:eu-west-2:${data.aws_caller_identity.current.account_id}:task-definition/*",
"arn:aws:ecs:eu-west-2:${data.aws_caller_identity.current.account_id}:task/*/*"
]
} statement {
effect = "Allow"
actions = [
"ecs:DescribeTaskDefinition",
]
resources = ["*"]
} statement {
effect = "Allow"
actions = [
"iam:PassRole",
"iam:GetRole"
]
resources = [
"${aws_iam_role.execute_role.arn}",
"${aws_iam_role.task_role.arn}",
]
} statement {
effect = "Allow"
actions = [
"s3:GetObject",
"s3:ListBucket"
]
resources = [
"${aws_s3_bucket.dbt_artifacts.arn}/*",
"${aws_s3_bucket.dbt_artifacts.arn}"
]
}
}resource "aws_iam_policy" "orchestra_policy" {
name = "orchestra_policy"
description = "Permissions required by Orchestra to manage ECS + dbt Core tasks."
policy = data.aws_iam_policy_document.orchestra_policy_doc.json
}resource "aws_iam_user_policy_attachment" "orchestra_policy_attachment" {
user = aws_iam_user.orchestra_user.name
policy_arn = aws_iam_policy.orchestra_policy.arn
}Writing the Dockerfile
There are many ways to write a Dockefile for running a dbt Core project. In this example we take a slim Python image and install the AWS CLI tools along with installing the required dbt Core packages. We then copy the dbt Core project into the image and set the entrypoint to a script that runs the dbt commands.
Note that in this repository we have put all our dbt files into a sub folder to encourage project separation. This is not necessary and you can put your dbt files in the root of the repository if you prefer.
Instructions on installing the AWS CLI can be found here. It is worth noting that this is built using ARM64 architecture and the instructions will be different if you are building your docker image using x86_64 architecture.
The run_dbt.sh script is discussed in more detail in the Writing the dbt Script section.
# Use an official Python runtime as the base image
FROM python:3.12-slim# Set the working directory in the container
ENV WORKDIR /dbt_core_project
RUN mkdir -p $WORKDIR
WORKDIR $WORKDIR# install AWS CLI and other packages needed for dbt
RUN apt-get update && apt-get install -y \
git-all \
curl \
unzip
RUN curl "https://awscli.amazonaws.com/awscli-exe-linux-aarch64.zip" -o "awscliv2.zip" \
&& unzip awscliv2.zip \
&& ./aws/install \
&& rm -rf awscliv2.zip# Copy the requirements file to the container
COPY ./requirements.txt .# Install the Python dependencies
RUN pip install -r requirements.txt# Copy the dbt project and scripts folder to image
COPY dbt_project dbt_project
COPY scripts scripts# Add execute permissions to the entrypoint script
RUN chmod +x scripts/run_dbt.sh
ENTRYPOINT [ "/bin/sh", "-c" ]
CMD ["scripts/run_dbt.sh"]Configuring the dbt Project
When ECS injects the environment variables into the ECS task, we use these to configure the dbt Core project. In this example we use the GCP_PROJECT and GCP_BIGQUERY_SCHEMA environment variables to configure the dbt Core project. These are used to connect to the BigQuery database and to specify the schema to use.
The Service Account JSON is injected by Secrets Manager as a stringified JSON object. The run_dbt.sh script will parse this JSON and store it in a JSON file. This file is then used by dbt Core to authenticate with GCP.
orchestra_ecs_dbt_bigquery_example:
target: prod
outputs:
prod:
type: bigquery
method: service-account
project: "{{ env_var('GCP_PROJECT') }}"
schema: "{{ env_var('GCP_BIGQUERY_SCHEMA') }}"
threads: 1
keyfile: "{{ env_var('SERVICE_ACCOUNT_JSON_PATH') }}"Writing the dbt Script
The run_dbt.sh script is the entrypoint for the Docker image. It must implement the following requirements:
Executing the dbt Core commands
Uploading the dbt Core output artifacts to the S3 bucket
If a dbt Core fails it should still upload the artifacts to the S3 bucket
Save the GCP Service Account stringified JSON to a file
Perform other setup steps
In the following script notice the following things:
When executing the dbt Core commands we use the
--target-pathflag to specify the output directory. This ensures we do not overwrite the output artifacts from previous runsWe use the
ORCHESTRA_TASK_RUN_IDenvironment variable to create a unique path in the S3 bucket for the dbt Core output artifacts. This is injected by Orchestra and is used to group the dbt Core output artifacts togetherWe use the
$?bash operator to capture the exit code of the dbt Core commands. This allows us to:exit with the correct exit code at the end of the script. Allows Orchestra to determine if the dbt commands failed or succeeded
upload to S3 even if the dbt command fails
When uploading the different
run_results.jsonfiles to S3 we add the suffixes_1and_2to the file names. This is so Orchestra can determine the order the commands where executed and allows for lineage tracking
SERVICE_ACCOUNT_JSON_PATH=/root/service-account.json
# ECS injects the SERVICE_ACCOUNT_JSON as a stringified JSON object
if [ -z "$SERVICE_ACCOUNT_JSON" ]; then
echo "SERVICE_ACCOUNT_JSON is not set"
exit 1
else
# Save the SERVICE_ACCOUNT_JSON to a file
echo $SERVICE_ACCOUNT_JSON > $SERVICE_ACCOUNT_JSON_PATH
# export the SERVICE_ACCOUNT_JSON_PATH so the dbt project can read it
export SERVICE_ACCOUNT_JSON_PATH=$SERVICE_ACCOUNT_JSON_PATH
fiif [ -z "$ARTIFACT_BUCKET_NAME" ]; then
echo "ARTIFACT_BUCKET_NAME is not set"
exit 1
fi
if [ -z "$S3_STORAGE_PREFIX" ]; then
S3_STORAGE_PREFIX="dbt"
fi# Setup and install packages
cd dbt_project
mkdir -p target/run && mkdir -p target/test
dbt deps# Run dbt
dbt run --target-path target/run
RUN_EXIT_CODE=$?# Copy artifacts to S3
aws s3 cp target/run/manifest.json s3://$ARTIFACT_BUCKET_NAME/$S3_STORAGE_PREFIX/$ORCHESTRA_TASK_RUN_ID/run/manifest.json
aws s3 cp target/run/run_results.json s3://$ARTIFACT_BUCKET_NAME/$S3_STORAGE_PREFIX/$ORCHESTRA_TASK_RUN_ID/run/run_results_1.jsonif [ $RUN_EXIT_CODE -ne 0 ]; then
# If run command failed. Exit early
echo "dbt run failed"
exit 1
fi# Run tests
dbt test --target-path target/test
TEST_EXIT_CODE=$?# Copy artifacts to S3
aws s3 cp target/test/manifest.json s3://$ARTIFACT_BUCKET_NAME/$S3_STORAGE_PREFIX/$ORCHESTRA_TASK_RUN_ID/test/manifest.json
aws s3 cp target/test/run_results.json s3://$ARTIFACT_BUCKET_NAME/$S3_STORAGE_PREFIX/$ORCHESTRA_TASK_RUN_ID/test/run_results_2.json# exit with the test exit code
echo "dbt run complete"
exit $TEST_EXIT_CODEPublishing the dbt Core Image
Local Development
Once the Dockerfile and the run_dbt.sh script are written, the next step is to build the Docker image and push it to the ECR repository. This can be done using the AWS CLI tools. The following script will build the image and push it to the ECR repository.
#!/bin/bash
set -e
if [ "$#" -ne 1 ]; then
echo "Usage: $0 <aws_account_id>"
exit 1
fi
AWS_ACCOUNT_ID=$1
AWS_REGION=eu-west-2
docker build \
-t $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/orchestra/dbt:latest \
-f scripts/Dockerfile \
.
aws ecr get-login-password --region $AWS_REGION | docker login --username AWS --password-stdin $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com
docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/orchestra/dbt:latestProduction Environment (CI/CD; not slim CI)
The script above is a good starting point and suitable for development but it is recommended to use a CI/CD tool to build and push the image. This allows for versioning of the image and rollbacks if necessary. Below is a simple example of a GitHub Actions workflow that builds and pushes the image to ECR.
The GitHub Actions workflow file below uses Docker BuildX GitHub action to build with the ARM64 architecture.
It has two variables defined in the GitHub repository secrets: AWS_ROLE and AWS_ACCOUNT_ID. The AWS_ROLE is the role that the GitHub Actions will assume to push the image to ECR. The AWS_ACCOUNT_ID is the AWS account ID where the ECR repository is located. Instructions on how to configure the AWS role can be found here: here. Permissions required will vary based on your specific requirements, but for this guide the role would need permissions to upload the docker image to the ECR repo.
name: Build and Push to ECR
run-name: Builds dbt Core image and pushes to ECR
on:
push:
branches: [main]
permissions:
id-token: write
contents: read
jobs:
build:
name: Build and push (${{ inputs.environment }})
runs-on: ubuntu-latest
environment: production # define your environment credentials in the GitHub repository settings
steps:
- name: Checkout repository code
uses: actions/checkout@v4
with:
ref: ${{ inputs.branch }}
- name: Configure aws credentials
uses: aws-actions/configure-aws-credentials@v4
with:
role-to-assume: ${{ vars.AWS_ROLE }}
role-session-name: github-actions
aws-region: eu-west-2
- name: Setup Docker BuildX
id: buildx
uses: docker/setup-buildx-action@v3
with:
# build with ARM arch to allow extensions in docker image
platforms: linux/arm64
- name: Login to ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v2
- name: Build and push
uses: docker/build-push-action@v5.2.0
with:
push: true
file: ./scripts/Dockerfile
tags: ${{ vars.AWS_ACCOUNT_ID }}.dkr.ecr.eu-west-2.amazonaws.com/dbt:latest
- run: "echo Built image: ${{ vars.AWS_ACCOUNT_ID }}.dkr.ecr.eu-west-2.amazonaws.com/dbt:latestA final step to the CI/CD action would be to modify our Terraform code to accept a docker image tag as a variable. This allows us to deploy a specific version of the dbt Core image to the ECS task. To do this we would then need to modify our GitHub Actions workflow to apply the Terraform code which would then redeploy the ECS task using the new image tag. We leave this as an exercise to the reader!
Optional: triggering in Orchestra
Once the dbt Core image is published to the ECR repository, the next step is to trigger the ECS task in Orchestra. Full documentation for this can be found here.
Create a new AWS ECS integration connection. This needs an Access Key for the Orchestra user you created in the Granting Required Permissions section.
Create a new pipeline. Using Orchestra’s pipeline builder you can configure downstream or upstream tasks, trigger the ECS task on a schedule, and configure Slack/Teams/Email alerting for the pipeline.
Create the ECS task in the pipeline. You will need your ECS cluster name, ECS task definition.

Use the ‘Collect additional metadata’ toggle to configure the ‘dbt Core’ integration. Enter the S3 bucket name and S3 key prefix (in the
run_dbt.shthis defaults to 'dbt' but can be changed to anything you like).Save and run the pipeline.
Navigate to the
Integrationstab in the Orchestra UI.
Monitoring in Orchestra
You can monitor the progress of the pipeline in the Orchestra UI. Once the pipeline has completed navigate to the lineage view to see the dbt Core operations. This displays all the materialisations and tests that were run in the run_dbt.sh script.

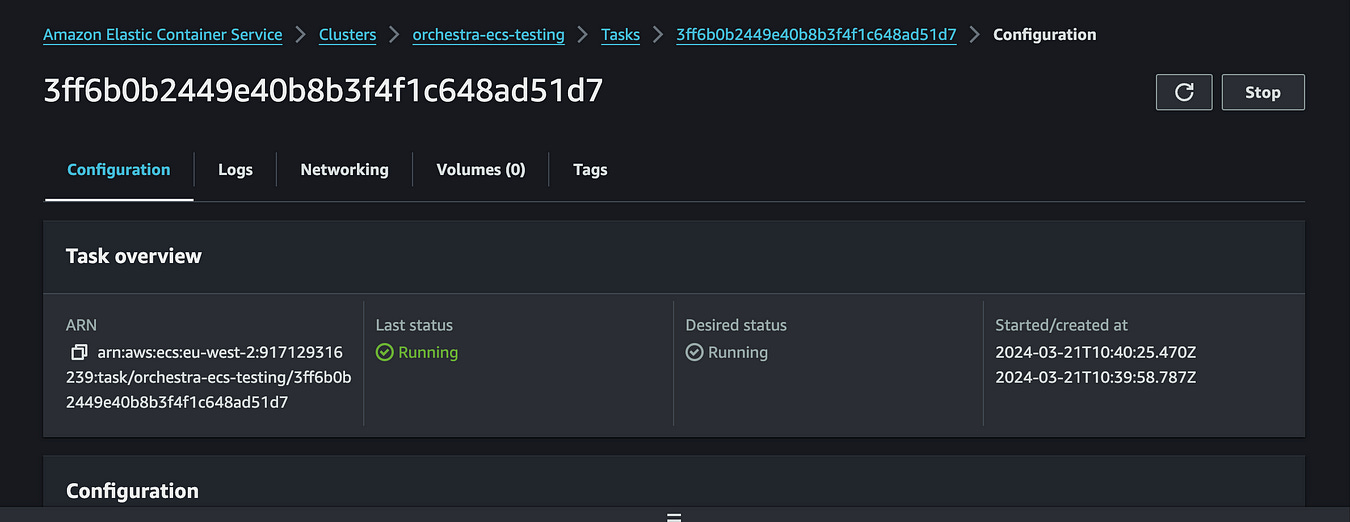
Viewing in AWS Console
You can use the ‘Platform link’ in the Orchestra UI to view your ECS task in the AWS console. This allows you to see the logs, metrics, and other information about the ECS task. Some screenshots are included below detailing this.


Summary
This was my first article on Medium so I really hope you enjyoed it and found it useful! Always happy to talk Platform Engineering to anyone in the data space, so just reach out to me if you’d like to chat. Will
Great article! I noticed GCP was mentioned a couple of times in terms of set-up but could not figure out where the relation was in using it within the overall project?